一、Rest风格说明(非常重要)
Rest风格一种软件架构风格,而不是标准,只是提供了一组设计原则和约束条件。 它主要用于客户端和服务器交互类的软件。基于这个风格设计的软件可以更简洁,更有层次,更易于实现缓存等机制。
基于Rest命令说明
| method | url地址 | 描述 |
|---|---|---|
| PUT | localhost:9200/索引名称/类型名称/文档id | 创建文档(指定文档id) |
| POST | localhost:9200/索引名称/类型名称 | 创建文档(随机文档id) |
| POST | localhost:9200/索引名称/类型名称/文档id/_update | 修改文档 |
| DELETE | localhost:9200/索引名称/类型名称/文档id | 删除文档 |
| GET | localhost:9200/索引名称/类型名称/文档id | 查询文档通过文档id |
| POST | localhost:9200/索引名称/类型名称/_search | 查询所有数据 |
二、删除索引图形化操作


三、创建索引
- 创建一个索引
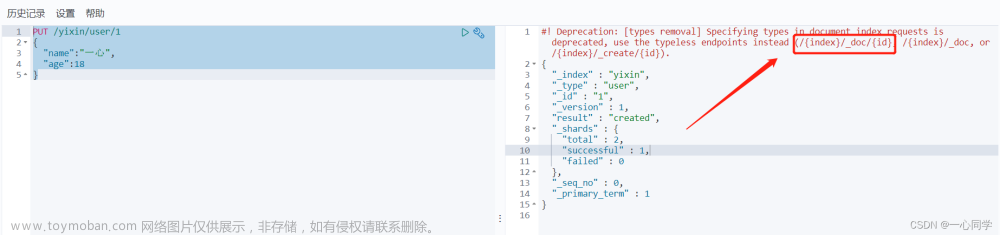
PUT /索引名/类型名/文档id(数据)
{
请求体
}
下图执行信息显示:
_index:索引名
_type:类型名
_id:文档id
完成了自动增加了索引!,数据也成功的添加了,这就是学习初期把它理解为数据库的原因。
-
点击数据浏览——》选择相应的索引

四、指定字段的类型
| 类型分类 | 字段类型 |
|---|---|
| 字符串 | text、keyword |
| 数值 | long、integer、short、byte、double、float、half、scaled、float |
| 日期 | date |
| 布尔值 | boolean |
| 二进制 | binary |
| … | … |
下图是创建索引,定义数据的类型
mappings: 定义个类型
properties:自定属性

五、根据上面的规则,使用GET请求

六、查看默认的文档信息
-
类型(type)默认就是一个_doc


- 自己的文档字段没有指定,那么ES就会给我们默认配置字段类型
例如下图中只是添加了数据,但是没有指定数据类型
七、扩展:_cat
通过命令查看elasticsearch索引情况,通过get _cat可以获得ES当前很多信息
八、修改文档信息(put或者post) 提交还是PUT即可,然后覆盖
-
使用PUT进行修改
put可以添加也可以进行修改,但是在修改的如果是部分修改,会将没有修改的值置空。同时修改的版本号也会改变由1变成了N.

-
POST修改
格式:post/索引/文档/数据库/_updatepost修改可以实现部分修改

九、删除索引
delete 索引 //直接删除整个索引delete /索引名称/类型名称/文档id 删除索引下的某一个文档
-
删除索引


-
添加一条文档,并删除它

十、关于文档的基本操作(重点)
- 使用PUT增加数据
PUT /ceshi/user/1
{
"name" : "款神说",
"age": 23,
"desc":"易擦偶偶你世纪东方流口水京东方",
"tags":["技术宅","温暖", "直男"]
}
PUT /ceshi/user/2
{
"name" : "张三",
"age": 23,
"desc":"法外",
"tags":["游戏","交友"]
}
PUT /ceshi/user/3
{
"name" : "历史",
"age": 23,
"desc":"爱笑",
"tags":["机车","交友"]
}

- 获取索引库中的某一条文档数据

- 更新数据 (不是完整的会将其它值置空)
PUT /ceshi/user/1
{
"name": "王五"
}

- post方式修改(可以想改哪个改哪个)
POST /ceshi/user/1/_update
{
"doc": { //这块需要指定为doc
"name" : "孙悟空"
}
}
- 简单地搜索
格式:get 索引/类型/文档?q=字段名:值…
或者 post 索引/类型/文档?q=字段名:值…
POST /ceshi/user/_search?q=age:23
POST /ceshi/user/_search?q=name:张三
GET /ceshi/user/_search?q=name:张三
name类型是keyword,整体搜索
十一、复杂查询
复杂操作搜索select(排序、分页、高亮、模糊查询、精准查询)
-
score 值越高匹配程度越大


-
模糊查询
- 查询的参数体是JSON结构
GET /ceshi/user/_search
{
"query": {
"match": {
"name": "张三"
}
}
}
-
Hits对应Java中的hit对象
hit中由索引和文档的信息、查询的结果总数、然后就是查询出来的具体的文档,数据中的东西都可以遍历出来。分数:可以判断更加符合预期的结果
-
筛选指定字段
GET /ceshi/user/_search
{
"query": {
"match": {
"name": "张三"
}
},
"_source": ["name","age"] //筛选指定字段
}
- 排序
GET /ceshi/user/_search
{
"query": {
"match": {
"name": "张三"
}
},
"_source": ["name","age"],
"sort": [
{
"_id": { //filed修改为指定字段
"order": "asc" //排序方式为desc或者asc
}
}
]
}
- 分页
数据下标从0开始
GET /ceshi/user/_search
{
"query": {
"match": {
"name": "张三"
}
},
"_source": ["name", "age"]
,"sort": [
{
"_id": {
"order": "desc"
}
}
]
,"from": 0 //分页从0开始
,"size": 2 //每页大小为2
}
- 布尔值查询
must (and),所有的条件都要符合, where id =1 and name =XXX
6 should(or),所有的条件都要符合, where id =1 or name =XXX
- must_not(not),所有的条件都要符合, where age != XXX

- 过滤器(可以使用多个条件查询)
filter 相当于 > < >= <=
gt 表示大于
lt 表示小于
gte 表示大于等于
lte 表示小于等于

- 匹配多个条件
多个条件使用空格隔开就好,只要满足其中一个结过就可以被查出,这个时候可以通过分值进行基本判断
- 精确查询
term查询是直接通过倒排索引指定的词条进行精确查找的。
关于分词:
- term,直接查询精确的
- match,会使用分词器解析!(先分析文档,然后再通过分析的文档进行查询)
-
两个类型keyword text
keyword 全词匹配
text 会进行拆分



中文使用ik分词器

term 解析
PUT testdb
{
"mappings": {
"properties": {
"name": {
"type": "text"
},
"desc": {
"type": "keyword"
}
}
}
}
PUT testdb/_doc/1
{
"name":"狂神说Java name",
"desc": "狂神说Java desc"
}
PUT testdb/_doc/2
{
"name":"狂神说Java name",
"desc": "狂神说Java desc2"
}
GET _analyze
{
"analyzer": "keyword"
,"text":"狂神说Java name"
}
GET _analyze
{
"analyzer": "standard",
"text": "狂神说Java name"
}
GET testdb/_search
{
"query": {
"term": {
"name": {
"value": "狂"
}
}
}
}
GET testdb/_search
{
"query": {
"term": {
"desc" : {
"value": "狂神说Java desc"
}
}
}
}
GET testdb/_search
{
"query": {
"term": {
"desc" : "狂神说Java desc"
}
}
}
GET testdb/_search
{
"query": {
"match": {
"name": "狂 "
}
}
}
GET testdb/_search
{
"query": {
"match": {
"desc": "狂神说Java desc"
}
}
}

- 高亮查询
搜索相关的结果可以高亮显示
在自定义高亮标签 文章来源:https://www.toymoban.com/news/detail-780738.html
文章来源:https://www.toymoban.com/news/detail-780738.html
总结
这些其实mysql也可以,但是比较慢文章来源地址https://www.toymoban.com/news/detail-780738.html
- 匹配
- 按条件匹配
- 精确匹配
- 区间范围匹配
- 匹配字段过滤
- 多条件查询
- 高亮查询
- 倒排索引
到了这里,关于Elasticsearch(四)——ES基本操作的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!