简介
简介
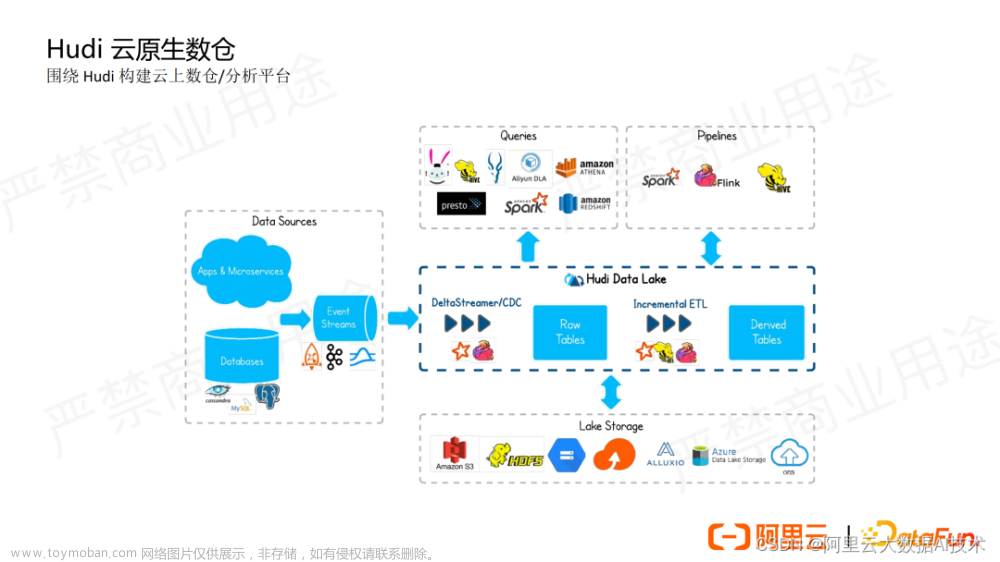
Apache Hudi(Hadoop Upserts Delete and Incremental)是下一代流数据湖平台。Apache Hudi将核心仓库和数据库功能直接引入数据湖。Hudi提供了表、事务、高效的upserts/delete、高级索引、流摄取服务、数据集群/压缩优化和并发,同时保持数据的开源文件格式。
Apache Hudi不仅非常适合于流工作负载,而且还允许创建高效的增量批处理管道。
Apache Hudi可以轻松地在任何云存储平台上使用。Hudi的高级性能优化,使分析工作负载更快的任何流行的查询引擎,包括Apache Spark、Flink、Presto、Trino、Hive等。

Hudi项目最初的设计目标:在hadoop上实现update和delete操作。
发展历史
- 2015 年:发表了增量处理的核心思想/原则(O’reilly 文章)。
- 2016 年:由 Uber 创建并为所有数据库/关键业务提供支持。
- 2017 年:由 Uber 开源,并支撑 100PB 数据湖。
- 2018 年:吸引大量使用者,并因云计算普及。
- 2019 年:成为 ASF 孵化项目,并增加更多平台组件。
- 2020 年:毕业成为 Apache 顶级项目,社区、下载量、采用率增长超过 10 倍。
- 2021 年:支持 Uber 500PB 数据湖,SQL DML、Flink 集成、索引、元服务器、缓存。
Hudi特性
- 可插拔索引机制支持快速Upsert/Delete。
- 支持增量拉取表变更以进行处理。
- 支持事务提交及回滚,并发控制。
- 支持Spark、Presto、Trino、Hive、Flink等引擎的SQL读写。
- 自动管理小文件,数据聚簇,压缩,清理。
- 流式摄入,内置CDC源和工具。
- 内置可扩展存储访问的元数据跟踪。
- 向后兼容的方式实现表结构变更的支持。
使用场景
(1)近实时写入
- 减少碎片化工具的使用。
- CDC 增量导入 RDBMS 数据。
- 限制小文件的大小和数量。
(2)近实时分析
- 相对于秒级存储(Druid, OpenTSDB),节省资源。
- 提供分钟级别时效性,支撑更高效的查询。
- Hudi作为lib,非常轻量。
(3) 增量pipeline
- 区分arrive time和event time处理延迟数据。
- 更短的调度interval减少端到端延迟(小时 -> 分钟) => Incremental Processing。
(4)增量导出
- 替代部分Kafka的场景,数据导出到在线服务存储 e.g. ES。
编译和安装
编译环境准备
相关组件版本如下:
| Hadoop | 3.1.3 |
|---|---|
| Hive | 3.1.2 |
| Flink | 1.13.6,scala-2.12 |
| Spark | 3.2.2,scala-2.12 |
安装Maven:
(1)上传apache-maven-3.6.1-bin.tar.gz到/opt/software目录,并解压更名
tar -zxvf apache-maven-3.6.1-bin.tar.gz -C /opt/module/
mv apache-maven-3.6.1 maven-3.6.1
(2)添加环境变量到/etc/profile中
sudo vim /etc/profile
#MAVEN_HOME
export MAVEN_HOME=/opt/module/maven-3.6.1
export PATH=$PATH:$MAVEN_HOME/bin
(3)测试安装结果
source /etc/profile
mvn -v
(4)修改为阿里镜像
修改setting.xml,指定为阿里仓库地址
vim /opt/module/maven-3.6.1/conf/settings.xml
<!-- 添加阿里云镜像-->
<mirror>
<id>nexus-aliyun</id>
<mirrorOf>central</mirrorOf>
<name>Nexus aliyun</name>
<url>http://maven.aliyun.com/nexus/content/groups/public</url>
</mirror>
上传Hudi源码包并修改pom文件
-
上传源码包:
# 将hudi-0.12.0.src.tgz上传到/opt/software,并解压: tar -zxvf /opt/software/hudi-0.12.0.src.tgz -C /opt/software # github地址:https://github.com/apache/hudi/ -
在pom文件中新增repository加速依赖下载:
# 编辑pom文件 vim /opt/software/hudi-0.12.0/pom.xml # 新增repository加速依赖下载 <repository> <id>nexus-aliyun</id> <name>nexus-aliyun</name> <url>http://maven.aliyun.com/nexus/content/groups/public/</url> <releases> <enabled>true</enabled> </releases> <snapshots> <enabled>false</enabled> </snapshots> </repository> -
在pom文件中修改依赖的组件版本:
<hadoop.version>3.1.3</hadoop.version> <hive.version>3.1.2</hive.version>
修改源码兼容hadoop3
Hudi默认依赖的hadoop2,要兼容hadoop3,除了修改版本,还需要修改如下代码:
vim /opt/software/hudi-0.12.0/hudi-common/src/main/java/org/apache/hudi/common/table/log/block/HoodieParquetDataBlock.java
修改第110行,原先只有一个参数,添加第二个参数null:

否则会因为hadoop2.x和3.x版本兼容问题(找不到合适的FSDataOutputStream构造器)。
手动安装Kafka依赖
有几个kafka的依赖需要手动安装,否则编译会报错。
(1)下载jar包
# 通过网址下载:http://packages.confluent.io/archive/5.3/confluent-5.3.4-2.12.zip
# 解压后找到以下jar包,上传编译服务器
common-config-5.3.4.jar
common-utils-5.3.4.jar
kafka-avro-serializer-5.3.4.jar
kafka-schema-registry-client-5.3.4.jar
(2)install到maven本地仓库
mvn install:install-file -DgroupId=io.confluent -DartifactId=common-config -Dversion=5.3.4 -Dpackaging=jar -Dfile=./common-config-5.3.4.jar
mvn install:install-file -DgroupId=io.confluent -DartifactId=common-utils -Dversion=5.3.4 -Dpackaging=jar -Dfile=./common-utils-5.3.4.jar
mvn install:install-file -DgroupId=io.confluent -DartifactId=kafka-avro-serializer -Dversion=5.3.4 -Dpackaging=jar -Dfile=./kafka-avro-serializer-5.3.4.jar
mvn install:install-file -DgroupId=io.confluent -DartifactId=kafka-schema-registry-client -Dversion=5.3.4 -Dpackaging=jar -Dfile=./kafka-schema-registry-client-5.3.4.jar
解决spark模块依赖冲突
修改了Hive版本为3.1.2,其携带的jetty是0.9.3,hudi本身用的0.9.4,存在依赖冲突。
(1)修改hudi-spark-bundle的pom文件
目的:排除低版本jetty,添加hudi指定版本的jetty
pom文件位置:vim /opt/software/hudi-0.12.0/packaging/hudi-spark-bundle/pom.xml (在382行的位置,修改如下红色部分)
文件要修改,要指定<dependency>里的<exclusions>剔除hive模块的jetty依赖,然后添加hudi使用的jetty依赖,否则后面在使用Spark向hudi表添加数据时会报错(不信可以试试):
java.lang.NoSuchMethodError: org.apache.hudi.org.apache.jetty.server.session.SessionHandler.setHttpOnly(Z)V
<!-- Hive -->
<dependency>
<groupId>${hive.groupid}</groupId>
<artifactId>hive-service</artifactId>
<version>${hive.version}</version>
<scope>${spark.bundle.hive.scope}</scope>
<exclusions>
<exclusion>
<artifactId>guava</artifactId>
<groupId>com.google.guava</groupId>
</exclusion>
<exclusion>
<groupId>org.eclipse.jetty</groupId>
<artifactId>*</artifactId>
</exclusion>
<exclusion>
<groupId>org.pentaho</groupId>
<artifactId>*</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>${hive.groupid}</groupId>
<artifactId>hive-service-rpc</artifactId>
<version>${hive.version}</version>
<scope>${spark.bundle.hive.scope}</scope>
</dependency>
<dependency>
<groupId>${hive.groupid}</groupId>
<artifactId>hive-jdbc</artifactId>
<version>${hive.version}</version>
<scope>${spark.bundle.hive.scope}</scope>
<exclusions>
<exclusion>
<groupId>javax.servlet</groupId>
<artifactId>*</artifactId>
</exclusion>
<exclusion>
<groupId>javax.servlet.jsp</groupId>
<artifactId>*</artifactId>
</exclusion>
<exclusion>
<groupId>org.eclipse.jetty</groupId>
<artifactId>*</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>${hive.groupid}</groupId>
<artifactId>hive-metastore</artifactId>
<version>${hive.version}</version>
<scope>${spark.bundle.hive.scope}</scope>
<exclusions>
<exclusion>
<groupId>javax.servlet</groupId>
<artifactId>*</artifactId>
</exclusion>
<exclusion>
<groupId>org.datanucleus</groupId>
<artifactId>datanucleus-core</artifactId>
</exclusion>
<exclusion>
<groupId>javax.servlet.jsp</groupId>
<artifactId>*</artifactId>
</exclusion>
<exclusion>
<artifactId>guava</artifactId>
<groupId>com.google.guava</groupId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>${hive.groupid}</groupId>
<artifactId>hive-common</artifactId>
<version>${hive.version}</version>
<scope>${spark.bundle.hive.scope}</scope>
<exclusions>
<exclusion>
<groupId>org.eclipse.jetty.orbit</groupId>
<artifactId>javax.servlet</artifactId>
</exclusion>
<exclusion>
<groupId>org.eclipse.jetty</groupId>
<artifactId>*</artifactId>
</exclusion>
</exclusions>
</dependency>
<!-- 增加hudi配置版本的jetty -->
<dependency>
<groupId>org.eclipse.jetty</groupId>
<artifactId>jetty-server</artifactId>
<version>${jetty.version}</version>
</dependency>
<dependency>
<groupId>org.eclipse.jetty</groupId>
<artifactId>jetty-util</artifactId>
<version>${jetty.version}</version>
</dependency>
<dependency>
<groupId>org.eclipse.jetty</groupId>
<artifactId>jetty-webapp</artifactId>
<version>${jetty.version}</version>
</dependency>
<dependency>
<groupId>org.eclipse.jetty</groupId>
<artifactId>jetty-http</artifactId>
<version>${jetty.version}</version>
</dependency>
(2)修改hudi-utilities-bundle的pom文件
目的:排除低版本jetty,添加hudi指定版本的jetty
位置:vim /opt/software/hudi-0.12.0/packaging/hudi-utilities-bundle/pom.xml(在405行的位置,修改如下(红色部分))
要指定<dependency>里的<exclusions>剔除hudi-common、hive等模块的jetty依赖,然后添加hudi使用的jetty依赖,否则后面在使用DeltaStreamer工具向hudi表插入数据时,也会报Jetty的错误
<!-- Hoodie -->
<dependency>
<groupId>org.apache.hudi</groupId>
<artifactId>hudi-common</artifactId>
<version>${project.version}</version>
<exclusions>
<exclusion>
<groupId>org.eclipse.jetty</groupId>
<artifactId>*</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.hudi</groupId>
<artifactId>hudi-client-common</artifactId>
<version>${project.version}</version>
<exclusions>
<exclusion>
<groupId>org.eclipse.jetty</groupId>
<artifactId>*</artifactId>
</exclusion>
</exclusions>
</dependency>
<!-- Hive -->
<dependency>
<groupId>${hive.groupid}</groupId>
<artifactId>hive-service</artifactId>
<version>${hive.version}</version>
<scope>${utilities.bundle.hive.scope}</scope>
<exclusions>
<exclusion>
<artifactId>servlet-api</artifactId>
<groupId>javax.servlet</groupId>
</exclusion>
<exclusion>
<artifactId>guava</artifactId>
<groupId>com.google.guava</groupId>
</exclusion>
<exclusion>
<groupId>org.eclipse.jetty</groupId>
<artifactId>*</artifactId>
</exclusion>
<exclusion>
<groupId>org.pentaho</groupId>
<artifactId>*</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>${hive.groupid}</groupId>
<artifactId>hive-service-rpc</artifactId>
<version>${hive.version}</version>
<scope>${utilities.bundle.hive.scope}</scope>
</dependency>
<dependency>
<groupId>${hive.groupid}</groupId>
<artifactId>hive-jdbc</artifactId>
<version>${hive.version}</version>
<scope>${utilities.bundle.hive.scope}</scope>
<exclusions>
<exclusion>
<groupId>javax.servlet</groupId>
<artifactId>*</artifactId>
</exclusion>
<exclusion>
<groupId>javax.servlet.jsp</groupId>
<artifactId>*</artifactId>
</exclusion>
<exclusion>
<groupId>org.eclipse.jetty</groupId>
<artifactId>*</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>${hive.groupid}</groupId>
<artifactId>hive-metastore</artifactId>
<version>${hive.version}</version>
<scope>${utilities.bundle.hive.scope}</scope>
<exclusions>
<exclusion>
<groupId>javax.servlet</groupId>
<artifactId>*</artifactId>
</exclusion>
<exclusion>
<groupId>org.datanucleus</groupId>
<artifactId>datanucleus-core</artifactId>
</exclusion>
<exclusion>
<groupId>javax.servlet.jsp</groupId>
<artifactId>*</artifactId>
</exclusion>
<exclusion>
<artifactId>guava</artifactId>
<groupId>com.google.guava</groupId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>${hive.groupid}</groupId>
<artifactId>hive-common</artifactId>
<version>${hive.version}</version>
<scope>${utilities.bundle.hive.scope}</scope>
<exclusions>
<exclusion>
<groupId>org.eclipse.jetty.orbit</groupId>
<artifactId>javax.servlet</artifactId>
</exclusion>
<exclusion>
<groupId>org.eclipse.jetty</groupId>
<artifactId>*</artifactId>
</exclusion>
</exclusions>
</dependency>
<!-- 增加hudi配置版本的jetty -->
<dependency>
<groupId>org.eclipse.jetty</groupId>
<artifactId>jetty-server</artifactId>
<version>${jetty.version}</version>
</dependency>
<dependency>
<groupId>org.eclipse.jetty</groupId>
<artifactId>jetty-util</artifactId>
<version>${jetty.version}</version>
</dependency>
<dependency>
<groupId>org.eclipse.jetty</groupId>
<artifactId>jetty-webapp</artifactId>
<version>${jetty.version}</version>
</dependency>
<dependency>
<groupId>org.eclipse.jetty</groupId>
<artifactId>jetty-http</artifactId>
<version>${jetty.version}</version>
</dependency>
编译并进入Hudi客户端
编译命令:
mvn clean package -DskipTests -Dspark3.2 -Dflink1.13 -Dscala-2.12 -Dhadoop.version=3.1.3 -Pflink-bundle-shade-hive3
进入hudi-cli说明成功:

编译完成后,相关的包在packaging目录的各个模块中。
Hudi集成Spark的环境准备
Hudi支持的Spark版本:
| Hudi | Supported Spark 3 version |
|---|---|
| 0.12.x | 3.3.x 3.2.x 3.1.x |
| 0.11.x | 3.2.x(default build,spark bundle only) 3.1.x |
| 0.10.x | 3.1.x(default build) 3.0.x |
| 0.7.0-0.9.0 | 3.0.x |
| 0.9.0 and prior | Not supported |
注意:0.11.x不建议使用,如果要用请使用补丁分支:[DO NOT MERGE] 0.11.1 release patch branch by danny0405 · Pull Request #6182 · apache/hudi · GitHub
集成Spark:
其实就是将上述编译好的安装包拷贝到spark下的jars目录中:
cp /opt/software/hudi-0.12.0/packaging/hudi-spark-bundle/target/hudi-spark3.2-bundle_2.12-0.12.0.jar /opt/module/spark-3.2.2/jars
注意:启动Spark之前需要启动Hadoop等相关组件。
Hudi集成Flink的环境准备
Hudi支持的Flink版本:
| Hudi | Supported Flink version |
|---|---|
| 0.12.x | 1.15.x、1.14.x、1.13.x |
| 0.11.x | 1.14.x、1.13.x |
| 0.10.x | 1.13.x |
| 0.9.0 | 1.12.2 |
注意:0.11.x不建议使用,如果要用请使用补丁分支:[DO NOT MERGE] 0.11.1 release patch branch by danny0405 · Pull Request #6182 · apache/hudi · GitHub
集成Flink:
-
将上述编译好的安装包拷贝到flink下的jars目录中:
cp /opt/software/hudi-0.12.0/packaging/hudi-flink-bundle/target/hudi-flink1.13-bundle_2.12-0.12.0.jar /opt/module/flink-1.13.6/lib/ -
拷贝guava包,解决依赖冲突:
cp /opt/module/hadoop-3.1.3/share/hadoop/common/lib/guava-27.0-jre.jar /opt/module/flink-1.13.6/lib/ -
配置Hadoop环境变量:文章来源:https://www.toymoban.com/news/detail-781815.html
sudo vim /etc/profile.d/my_env.sh export HADOOP_CLASSPATH=`hadoop classpath` export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop source /etc/profile.d/my_env.sh
注意:启动Flink之前需要启动Hadoop等相关组件。文章来源地址https://www.toymoban.com/news/detail-781815.html
到了这里,关于Hudi-简介和编译安装的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!