一、实验主题
缓冲区溢出被定义为程序试图将数据写入缓冲区边界之外的情况。恶意用户可以利用此漏洞更改程序的流控制,从而导致恶意代码的执行。本实验的目的是让学生对这种类型的漏洞有实际的了解,并学习如何利用攻击中的漏洞。
在这个实验中,学生将得到四个不同的服务器,每个服务器运行一个具有缓冲区溢出漏洞的程序。他们的任务是开发一种利用该漏洞的方案,并最终获得这些服务器上的根权限。除了攻击之外,学生还将尝试几种对抗缓冲区溢出攻击的对策。学生需要评估这些方案是否有效,并解释原因。本实验涵盖以下主题:
•缓冲区溢出漏洞和攻击
•函数调用中的堆栈布局
•地址随机化,非可执行堆栈和StackGuard
•Shellcode
二、实验环境
1.实验平台
SEED Ubuntu 20.04 VM
2.实验环境搭建
(1)关闭地址随机化对策

(2)编译程序以及docker搭建
A. 为了编译stack.c,我们需要使用 "-fno-stack-protector" 和 “-z execstack” 选项来关闭堆栈保护器和不可执行的堆栈保护,下面是给出的示例命令:

其中L1环境变量设置堆栈内的BUF SIZE常量的值。
B. 编译命令在Makefile里面已经给出,需要将stack.c编译为32位和64位的二进制文件,变量L1,L2,L3和L4在Makefile中设置:

C. 执行make命令,编译stack.c文件

编译生成了四个二进制文件,make install命令将这些文件复制到了bof-containers文件夹下,以便后续可以被容器使用。
D. 下载安装并解压Labsetup.zip,进入Labsetup文件夹

创建docker环境

启动环境

E. 查看已创建的容器ID

三、实验任务
Task1:熟悉Shellcode,目标:修改Shellcode,使其能够删除一个文件。
1.Shellcode常用于代码注入攻击,它基本上是一段启动Shell的代码,通常是用汇编语言编写。在本实验中,提供了二进制版本的Shellcode:

上图所示的Shellcode运行/bin/bash程序(①),并且给出了两个参数,“-c”(②)和一条命令字符串(③),shell程序会运行第二个参数中的命令字符串。这些字符串末尾的*只是一个占位符,在执行shellcode期间,它将被0x00的一个字节所替换。每个字符串的末尾都需要有一个零,但是我们不能在shellcode中放零。相反,我们在每个字符串的末尾放置一个占位符,然后在执行过程中动态地在占位符中放置一个零。

在call_shellcode.c中我们可以看到,该代码将二进制文件的内容读取后转化成为了函数,并执行该函数,函数的功能即运行上述的shell命令
2.尝试运行给出的代码(与前面的示例代码有些许不同):


可以看到a64.out运行后成功执行了/bin/ls -l; echo Hello 64; /bin/tail -n 4 /etc/passwd 三条命令
3.创建一个test.txt文件用于演示删除

4.修改shellcode代码,现在该命令字符串会在删除文件前后分别打印出目录信息,方便观察,注意保持占位符*的位置对齐,确保长度相同

5.重新编译运行代码,观察运行结果:

通过两次 ls 输出我们可以观察到test.txt已经被成功删除,Task1完成。
Task 2: Level-1 Attack
1.我们的第一个目标运行在10.9.0.5上(端口号是9090),并且易受攻击的程序堆栈是一个32位的程序。让我们先向此服务器发送一条良性消息。我们将看到目标容器打印出的以下消息:

此时栈帧栈底指针ebp的值为0xffffd278,缓冲区地址为0xffffd208。
服务器将接受来自用户的多达517字节的数据,这将导致缓冲区溢出。我们的目标是构建有效负载来利用这个漏洞,我们需要准备一个有效负载,并将其保存在一个文件中(我们将使用badfile作为本文档中的文件名)。
2.查看给出的样例程序:exploit.py

该代码需要我们填充shellcode的内容,并且确定shellcode在content数组中开始填充的位置,以及堆栈的返回地址和偏移值。
3.shellcode填充为Task1中提供的样例程序内容,这里我们选择32位的程序:

4.填充start、ret和offset内容
根据我的理解,为了实现栈溢出,shellcode应尽量插入在content数组的末端,这样可以保证shellcode高于返回地址的位置。若在缓冲区填充shellcode,那么可能由于缓冲区大小不足导致shellcode覆盖了返回地址。所以我们计算出shellcode的长度后,将start设置为content长度减去shellcode的长度,这样确保了shellcode在content的末端。

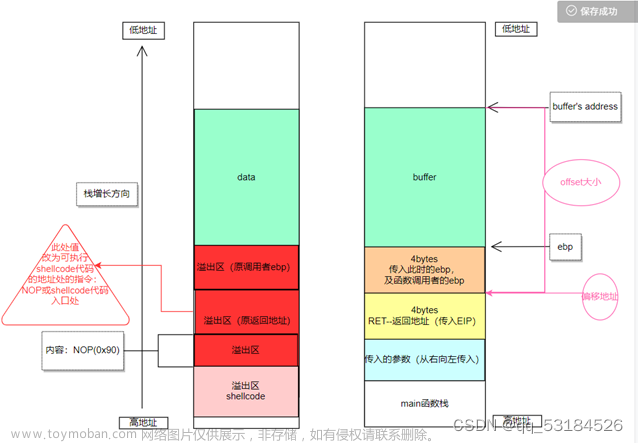
对于返回地址的修改,我的理解如下图所示

在栈中,当前函数执行结束后的返回地址存放于栈底指针ebp的上一个高位地址中,这样函数退出时可以将ebp的值置为返回地址的值。
我们为了实现栈溢出攻击,要覆盖原本的返回地址,并且将其设置为返回地址所在地址(ebp+4)到shellcode的起始地址之间的某个地址,这里我经过试验后发现最小值为ebp+8,最大值为ebp+312,但我没有弄清这个最大值从何而来。
offset的目的是在content中对应覆盖原本返回地址的位置填充上ret的值,那么栈溢出后原本的返回地址就会被ret覆盖。经过计算,其值应该为ebp到缓冲区起始地址的距离加上4(32位地址)。
根据上述讨论过程填充内容:

5.编译运行,观察结果:

shellcode成功执行,输出了给定语句。
6.实现反弹shell

将shellcode内容替换为以上内容,而控制方ip为:10.9.0.1

控制方监听在9090端口,等待被控制方接入:

另开一个终端,运行py文件,发送badfile

成功反弹shell,获得被控制方重定向的输出,任务二完成

Task 3: Level-2 Attack
1.在这个任务中,将不再给出目标服务器端的栈底指针ebp,仅给出缓冲区的地址,以及缓冲区大小的范围,要求用尽量少的尝试次数实现攻击。

缓冲区的起始地址为0xffffd478,缓冲区大小范围为 [100,300] 。
2.因为我们不知道栈底指针的位置,所以我们不能准确设置ret在content中的位置,但是我们知道了缓冲区的大小范围,那么只要将所有可能是返回地址的位置 [100,300] 都填充上ret,那么就可以修改原本的返回地址。具体如下图所示:

只要确保ret的值高于原本的栈底位置并且低于shellcode即可,这里设置为buffer起始地址+304。
3.修改exploit.py代码:


4.运行代码,发送badfile,观察结果:


成功运行了shellcode,任务三完成。
Task 4: Level-3 Attack
1.在前面的任务中,我们的目标服务器是32位程序。在这个任务中,我们切换到一个64位的服务器程序。我们的新目标是10.9.0.7,它运行着64位版本的堆栈程序。让我们先向此服务器发送一条hello消息。我们将看到由目标容器打印出的以下消息:

栈帧指针rbp的值为:0x00007fffffffe4e0,缓冲区地址:0x00007fffffffe410
可以看到帧指针和缓冲区地址的值变为8字节长(而不是32位程序中的4字节)。我们的目标是构建有效负载,以利用服务器的缓冲区溢出漏洞。
2.任务难点:与对32位机器的缓冲区溢出攻击相比,对64位机器的攻击更加困难。最困难的部分是地址。虽然x64架构支持64位地址空间,但只允许从0x00到0x00007 FFFFFFFFFFF的地址。这意味着对于每个地址的最高的两个字节总是零。这导致了一个问题。在我们的缓冲区溢出攻击中,我们需要在有效负载中至少存储一个地址,并且有效负载将通过strcpy()复制到堆栈中。我们知道,strcpy()函数在看到一个零时将停止复制。因此,如果在有效负载的中间出现了一个零,则不能将零之后的内容复制到堆栈中。如何解决这个问题是这次攻击中最困难的挑战。
3.下图显示了我模拟的栈复制的过程:

当栈覆盖到原本的返回地址时,由小端的存储方式,地址先从低地址开始读取。但地址的高位为0,那么读取到00之后strcpy()就会停止,也就意味着content数组中offset+6以后的内容都不会存储到栈中。此时我们将ret再设置为高于ebp的地址将毫无意义,因为如果shellcode在content的尾端就不会复制到栈中。
因此,本任务中我们可以将shellcode存储在content的首部,让它从缓冲区开始存储(此处默认shellcode的长度不会超过缓冲区的大小),那么我们的ret地址就应该设置为缓冲区的地址,这样栈返回后就会到缓冲区地址开始执行shellcode程序。
4.结合上述思路,修改代码:


5.运行,上传badfile


成功执行了shellcode,Task4完成。
Task 5: Level-4 Attack
1.在Task4中,缓冲区的大小足够我们填充shellcode,而在本任务中,缓冲区的大小将无法满足这一要求:

从图中可看到,缓冲区地址为0x00007fffffffe2a0,而栈帧指针rbp的值为0x00007fffffffe300,相减可得缓冲区大小为96 bytes,而shellcode的长度为165,无法使用Task4中的方法。
2.查看stack.c文件:可以看到被读取的content是保存在str中的,然后再用strcpy()复制到缓冲区里,虽然读取停止了,但str中保存了shellcode,我们只要将返回地址修改为str的地址即可执行shellcode。

3.为了找到str的地址,用gdb调试stack.c程序:

运行gdb,进入查看代码,找到int length = fread(str, sizeof(char), 517, stdin);这一行代码,设置断点,运行程序:

运行 run < /home/seed/Desktop/Labsetup/attack-code/badfile,将载荷文件上传进行测试

单步执行n到53 dummy_function(str); 输入s进入查看该函数,继续单步执行到65 bof(str); 输入s进入查看该函数,继续执行,直到看到语句:42 strcpy(buffer, str);执行完该语句后,查看str和buffer的位置:


str的地址为0x7fffffffde80,buffer的地址为0x7fffffffd9f0,两者相减得到两地址之间的差值:1168(十进制)

4.根据上述结果,我们可以将shellcode存储在content的末端,然后将ret的值设置为: buffer(缓冲区起始地址)+ 1168 + 517 - len(shellcode) 。这样就可以让程序返回时直接到达str中shellcode的位置,执行命令。


5.运行,上传badfile,观察结果


成功执行shellcode,Task5完成。
Task 6: Experimenting with the Address Randomization
1.在之前的实验中,我们关闭了地址随机化对策(ASLR),在这次任务中,我们将重新开启这一对策,并观察其对栈溢出攻击的影响:

向Level-1 Server重复发送几次hello,观察结果:

可以发现每次栈的指针和缓冲区地址都不同了。
2.根据文档中的描述,在32位的Linux机器上,只有19个片段可以用于地址随机化。这还不够,如果我们运行足够多的攻击次数,我们可以很容易地达到目标。我们可以使用以下的shell脚本来实现爆破,下面的shell脚本将在无限循环中运行易受攻击的程序。如果得到反向shell,脚本将停止;否则,它将继续运行。

3.启动环境,运行Task2代码,开启9090端口监听,运行脚本:

4.爆破成功,监听到反弹shel,用时1分17秒,Task6完成。

Tasks 7: Experimenting with Other Countermeasures
1.Task 7.a: Turn on the StackGuard Protection
许多编译器,如gcc,实现了一种名为StackGuard的安全机制,以防止缓冲区溢出。在存在此保护时,缓冲区溢出攻击将不起作用。所提供的易受攻击的程序编译没有启用堆栈保护。在这个任务中,我们将打开它,看看会发生什么。
(1)删除Makefile中flags中的-fno-stack-protector选项,编译stack.c。

 (2)上传badfile到stack-L1,观察结果:
(2)上传badfile到stack-L1,观察结果:

程序检测到栈溢出,被终止了
2.Task 7.b: Turn on the Non-executable Stack Protection
在Ubuntu操作系统中,程序(和共享库)的二进制映像必须声明它们是否需要可执行的堆栈,也就是说,它们需要在程序头中标记一个字段。内核或动态链接器使用此标记来决定是使此正在运行的程序的堆栈可执行或不可执行。此标记是由gcc自动完成的,默认情况下,它使堆栈不可执行。我们可以在编译中使用“-z noexecstack”标志使其不可执行。在我们之前的任务中,我们使用“"-z execstack”来使堆栈可执行。
在此任务中,我们将使堆栈不可执行。我们将在shellcode文件夹中做这个实验。call_shellcode程序会在堆栈上放一个shellcode副本,然后从堆栈中执行代码。请重新编译call_shellcode.c为a32.out和a64.out,并且删除"-z execstack"选项。运行它们,描述和解释你的观察结果。
(1)删除Makefile中的"-z execstack"选项,重新编译


(2)运行a64.out和a32.out,观察结果:

运行显示:Segmentation fault,表明程序返回时遇到不可执行栈导致错误。文章来源:https://www.toymoban.com/news/detail-781540.html
(3)攻击不可执行栈的对策:需要注意的是,不可执行堆栈只是使其无法在堆栈上运行shellcode,但它不能防止缓冲区溢出攻击,因为在利用缓冲区溢出漏洞之后还有其他方法来运行恶意代码。 return-to-libc attack就是一个例子。这里不再进行讨论。文章来源地址https://www.toymoban.com/news/detail-781540.html
到了这里,关于网络攻防技术——缓冲区溢出攻击(基于服务器)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!

![[操作系统安全]缓冲区溢出](https://imgs.yssmx.com/Uploads/2024/02/780476-1.png)








