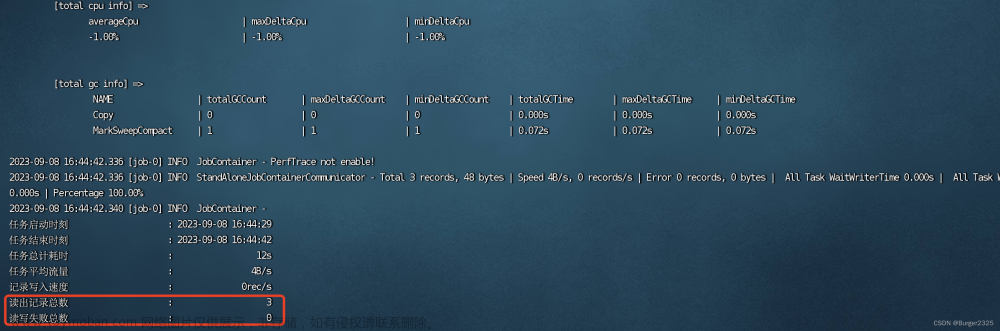
DataX同步达梦数据到HDFS
1、 前提条件
- 安装达梦数据库客户端
- 安装Python3.5 以上
- 导入dmPython模块
导入dmPython流程
- 在达梦数据库客户端
\drivers\python\dmPython这个路径下执行
python setup.py install
● 如果报错在PATH中加入E:\dmdbms\bin 达梦数据库的安装路径,并重新装载dmPython
Traceback (most recent call last):
File "setup.py", line 103, in
raise DistutilsSetupError("cannot locate an Dameng software " /
distutils.errors.DistutilsSetupError: cannot locate an Dameng software installation
● 如果报下面错误则需要自己下载Microsoft Visual C++ 14.0
error: Microsoft Visual C++ 14.0 is required. Get it with "Mi
- 在命令行里 输入
impot dmPython
1. impot dmPython
报错 :ImportError: DLL load failed while importing dmPython: 找不到指定的模块。
2. import sys
sys.path
在末尾等到C:\\Users\\lee\\AppData\\Local\\Pro
Python38\\lib\\site-packages\\dmpython-2.3-py3.8-win-amd64.egg
这个路径
3. 将达梦数据库安装目录下 E:\dmdbms\drivers\dpi下的所有文件,
拷贝到sys.path的最后一个目录下面,再次导入import dmPython成功
2、 生成Job脚本
# ecoding=utf-8
import json
import getopt
import os
import sys
import dmPython
#DM相关配置,需根据实际情况作出修改
DM_host = "124.**.**.249"
DM_port = "5**6"
DM_user = "MES_****_**_SP"
DM_passwd = "*******"
#HDFS NameNode相关配置,需根据实际情况作出修改
hdfs_nn_host = "pt101"
hdfs_nn_port = "8020"
#生成配置文件的目标路径,可根据实际情况作出修改
output_path = "D:/"
def get_connection():
return dmPython.connect(user=DM_user, password=DM_passwd, host=DM_host, port=int(DM_port))
def get_DM_meta(owner, table):
connection = get_connection()
cursor = connection.cursor()
DMsql="SELECT COLUMN_NAME,DATA_TYPE FROM table_name WHERE owner="+"'"+owner+"'"+" AND TABLE_NAME="+"'"+table+"'"
cursor.execute(DMsql)
fetchall = cursor.fetchall()
cursor.close()
connection.close()
return fetchall
def get_DM_columns(owner, table):
return list(map(lambda x: x[0], get_DM_meta(owner, table)))
def get_hive_columns(owner, table):
def type_mapping(dm_type):
mappings = {
"NUMBER": "string",
"INT": "int",
"BLOB": "string",
"CLOB": "string",
"BIGINT": "bigint",
"DOUBLE": "double",
"FLOAT": "float",
"TEXT": "string",
"VARCHAR2": "string",
"VARCHAR": "string",
"TINYINT": "tinyint",
"CHAR": "char",
"TIMESTAMP": "string",
"DECIMAL": "string",
"DATETIME": "string",
"DATE": "string",
"SMALLINT": "smallint",
"BIT": "boolean",
"DEC": "string"
}
return mappings[dm_type]
meta = get_DM_meta(owner, table)
json.dumps(list(map(lambda x: {"name": x[0], "type": type_mapping(x[1].lower())}, get_DM_meta(owner, table)))))
return list(map(lambda x: {"name": x[0], "type": type_mapping(x[1])}, meta))
def generate_json(owner, source_database, source_table):
job = {
"job": {
"setting": {
"speed": {
"channel": 3
},
"errorLimit": {
"record": 0,
"percentage": 0.02
}
},
"content": [{
"reader": {
"name": "rdbmsreader",
"parameter": {
"username": DM_user,
"password": DM_passwd,
"column": get_DM_columns(owner, source_table),
"splitPk": "",
"connection": [{
"table": [source_database+"."+source_table],
"jdbcUrl": ["jdbc:dm://" + DM_host + ":" + DM_port + "/" + source_database]
}]
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"defaultFS": "hdfs://" + hdfs_nn_host + ":" + hdfs_nn_port,
"fileType": "text",
"path": "${targetdir}${system.biz.date}",
"fileName": source_table,
"column": get_hive_columns(owner, source_table),
"writeMode": "append",
"fieldDelimiter": "\t",
"compress": "gzip"
}
}
}]
}
}
if not os.path.exists(output_path):
os.makedirs(output_path)
with open(os.path.join(output_path, ".".join([source_database, source_table, "json"])), "w") as f:
json.dump(job, f)
def main(args):
owner = ""
source_database = ""
source_table = ""
options, arguments = getopt.getopt(args, '-u:-d:-t:', ['owner=', 'sourcedb=', 'sourcetbl='])
for opt_name, opt_value in options:
if opt_name in ('-u', '--owner'):
owner = opt_value
if opt_name in ('-d', '--sourcedb'):
source_database = opt_value
if opt_name in ('-t', '--sourcetbl'):
source_table = opt_value
generate_json(owner,source_database, source_table)
if __name__ == '__main__':
main(sys.argv[1:])
3、 通过命令生成Job文章来源:https://www.toymoban.com/news/detail-780108.html
python data_platform_datax_import_config.py -u user -d datebase-t table
4、启动DataX进行数据传输文章来源地址https://www.toymoban.com/news/detail-780108.html
- 将Job上传在DataX的job目录下
- 提前创建好文件夹
hadoop fs -mkdir -p /origin_data/datebase/table/2023-05-05
- 使用命令执行DataX
python /opt/module/datax/bin/datax.py -p"-Dtargetdir=/origin_data/datebase/table/2023-05-05" /opt/module/datax/job/路径/脚本名称.json
到了这里,关于DataX同步达梦数据到HDFS的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!