基于Linux的Hadoop伪分布式安装
1. hadoop用户设置
1.1 创建新用户(需注意权限问题:切换为root用户)
su root

1.2 添加新用户hadoop,并设置相关信息(一直回车默认就可以)
adduser hadoop

1.3 退出当前用户登录hadoop用户(或直接在Ubuntu中切换用户即可)

1.4 以管理员身份(root用户)执行指令visudo,来修改配置
su root

visudo


visudo打开的是
/etc/sudoers文件,修改该文件,在root ALL=(ALL:ALL) ALL这一行下面加入一行:
hadoop ALL=(ALL:ALL) ALL
CTRL+O(然后再按ENTER)保存,CTRL+C取消,CTRL+X退出
1.5 退出root用户
exit

2. 安装ssh
2.1 更新apt源(以免后续安装软件失败)
sudo apt-get update

2.2 安装ssh服务端
sudo apt-get install openssh-server



2.3 安装后使用以下命令登录本机:输入yes、输入密码即可登录
ssh localhost

2.4 输入exit退出ssh
exit

2.5 配置ssh免密登录
- 进入ssh目录:
cd ~/.ssh/
- 会有提示,都按回车就可以:
ssh-keygen -t rsa
- 将密钥加入到授权中:
cat id_rsa.pub >> authorized_keys

2.6 使用 ssh localhost 试试是否能直接登录

3. 安装vim
执行如下命令下载并安装vim:
sudo apt-get install vim



4. 安装JDK并配置环境变量
4.1 安装openjdk-8-jdk
sudo apt-get install openjdk-8-jdk

4.2 查看Java版本,看看是否安装成功
java -version

4.3 将JDK安装路径改为上述命令得到的路径,并保存(也可以使用vim编辑)
gedit ~/.bashrc

export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH

4.4 让该环境变量生效,执行如下命令
source ~/.bashrc

4.5 查看是否是自己安装的Java路径以及对应的版本
echo $JAVA_HOME
java -version
whereis java

5. 安装Hadoop
5.1 下载hadoop
hadoop下载网址:https://hadoop.apache.org/releases.html (速度较慢)
可以使用这个网址:http://archive.apache.org/dist/hadoop/core/hadoop-3.2.4/ (可以选择需要的版本)

5.2 解压(在你想安装的路径下进行解压,这里选择将hadoop安装到 /usr/local 中
sudo tar -zxf ~/下载/hadoop-3.2.4.tar.gz -C /usr/local

5.3 进入该文件夹,将文件夹名为hadoop
cd /usr/local/
sudo mv ./hadoop-3.2.4/ ./hadoop

5.4 修改文件权限
sudo chown -R hadoop ./hadoop

5.5 配置环境变量
gedit ~/.bashrc

#HADOOP VARIABLES START
export HADOOP_INSTALL=/usr/local/hadoop
export PATH=$PATH:$HADOOP_INSTALL/bin
export PATH=$PATH:$HADOOP_INSTALL/sbin
export HADOOP_MAPRED_HOME=$HADOOP_INSTALL
export HADOOP_COMMON_HOME=$HADOOP_INSTALL
export HADOOP_HDFS_HOME=$HADOOP_INSTALL
export YARN_HOME=$HADOOP_INSTALL
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_INSTALL/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_INSTALL/lib"
#HADOOP VARIABLES END

5.6 执行如下代码使其生效
source ~/.bashrc

5.7 可以用如下命令查看解压的hadoop是否是可用的
hadoop version

若如上图所示,hadoop已安装完成!
6. hadoop伪分布式配置

6.1 配置 hadoop-env.sh
gedit ./etc/hadoop/hadoop-env.sh

# The java implementation to use.
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export HADOOP=/usr/local/hadoop
export PATH=$PATH:/usr/local/hadoop/bin

6.2 配置 yarn-env.sh
gedit ./etc/hadoop/yarn-env.sh

# export JAVA_HOME
JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64

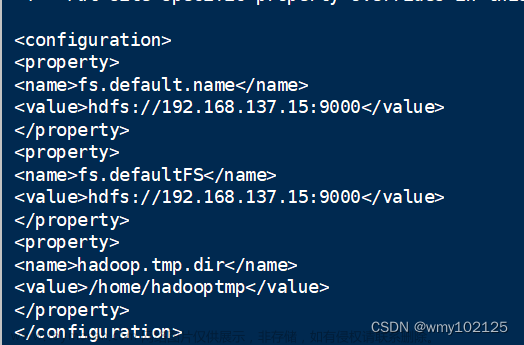
6.3 配置 core-site.xml
gedit ./etc/hadoop/core-site.xml

<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>

6.4 配置 hdfs-site.xml
gedit ./etc/hadoop/hdfs-site.xml

<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>

6.5 配置 yarn-site.xml
gedit ./etc/hadoop/yarn-site.xml

<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>127.0.0.1:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>127.0.0.1:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>127.0.0.1:8031</value>
</property>
</configuration>

6.6 重启Ubuntu系统,验证Hadoop是否安装成功
hadoop version

7. 启动HDFS伪分布式模式
7.1 格式化namenode
hdfs namenode -format


7.2 启动hdfs
start-all.sh

7.3 显示进程(有6个进程表示正常)
jps

7.4 打开浏览器
输入:http://localhost:9870/

输入:http://localhost:8088/文章来源:https://www.toymoban.com/news/detail-779999.html
 文章来源地址https://www.toymoban.com/news/detail-779999.html
文章来源地址https://www.toymoban.com/news/detail-779999.html
到了这里,关于基于Linux的Hadoop伪分布式安装的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!