博主简介
博主是一名大二学生,主攻人工智能研究。感谢让我们在CSDN相遇,博主致力于在这里分享关于人工智能,c++,Python,爬虫等方面知识的分享。 如果有需要的小伙伴可以关注博主,博主会继续更新的,如果有错误之处,大家可以指正。
专栏简介: 本专栏主要研究python在人工智能方面的应用,涉及算法,案例实践。包括一些常用的数据处理算法,也会介绍很多的Python第三方库。如果需要,点击这里 订阅专栏。
给大家分享一个我很喜欢的一句话:“每天多努力一点,不为别的,只为日后,能够多一些选择,选择舒心的日子,选择自己喜欢的人!”

目录
背景引入
语音识别简介
语音识别的起源与发展
语音识别的基本原理
语音识别Python SDK
Microsoft 语音识别框架SAPI
Speech
Python_Speech_Features工具库
params
SpeechRecognition库工具
背景引入
自动语音识别(Automatic Speech Recognition,ASR)是近十年来发展较快的技术之一。随着深度学习 在AI领域的广泛应用,语音识别技术开始逐步从实验室走向市场,百度公司基于深度学习研发的新一代深度语音识别系统Deep Speech 2,识别准确率可以达到97%,美国著名杂志《MIT Technology Review》将他评为“2016年十大突破技术”之一,并认为该技术在未来几年将会极大改变人们的生活。
在人工智能领域,语音识别是非常重要的一个环节,因为语音是智能系统获取外界信息的重要途径之一,较之于键盘和鼠标等输入方法,语音输入更快捷,高效。近年来,智能手机等各种高端的移动应用终端都集成了语音识别系统,使得这些智能化程度更高,使用起来也更方便。语音交互产品中具有代表性的有Apple公司的Siri,Microsoft公司的Cortana,Amazon公司的Alexa,华为公司的小E和百度公司的小度等。随着语音技术的高速发展,各大软硬件厂商纷纷布局,在推出相关硬件产品的同时,也开始关注语音芯片的研发。语音识别技术的确带给了人们方便,尤其是对于一些文化水平不高的人群具有很大的便利性。
语音识别简介
语音识别的起源与发展
语音识别是一门复杂的交叉技术学科,通常涉及声学,信号处理,模式识别,语言学,心理学,以及计算机等多个学科领域。语音识别技术的发展可追寻到20世纪50年代,贝尔实验室首次实现Audrey英文数字识别系统(可识别0——9单个数字英文识别),并且准确识别率达到90%以上。普林斯顿大学和麻省理工学院在同一时期也推出了少量词语的独立识别系统。到20世纪80年代,隐马尔可夫模型(Hidden arkov Model,HMM)。N-gram语言模型等重要技术开始被应用于语言识别领域,是的语音识别技术从孤立词识别到连续词识别。到20世纪90年代,大词汇量连续识别技术持续进步,最小分类错误(Minimum Classification Error,MCE)以及最大互信息(Maximum Mutual Information,MMI)等区分性十五模型训练方法开始被应用,使得语音识别的准确率逐步提高,尤其适用于长句子情形。与此同时,最大后验概率(Maximum Aposteriori Probablity,MAP)与最大似然线性回归(Maximum Likelihood Linear Regression,MLLR)等模型自适应方法也开始被应用于语音识别模型的训练。到了21世纪,随着深度学习的不断发展,神经网络之父杰弗里·辛顿(Geoffrey Hinton)提出深度置信网络(Deep Belief Network,DBN)。2009年,辛顿和他的学生默罕默德(Mohamed)将深度神经网络应用于语音识别,在TIMIT语音库上进行的小词汇量连续语音识别任务获得成功。TIMIT是由德州仪器(Texas Instruments,TI)。麻省理工学院和斯坦福国际研究学院(SRI International)合作构建的声学-音频连续识别语音库。
语音识别的基本原理
语音是一种非常复杂的现象,很少人能够理解它是如何被感知的。我们通常的直觉是语音是由单词构成,而单词又是由各种音素(Phoneme)构成。然而事实上并非如此,语音本身是一个动态的过程,是一种连续的音频流,是由一部分相当稳定状态与诸多动态变化的状态混合而成。在这种状态序列中,人们可以定义或多或少类似的声音或音素。通过Adobe Audition等音频编辑软件进行录音播放,可看到随时间变化的语音动态波形。
一个典型的语音对话系统一般包括如下几个技术模块:对话管理器(Dialog Manager),语音识别器(Speech Recognizer),语言解析器(Language Parser),语言生成器(Language Generator)和语音合成器(Speech Synthesizer)。其中,语音识别器(又可称为语音识别模块或者语言识别系统)主要用于将用户输入的语音转化为文本,这也是我们最关注的核心技术。语音识别由以下几个部分构成。
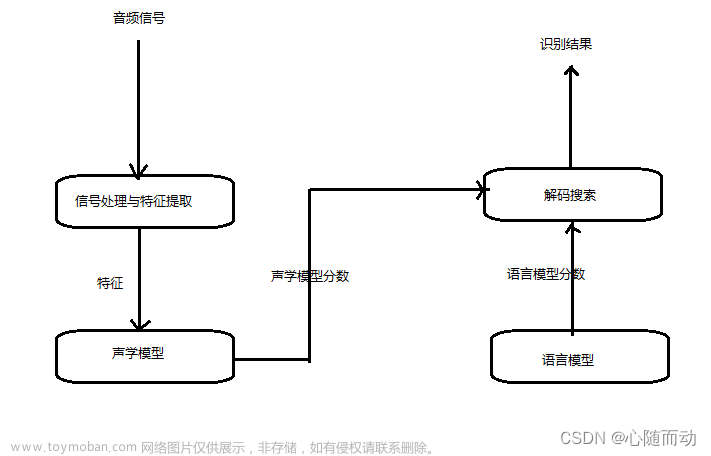
语音识别是一个先编码后解码的过程。其中,信号处理(Signal Processing)与特征提取(Feature Extraction)是语音识别系统的开始。,这是一个编码的过程。特征提取是指从原始的语音输入经过相应处理后得到的语音特征向量(Eigenvector)。语音识别的一般方法是:首先提取一个波形,然后将其分解为语音片段并尝试识别每个语音片段中的内容。通常情况下,要做到这一点,我们需要尝试将所有可能的单词进行组合然后与音频进行匹配,最后选择最佳匹配。由于参数数量过大,需要对其进行优化,所以我们会将语音分解成帧,然后对于每帧,提取出39个代表语音特征的代表数字,这些数字即语音特征向量。
我们在提取音频信息后,通过噪声和消除和信道畸变(Channel Distortion)进行语音增强,将信号从时域转化为频域,并为后面的操作提供具有特侦的特征向量。在信号处理过程中,常用梅尔频率倒谱系数(Mel-Frequency Cepsptral Coefficient,MFCC)或感知线性预测(Perceptual Linear Prediction,PLP)作为特征向量,然后使用混合高斯模型-隐马尔可夫模型(GMM-HMM)作为声学模型,再利用最大似然(Maximum Likelihood,ML)准则,序列鉴别性训练算法,例如,最小分类错误和最小音素错误(Minimum Phone Error,MPE)等模型进行训练。
声学模型则以特征提取部分生成的特征为输入,为可变特征长序列(Variable -Length)生成声学模型分数(Acoustic Model Score)。声学模型处理的问题主要在于特征向量序列的可变长和音频信号的丰富变化性。因为语音长度是不确定的,所i特征向量序列的长度也不确定。我们一般通过动态时间规整(Dynamic Time Warping,DTW)算法和隐马尔可夫模型来处理可变长特征序列。语言模型通过训练语料来学习词语词之间的关系,估计假设词序列的可能性,又称为语言模型分数。下面我们来介绍一下具体操作。
语音识别Python SDK
Microsoft 语音识别框架SAPI
SAPI是Microsoft公司提供的语音接口框架,提供了应用程序和语音引擎之间的高级接口,实现了控制和管理各种语音引擎的实时操作所需的所有细节。SAPI引擎主要由文本转语音(Text-To-Speech,TTS)系统和语音识别器构成。
import win32com.client #载入SAPI语音识别转换 from win32com.client import constants import pythoncom #主要应用于python调用com接口
载入SAPI语音处理模块并合成和输出指定语音的示例代码如下。
speaker=win32com.client.Dispatch('SAPI.SPVOICE') speaker.Speak('开启微软语音接口') speaker.Speak('Microsoft Speech API Initialized.')#英文语音合成
除了语音合成功能,SAPI可通过以下示例代码开启语音识别代码:
win32com.client.Dispatch('SAPI.SpSharedRecognizer')以下为一个基于Microsoft语音识别框架SAPI的语音识别应用的完整代码。
import win32com.client #载入SAPI语音识别转换 from win32com.client import constants import pythoncom #主要应用于python调用com接口 #定义语音识别对象并开启SAPI语音识别引擎 speaker=win32com.client.Dispatch('SAPI.SPVOICE') #定义一个语音识别类 class SpeechRecognition: #用传入的单词列表初始化语音识别 def __init__(self,wordsToAdd): #启动TTS self.speaker=win32com.client.Dispatch('SAPI.SpVoice') #启动语音识别引擎,首先创建一个侦听器 self.listener=win32com.client.Dispatch("SAPI.SpSharedRecognizer") #创建语音识别上下文 self.context=self.listener.CreateRecoContext() #不允许自由识别单词————仅限命令和控制识别语法中的单词 self.grammar=self.context.CreateGrammar() #为语法创建一个新规则,即顶级规则和动态规则 self.grammar.DictationSetState(0) self.wordsRule=self.grammar.Rules.Add("wordsRule",constants.SRATopLevel+\ constants.SRADynamic,0) #清除规则 self.wordsRule.Clear() #浏览单词列表 [self.wordsRule.InitialState.AddWordTransition(None,word) for word in wordsToAdd] #将设置好的wordsrule规则激活 self.grammar.Rules.Commit() self.grammar.CmdSetRuleState("wordsRule",1) #提交对语法规则的更改 self.grammar.Rules.Commit() #添加一个事件处理程序 self.eventHandler=ContextEvents(self.context) #设置一个语音提示 self.say("Successfully Started.") #定义一个函数进行TTS语音输出 def say(self,phrase): self.speaker.Speak(phrase) #处理语音对象引发的事件的回调类 class ContextEvents(win32com.client.getevents("SAPI.SpSharedRecoContext")): def OnRecognition(self,StreamNumber,StreamPosition,RecognitionType,Result): newResult=win32com.client.Dispatch(Result) print("You just said:",newResult.PhraseInfo.GetText()) speechstr=newResult.PhraseInfo.GetText() #定义语音识别关键词及其对应的语音输出信息 if speechstr=="你好": speaker.Speak("How are you doing?") elif speechstr=="测试": speaker.Speak("This is a testing program for speech recognition.") elif speechstr=="欢迎你": speaker.Speak("You are welcome to be here") elif speechstr=='新年快乐': speaker.Speak("Happy New Year in 2019") elif speechstr=="作者": speaker.Speak("心随而动") else: pass if __name__=='__main__': speaker.Speak("语音识别系统开启") wordsToAdd=['你好','测试','欢迎你','新年快乐','作者'] speechReco=SpeechRecognition(wordsToAdd) while True: pythoncom.PumpWaitingMessages() #检查是否有事件在等待,然后再调用适当的回调可能由于python版本的问题,可能会出现报错,这是版本的问题。
程序运行后,会出现“语音识别系统开启”的提示,然后等待用户语音输入。
Speech
Speech是一个智能语音模块,其主要功能包括语音识别,将指定文本合成为语音及将语音信号输出等。该模块不是内置模块,所以需要我们去下载:
pip install speech
Speech模块安装完后,我们可使用以下示例代码来实现启动和关闭语音系统:
#speech import speech while True: phrase=speech.input() #循环等待语音输入 speech.say("You said %s" %phrase) if phrase=='turn off': break如果你使用的是python3版本,那么下载后的speech是不能直接使用,需要你将代码改变一下。打开speech.py文件,
- 修改一:第157行,
print prompt改为print(prompt)。- 修改二:第59行,
thread改为_thread。- 修改三:最后一行的
thread应该改为_thread。
下列示例代码演示了如何通过speech模块调用Microsoft SAPI语音识别处理模块来对计算机进行简单的语音指令控制:
#语音控制计算机 import sys #用于windows系统操作 import speech import webbrowser #用于打开指定网络连接 import os def callback(phr): if phr=="关闭语音识别": speech.say("Goodbye,Speech Recognition system is closing.") #播放提示语音 speech.stoplistening() #关闭SAPI sys.exit() #推出程序 elif phr=="播放电影": speech.say("I am prepaing the movie for you.") #播放提示语音 webbrowser.open_new('https://www.youku.com/') elif phr=="看新闻": speech.say("I want to know what the world is going on") webbrowser.open_new("https://www.baidu.com/") elif phr=="打开控制台": speech.say("打开CMD") os.popen("C:\\Windows\\System32\\cmd.exe") while True: phr=speech.input() #语音输入 speech.say("You said is %s"%phr) callback(phr) #调用函数
Python_Speech_Features工具库
Python_Speech_Features工具库提供了诸如MFCC,SSC,Fiterbank等进行语音识别的算法和工具。运行库需要Numpy,Scipy库的支持。可以按照上面的安装方式安装。
由于该库中的函数太多,很难详细介绍,大家可以去官网查看:
这里介绍了一下mfcc函数的参数:
params
- signal:
the audio signal from which to compute features.Should be an N1 array
用来计算梅尔频率倒谱系数特性的音频信号。是一个N1的数组- samplerate:
the samplerate of the signal we are working with.
音频信号的采样率- winlen:
the length of the analysis window in seconds. Default is 0.025s (25 milliseconds)
分析窗口的长度,以秒为单位。默认值为0.025s(25毫秒)(ps: 短时傅里叶变换的窗口长度)- winstep:
the step between successive windows in seconds. Default is 0.01s (10 milliseconds)
连续窗口之间的步长,以秒为单位。默认值为0.01s(10毫秒)- numcep:
the number of cepstrum to return, default 13
返回倒谱的数量,默认为13- nfilt:
the number of filters in the filterbank, default 26.
滤波器组中的过滤器数量,默认为26个。- nfft:
the FFT size. Default is 512.
FFT大小。默认是512。- lowfreq:
lowest band edge of mel filters. In Hz, default is 0.
梅尔滤波器的最低频带边缘。在频率(HZ)中,默认值为0。- highfreq:
highest band edge of mel filters. In Hz, default is samplerate/2
梅尔过滤器的最高频带边缘。在频率(HZ)中,默认值为1/2倍音频信号采样率- preemph:
apply preemphasis filter with preemph as coefficient. 0 is no filter. Default is 0.97.
采用preemph为系数的预加重滤波器。0不是过滤器。默认是0.97。- ceplifter:
apply a lifter to final cepstral coefficients. 0 is no lifter. Default is 22.
将一个lifter应用到最终倒谱系数。0不是lifter。默认是22。- appendEnergy:
if this is true, the zeroth cepstral coefficient is replaced with the log of the total frame energy.
如果这个参数的值是True,第0阶倒谱系数被替换为总帧能量的对数。- winfunc:
the analysis window to apply to each frame. By default no window is applied. You can use numpy window functions here e.g. winfunc=numpy.hamming
分析窗口应用于每一帧。默认情况下不应用任何窗口。您可以在这里使用numpy窗口函数,例如winfunc=numpy.hamming(汉明窗)c
下列函数代码,我们载入一段音频。利用库中的函数进行分析和提取:
from python_speech_features import mfcc from python_speech_features import logfbank import scipy.io.wavfile as wav #用于语音文件载入 (rate,sig)=wav.read("file.wav") #载入音频文件,大家自己使用自己的音频文件,这里博主随便写了一个 mfcc_feat=mfcc(sig,rate) fbank_feat=logfbank(sig,rate) #计算滤波器组能量特征的对数 #输出结果 print("MFCC Features:") print(mfcc_feat[1:3,:]) print("LogFBank Features:") print(fbank_feat[1:3,:])
SpeechRecognition库工具
SpeechRecognition是一个用于语音识别的Python库,他同时支持python2和python3联机或离线的多个引擎和API。
为确保SpeechRecognitional能够正常使用,我们需要先安装PyAudio模块,这是用于话筒相关的操作需要该模块的支持。安装完成后,我们可以输入以下的命令来进行检测:
python -m speech_recognition
该语音识别引擎支持以下几种不同的API:
①CMU Sphinx。
②Google Speech Recognition
③Google Cloud Speech
④Microsoft Bing Voice Recognition
⑤IBM Speech to Text
⑥ Houndify
其中,CMU Sphinx支持离线语音识别,其他诸如Microsoft Bing Voice Recognition,IBM Speech to Text等则需要语音识别引擎在线联机工作。
下列示例代码将演示如何将SpeechRecognition和上述的API进行联合使用,以此达到语音识别的目的。
import speech_recognition as sr#导入SpeechRecognition库 #从话筒获取语音识别的音频源 r=sr.Recognizer() with sr.Microphone() as source: print("Say something") audio=r.listen(source) #利用Cmu Sphinx进行语音识别 try: print("Sphinx thinks you said"+r.recognize_sphinx(audio)) except sr.UnknownValueError: print("Sphinx could not undestand audio") except sr.RequestError as e: print("Sphinx error;{0}".format(e)) #利用Google Speech Recognition进行语音识别 try: ''' 处于测试的目的,我们使用默认的API密钥,若要使用其他的API密钥,建议使用 r.recognize_google(audio,key="GOOGLE_SPEECH_RECOGNITION_API_KEY"),而不是用r.recognize_google(audio) ''' print("Google Speech Recognition thinks you said"+r.recognize_google(audio)) except sr.UnknownValueError: print("Google Speech Recognition could not wnderstand audio") except sr.RequestError as e: print("Could not equest results from Google Speech Recognition service;{0}".format(e)) GOOGLE_CLOUD_SPEECH_CREDENTIALS=r"""INSERT THE CONTENTS OF THE GOOGLE CLOUD SPEECH JSON CREDENTIALS FILE HERE""" try: print("Google cloud speech thinks you said"+r.recognize_google_cloud(audio,credentials_json=GOOGLE_CLOUD_SPEECH_CREDENTIALS)) except sr.UnknownValueError: print("Google Cloud Speech could not understand audio") except sr.RequestError as e: print("Could not request results from google cloud Speech service;{0}".format(e)) #利用Microsoft Bing voice Recognition进行语音识别 BING_KEY="INSERT BING API KEY HERE" try: print("Microsoft Bing Voice Recognition thinks you said"+r.recognize_bing(audio,key=BING_KEY)) except sr.UnknownValueError: print("Microsoft Bing Voice Recognition could not understand audio") except sr.RequestError as e: print("Could not request results from Microsoft Bing Voice Recognition service;{0}".format(e)) #利用Houndify进行语音识别。Hounddify客户端ID是Base64编码字符串 HOUNDIFY_CLIENT_ID="INSERT HOUNDIFY CLIENT ID HERE" #加密客户端密钥是Base64编码字符串 HOUNDIFY_CLIENT_KEY="INSERT HOUNDIFY CLIENT KEY HERE" try: print("Houndify thinks you said"+r.recognize_houndify(audio,client_id=HOUNDIFY_CLIENT_ID,client_key=HOUNDIFY_CLIENT_KEY)) except sr.UnknownValueError: print("Houndify could not understand audio") except sr.RequestError as e: print("Could not request results from Houndify service;{0}".format(e)) ''' 利用IBM Speech to Text进行语音识别 ''' IBM_USERNAME="INSERT IBM SPEECH TO TEXT USERNAME HERE" #IBM Speech to Text密码是混合大小,小写字母和数字的字符串 IBM_PASSWORD="INSERT IBM SPEECH TO TEXT PASSWORD HERE" try: print("IBM Speech to Text thinks you said"+r.recognize_ibm(audio,username=IBM_USERNAME,password=IBM_PASSWORD)) except sr.UnknownValueError: print("IBM Speechh to Text could not understand audio") except sr.RequestError as e: print("Could not request results from IBM Speech to Text service;{0}".format(e))
运行程序,我们就可以从话筒获取语音,然后通过几种不同的语音识别引擎来进行启动。
当然,我么也可以直接导入音频文件来进行语音识别。示例代码:
from os import path AUDIO_FILE=path.join(path.dirname(path.realpath(__file__)),"English.wav") #导入音频文件,大家自己更改路径 r=sr.Recognizer() with sr.AudioFile(AUDIO_FILE) as source: audio=r.record(source)
除了使用音频文件,我么也可以使用话筒来获取语音并存储为不同格式的文件
import speech_recognition as sr r=sr.Recognizer()#从话筒获取语音 with sr.Microphone() as source: print("Say something!") audio=r.listen(source) #将音频写入.raw文件 with open('microphone-results.raw','wb') as f: f.write(audio.get_raw_data()) #写入.wav文件 with open('microphone-results1.wav','wb') as f: f.write(audio.get_wav_data()) #写入.aiff文件 with open('microphone-results2.aiff','wb') as f: f.write(audio.get_aiff_data()) #写入.flac文件 with open('microphone-results.flac','wb') as f: f.write(audio.get_flac_data())
语音识别对环境有一定的要求,环境噪声和干扰对语音识别会有一定的影响,我们可以通过以下示例代码来校准环境噪声的识别器能量阈值:
r=sr.Recognizer()
with sr.Microphone()as source:
#倾听1秒以内能量校准阈值
r.adjust_for_ambient_noise(source)
print("Say something!")
audio=r.listen(source)好了,本期的内容就到此结束了,后面会介绍MFCC算法用于语音特征分析提取。感兴趣的小伙伴可以留意关注一下。文章来源:https://www.toymoban.com/news/detail-781714.html
 文章来源地址https://www.toymoban.com/news/detail-781714.html
文章来源地址https://www.toymoban.com/news/detail-781714.html
到了这里,关于语音识别与Python编程实践的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!

![[语音识别] 基于Python构建简易的音频录制与语音识别应用](https://imgs.yssmx.com/Uploads/2024/02/662057-1.png)