1.什么是whisper
Whisper 是一个自动语音识别(ASR,Automatic Speech Recognition)系统,OpenAI 通过从网络上收集了 68 万小时的多语言(98 种语言)和多任务(multitask)监督数据对 Whisper 进行了训练。OpenAI 认为使用这样一个庞大而多样的数据集,可以提高对口音、背景噪音和技术术语的识别能力。除了可以用于语音识别,Whisper 还能实现多种语言的转录,以及将这些语言翻译成英语。
本文主要拿该模型做一个音频识别的任务,将视频中的音频转化为文字。
2.项目介绍
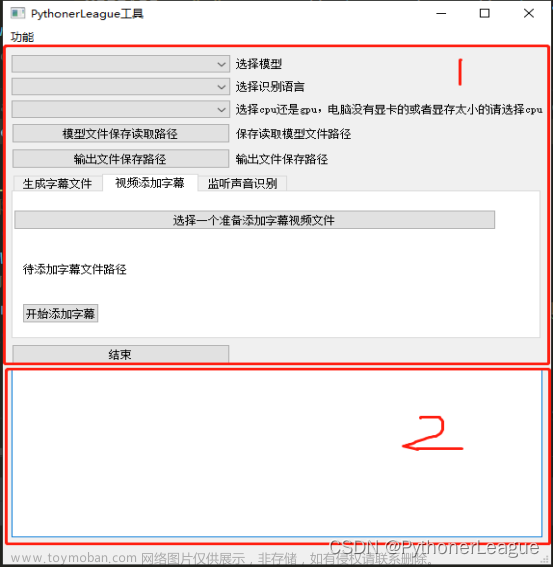
主要实现了一个基于Whisper的视频字幕生成工具,具体来说,采用Flask轻量级WEB应用框架实现一个以python为后端,以html为前端的WEB项目,功能比较简单,即为为无字幕的视频添加字幕(仅支持中文、英文、中英文混杂)
网站如图:
操作起来比较简单,点击上传文件按钮上传本地视频文件(mp4或者avi),然后点击提交文件按钮,后端就开始处理。(暂时还未实现前端可视化处理过程)
实现效果:
中文:
英文:
中英文混杂:
这样看效果还可以吧。
3.项目安装
安装项目所需要的python环境
首先python版本必须要3.9以上,否则会报错,其余python的依赖包在项目中的requirements.txt中都有涉及,直接在python3.9的环境下执行:
pip install git+https://github.com/openai/whisper.git
pip install -r requirements.txt
安装imagemagick
- windows
https://www.imagemagick.org/script/download.php#windows
安装时选择Install development headers and libraries for C and C++。
安装好之后打开python虚拟环境的moviepy模块下的config_defaults.py文件,修改其中的IMAGEMAGICK_BINARY为imagemagick安装文件夹处的magick.exe地址,如:
IMAGEMAGICK_BINARY = r"D:\python_study_tools\ImageMagick-7.0.9-Q16\magick.exe"
若忘记了安装位置,使用everything来找到相应的位置,其中moviepy一定要是你的虚拟环境的moviepy。
- ubuntu
使用指令安装:
apt-get install imagemagick
若报错,更新一下:
apt-get update
然后输入指令:
vim /etc/ImageMagick-6/policy.xml
将
<policy domain="path" rights="none" pattern="@*" />
改成
<!-- <policy domain="path" rights="none" pattern="@*" /> -->
保存退出即可
修改addSubtitles.py中的font格式
在line68
txt = (TextClip(sentences, fontsize=32,
font='SimHei', size=(w-20, 40),
align='center', color='white')
.set_position((10, h - 80))
.set_duration(span)
.set_start(start))
其中的font,该代码在windows正常能执行,没问题。
在ubuntu下报错,因为ubuntu下缺少很多中文类的字节编码,如果这个地方不改,最后出来的视频字幕全是乱码和问号,解决方法:
apt-get install ttf-mscorefonts-installer
apt-get install fontconfig
cd /usr/share/fonts
然后从你的windows中选一个中文字体格式放在这个文件夹下
windows字体文件所在处:C:\Windows\Fonts
然后执行指令:
mkfontscale
mkfontdir
fc-cache -fv
最后将上面addSubtitles.py中的font改成字体的路径就行了。
4.运行项目
在windows或者ubuntu下,打开项目文件,执行app.py文件就行了。在windows上,直接点击那个链接即可;
在服务器上,需要在main函数的app.run()里定义地址与端口,ip地址设为’0.0.0.0’,
在宿主机上运行,需要在浏览器中输入公网ip(关掉梯子)才能访问,自动生成的链接是私网。
若在服务器的docker中运行,在创建docker的时候就要设置好端口映射,若为租的网络服务器,还要去看你的网络服务器开放了哪些tcp端口,随意设置端口还是无法访问。
5.目前存在的问题
- 项目在服务器运行,总是运行一段时间后,该进程会被自动kill,因此通过那个ip地址访问并上传文件后,点击提交文件会报错
- 这个项目并没有实现多线程并发,因此同时有多个用户访问的时候,后端一定会无法得到正确的文件名而报错
- 租的华为云的服务器是最小规格的一核服务器,处理速度很慢,承载力很差,很容易崩溃
- whisper模型还有很多其他的功能,比如直接语音识别、识别视频中的音频并生成文本文件、语音翻译等功能,网站的功能量还可以继续拓展
- 前端的下载功能存在缺陷,对于不同的文件下载没有设置不同的链接
- 字幕和视频合成完全依靠CPU,因此如果视频时长比较长,要跑很久的时候,有时候还没跑完网页就崩溃了,因此不仅是后端的处理和前端的设计都有优化的地方
github项目地址:https://github.com/jiangduwang/addSubtitles.git
网页地址:http://124.70.200.133/
这个网页不保证正在运行,就算运行了也很有可能提交文件的时候出错。
为什么说是持续更新呢,因为完成了眼前的课程任务,我会继续解决这些问题。文章来源:https://www.toymoban.com/news/detail-779568.html
2024.1.3更新
目前忙于毕业小论文和找工作,预计在25年这个时间开始更新工作。文章来源地址https://www.toymoban.com/news/detail-779568.html
到了这里,关于基于whisper模型的在线添加视频字幕网站(持续更新)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!