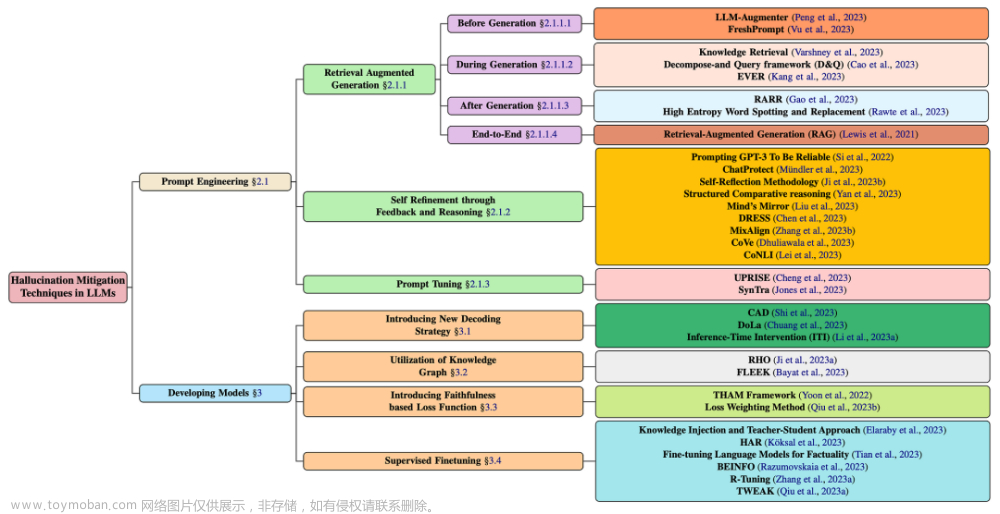
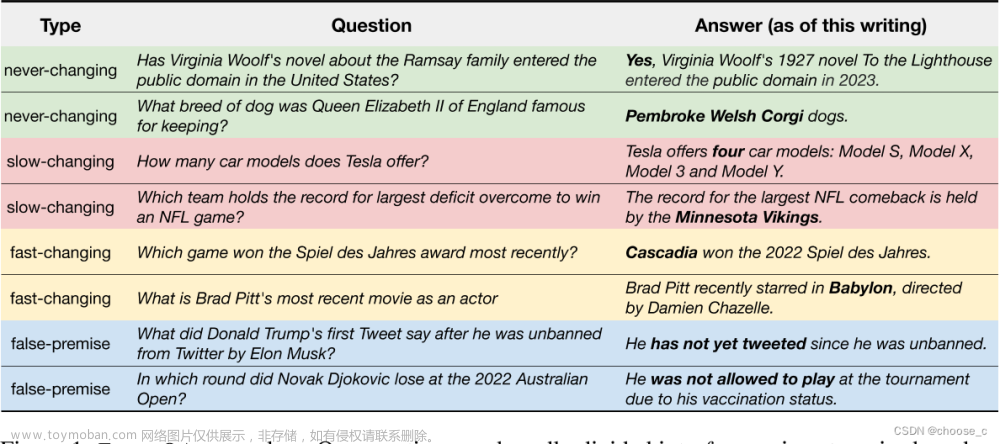
LLM幻觉问题是什么?
LLM(大型语言模型)幻觉问题指的是当大型语言模型(如我这样的)在处理请求时产生的不准确或虚构的信息。这些幻觉可能是因为模型的训练数据不足、错误或偏见,或者是因为模型在处理某些特定类型的问题时的局限性。具体来说,这些问题可能包括:
- 生成虚假或不准确的信息:模型可能会生成与现实不符或完全虚构的答案。
- 过度自信:即使提供的信息不准确或虚假,模型也可能表现出过度的自信。
- 重复或矛盾:在回答中可能出现重复或相互矛盾的信息。
- 偏见:模型的回答可能受到其训练数据中存在的偏见的影响。
- 理解问题:对复杂或含糊不清的问题理解不足。
如何解决LLM幻觉问题?
解决LLM(大型语言模型)幻觉问题需要多方面的努力,包括技术改进、用户教育和持续的监督。以下是一些关键策略:
-
改进训练数据:确保训练数据的质量和多样性,减少偏见和错误信息。包括更广泛和多元化的数据可以帮助模型更好地理解和反映现实世界。
-
持续迭代和更新:定期更新模型,以纳入最新的数据和研究成果,以及解决已知的问题。
-
增强模型的理解能力:通过改进算法和结构,提高模型处理复杂和模糊问题的能力。
-
实施更严格的测试和验证:在模型发布前进行彻底的测试,以识别和纠正潜在的问题。
-
用户教育:教育用户理解模型的潜在局限性和正确使用方式,以减少误解和错误使用。
-
透明度和解释性:提供关于模型如何工作和做出决策的更多信息,帮助用户理解和评估模型输出。
-
用户反馈和监督:鼓励用户提供反馈,以便及时发现和纠正问题。
-
伦理和合规性考虑:确保模型的开发和使用符合伦理和法律标准,特别是在隐私和数据保护方面。
-
跨学科合作:在模型的开发和评估过程中融入跨学科的专业知识,例如语言学、社会学和伦理学。文章来源:https://www.toymoban.com/news/detail-781306.html
通过这些方法,可以减少LLM产生幻觉的风险,并提高其在各种应用中的可靠性和有效性。文章来源地址https://www.toymoban.com/news/detail-781306.html
到了这里,关于如何解决LLM(大型语言模型)幻觉问题的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!