🔝🔝🔝🔝🔝🔝🔝🔝🔝🔝🔝🔝🔝🔝🔝🔝🔝
🥰 博客首页:knighthood2001
😗 欢迎点赞👍评论🗨️
❤️ 热爱python,期待与大家一同进步成长!!❤️
前言
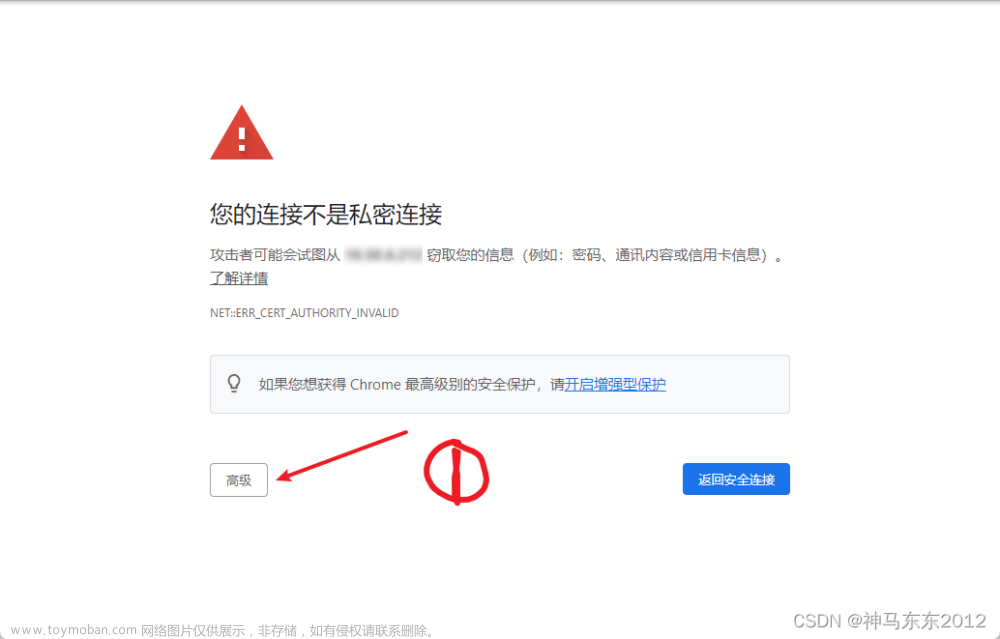
之前笔者对selenium的印象是它对于不需要登陆的网址来讲,操作确实是很棒,而对于需要登录的网址,除了自己扫码或者找到账号、密码控件并输入、点击登录按钮登录等方法,其总是需要多出这一步来,此外,对于很多网址来说,不能多次重复这样,否则会登录不上(就拿登录csdn私信来说,账号密码登录短时间只能登录一次,否则就会出现下图所示的内容,滑动滑块也没用)。


有时通过selenium打开网站时,发现有些网站需要扫码登录,就很头疼,导致后续进展不下去。
最近在使用uiautomation操作浏览器的时候,打开浏览器不需要像selenium一样要先登录,不过对于后续操作,uiautomation的使用就显得不是非常方便,因此后续仍需要回到selenium。
因此最终的问题就是,如何让selenium操作已经打开的浏览器以及网址。
之前也发现过这些,但是那时候觉得麻烦,没有尝试,现在发现当时的自己是多么愚蠢。现在重新看相关的文章,发现步骤非常简单。
方法一
import os
import subprocess
# 先切换到chrome可执行文件的路径
os.chdir(r"C:\Program Files\Google\Chrome\Application")
# user-data-dir为路径
subprocess.Popen('chrome.exe --remote-debugging-port=9527 --user-data-dir="D:\selenium\AutomationProfile"')

from selenium import webdriver
from selenium.webdriver.chrome.options import Options
options = Options()
options.add_experimental_option("debuggerAddress", "127.0.0.1:9527")
driver = webdriver.Chrome(options=options)
print(driver.title)chrome路径在chrome图标右键查看文件位置可以找到,一般在
C:\Program Files\Google\Chrome\Applicationuser-data-dir为你想要保存的路径
以上方法每次使用代码都需要写,比较麻烦,因此可以尝试方法二
方法二

打开chrome属性,其目标写着
"C:\Program Files\Google\Chrome\Application\chrome.exe"
我们需要在后面加上(--remote前面有个空格)
--remote-debugging-port=9527 --user-data-dir="D:\selenium\AutomationProfile"
即目标里面的内容如下
"C:\Program Files\Google\Chrome\Application\chrome.exe" --remote-debugging-port=9527 --user-data-dir="D:\selenium\AutomationProfile"其中的9527为端口号,可以自己更改
--user-data-dir指定运行浏览器的运行数据,新建一个干净目录,不影响系统原来的数据

更改好后,点击确定,然后会弹出需要管理员授权方面的信息,点确认即可。
然后,你的谷歌

就变这样了,所以进行这步操作前,首先记住你的书签(还好我之前的网页还存在一个,不然对于我这样的菜鸡,应该找不回来了)


在D盘的文件夹下面,多出来很多文件。
接下来直接使用代码即可
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
options = Options()
options.add_experimental_option("debuggerAddress", "127.0.0.1:9527")
driver = webdriver.Chrome(options=options)
print(driver.title)实例:
在csdn搜索框中输入22222
import time
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
options = Options()
options.add_experimental_option("debuggerAddress", "127.0.0.1:9527")
driver = webdriver.Chrome(options=options)
print(driver.title)
xpath = '//*[@id="toolbar-search-input"]'
driver.find_element(by=By.XPATH, value=xpath).send_keys('222222')

小插曲
本来笔者怕这个可以使用后,就把之前selenium每次操作都会打开一个浏览器给搞冲突了
然后自己就去尝试了,当时的代码如下:
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
url = 'https://www.baidu.com'
driver = webdriver.chrome()
driver.get(url)
print(driver.title)

然后发现还真报错了,这给我紧张的,过了好久才发现
原因是:我的Chrome()写成chrome()了,结果仅仅是这一个字母大小写的差别。
所以写代码一定要小心仔细。文章来源:https://www.toymoban.com/news/detail-780622.html
总结
完成以上操作后,以后selenium争对需要登陆的网址会变得友好多了。以后很多东西都能继续搞下去了😀😀😀,其使用频率就会上来了。文章来源地址https://www.toymoban.com/news/detail-780622.html
到了这里,关于Selenium操作已经打开的Chrome(只怪自己尝试的太迟)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!