目标检测——上篇🍉
前言🎆
上一章介绍了图像分类,这一章来学习一下目标检测上篇。简单来说,需要得到图像中感兴趣目标的类别信息和位置信息,相比于分类问题,难度有所提升,对图像的描述更加具体。在计算机视觉众多的技术领域中,目标检测(Object Detection)也是一项非常基础的任务,图像分割、物体追踪、关键点检测等通常都要依赖于目标检测。在目标检测时,由于每张图像中物体的数量、大小及姿态各有不同,也就是非结构化的输出,这是与图像分类非常不同的一点,并且物体时常会有遮挡截断,所以物体检测技术也极富挑战性,从诞生以来始终是研究学者最为关注的焦点领域之一。
一、目标检测是什么?
如何从图像中解析出可供计算机理解的信息,是机器视觉的中心问题。深度学习模型由于其强大的表示能力,加之数据量的积累和计算力的进步,成为机器视觉的热点研究方向。
计算机视觉的四大任务:目标分类,目标检测,语义分割,实例分割。难度逐渐递增,对图像特征的提取也更加精细。
- 分类(Classification):即是将图像结构化为某一类别的信息,用事先确定好的类别(string)或实例ID来描述图片。这一任务是最简单、最基础的图像理解任务,也是深度学习模型最先取得突破和实现大规模应用的任务。
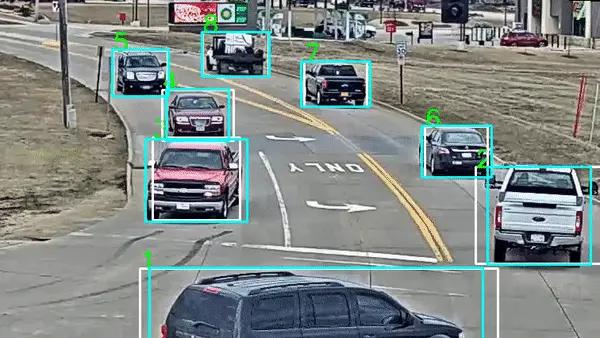
- 检测(Detection):分类任务关心整体,给出的是整张图片的内容描述,而检测则关注特定的物体目标,要求同时获得这一目标的类别信息和位置信息。相比分类,检测给出的是对图片前景和背景的理解,我们需要从背景中分离出感兴趣的目标,并确定这一目标的描述(类别和位置),因而,检测模型的输出是一个列表,列表的每一项使用一个数据组给出检出目标的类别和位置(常用矩形检测框的坐标表示)。
- 分割(Segmentation):分割包括语义分割(semantic segmentation)和实例分割(instance segmentation),前者是对前背景分离的拓展,要求分离开具有不同语义的图像部分,而后者是检测任务的拓展,要求描述出目标的轮廓(相比检测框更为精细)。分割是对图像的像素级描述,它赋予每个像素类别(实例)意义,适用于理解要求较高的场景,如无人驾驶中对道路和非道路的分割。

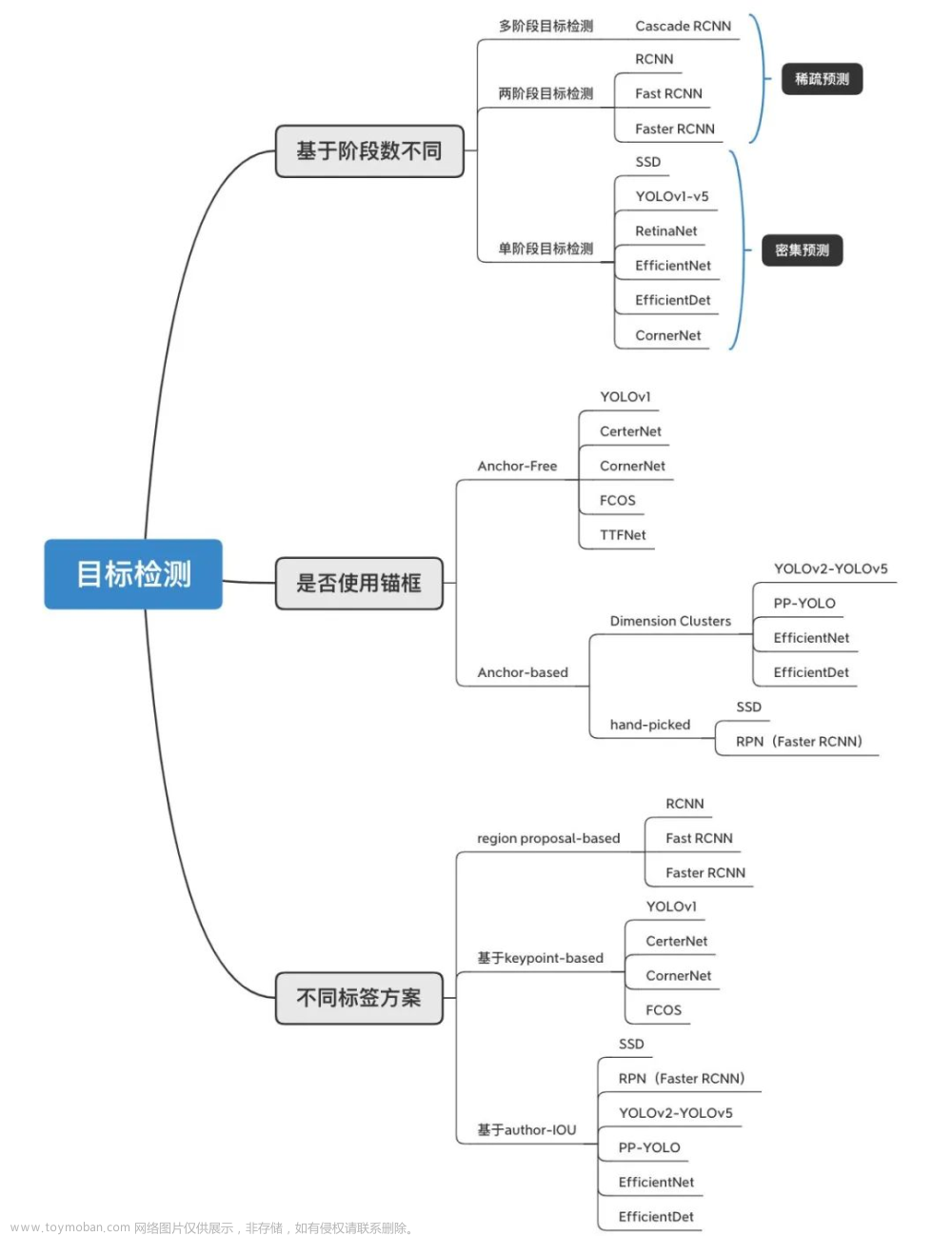
二、目标检测的发展历程
目标检测发展的20年来,从传统的目标检测算法到基于深度学习的目标检测算法,目标检测的精度和速度不断提高,发展历程如下图所示:
-
传统方法 ❤️ :区域选取+特征提取+特征分类。在多尺度图像上应用多尺度窗口进行滑窗,每个roi位置提取出固定长度的特征向量,然后采用SVM进行学习判别。这在小数据上比较奏效;传统方法的工作主要聚焦于设计更好的特征描述子,将roi信息映射为embedding feature。本文不做介绍。

-
Two-stage Detectors(两阶段目标检测器) 🧡 :诸如R-CNN,Fast R-CNN,Faster R-CNN到最新的Mask Scoring R-CNN等网络结构,都属于Two-stage检测方法。目标检测-上篇中介绍。

-
One-stage Detectors(单阶段目标检测器) 💛 :从最早的OverFeat到现在的YOLO,SSD,RetinaNet,YOLOv2,CornerNet等都属于one stage目标检测方法。目标检测-下篇中介绍。

对比:双阶段精度高但速度慢,单精度速度快但精度稍逊。
三、区域卷积神经网络(R-CNN)系列
1.R-CNN
随着CNN网络的出现,目标检测进入了深度学习时代,目标检测技术越来越倾向于网络结构、损失函数和优化方法的设计,人们更加关注使用CNN网络自动提取出图像特征,代替了原来的手工设计特征。目标检测从“冷兵器”时代,过渡到“热兵器”时代,从两阶段目标检测算法到单阶段目标检测算法,再到现在的Anchor Free算法趋势,伴随着硬件计算水平的不断提高,目标检测技术的发展进入了“快车道”。首先介绍深度学习的开山之作—R-CNN算法。
论文链接: Rich feature hierarchies for accurate object detection and semantic segmentation
传统方法–>R-CNN
整体的思路非常简洁明了,不需要像传统算法使用滑动窗口的方式在整张图像上滑动来获取Region Proposal(候选框),而只选择一部分候选框,然后在这些窗口上进行CNN网络。
R-CNN算法流程如下:
- 输入一张图片。
- 使用selective search的方法选出来约2000个Region Proposal,这种方法得到的候选框数量比传统方法少的多。大致是采用图像分割的算法得到的图像块,分割得到候选框。
- 将每一个候选框图片块resize为227*227的大小,然后输入到一个AlexNet CNN网络中,每个候选框图片都能得到一个4096维的特征。
- 为每一类都构建一个SVM分类器,例如你要分十类,就会有10个SVM分类器。将上一步中CNN提取到的特征,输入到这些SVM分类器中,可以得到每一类的分数,从而得到分类结果。
- 同时将第三步中CNN输出的特征向量做回归,纠正Bounding Box框左上右下四个坐标的位置。

代码实现可以参考下面两篇文章:
RCNN代码简单实现
RCNN算法(github代码复现理解)–学习记录2
优点:
- 相比于传统算法精度mAP大幅提升

缺点:
- 训练时间特别长(84小时)
- 测试阶段很慢,VGG16一张图像47s
- 复杂的多阶段训练
2.SPP-Net
SPP-Net是出自2015年发表在IEEE上的论文,在此之前,所有的神经网络都是需要输入固定尺寸的图片,比如224224(ImageNet)、3232(LenNet)、96*96等。这样对于我们希望检测各种大小的图片的时候,需要经过crop,或者warp等一系列操作,这都在一定程度上导致图片信息的丢失和变形,限制了识别精确度。而且,从生理学角度出发,人眼看到一个图片时,大脑会首先认为这是一个整体,而不会进行crop和warp,所以更有可能的是,我们的大脑通过搜集一些浅层的信息,在更深层才识别出这些任意形状的目标。
论文链接:《Spatial Pyramid Pooling in Deep ConvolutionalNetworks for Visual Recognition》
与RCNN对比,两大改进:
- 直接输入整幅图像,所有区域共享卷积计算,在Conv5层输出基础上提取所有区域特征
- 引入空间金字塔池化SPP(Spatial Pyramid Pooling)

SPP-Net算法流程如下:
- 首先通过选择性搜索,对待检测的图片进行搜索出2000个候选窗口。这一步和R-CNN一样。
- 特征提取阶段。这一步就是和R-CNN最大的区别了,这一步骤的具体操作如下:把整张待检测的图片,输入CNN中,进行一次性特征提取,得到feature maps,然后在feature maps中找到各个候选框的区域,再对各个候选框采用金字塔空间池化,提取出固定长度的特征向量。而R-CNN输入的是每个候选框,然后在进入CNN,因为SPP-Net只需要一次对整张图片进行特征提取,速度会大大提升。
- 最后一步也是和R-CNN一样,采用SVM算法进行特征向量分类识别。

缺点:
- 需要存储大量特征
- 训练时间长(25.5小时)
- SPP层之前的所有卷积层不能fine tune
- 复杂的多阶段训练
代码实现可以参考下面的文章:
SPP-Net代码实现
3.Fast R-CNN
受SPPnet启发,rbg在15年发表Fast R-CNN,它的构思精巧,流程更为紧凑,大幅提高目标检测速度。在同样的最大规模网络上,Fast R-CNN和R-CNN相比,训练时间从84小时减少为9.5小时,测试时间从47秒减少为0.32秒。在PASCAL VOC 2007上的准确率相差无几,约在66%-67%之间。
论文链接:Fast R-CNN
与RCNN、SPP-Net对比的改进:
- 更快的train和test
- 更高的mAP
- 现实end-to-end(端到端)单阶段训练
- 所有层参数可以fine tune
- 不需要离线存储特征文件
在SPP-Net的基础上引入2个新技术:
- 感兴趣区域池化
- 多任务损失函数

Fast R-CNN算法流程如下:
- 输入图像。
- 通过深度网络中的卷积层(VGG、Alexnet、Resnet等中的卷积层)对图像进行特征提取,得到图片的特征图;
- 通过选择性搜索算法得到图像的感兴趣区域(通常取2000个)。
- 对得到的感兴趣区域进行ROI pooling(感兴趣区域池化):即通过坐标投影的方法,在特征图上得到输入图像中的感兴趣区域对应的特征区域,并对该区域进行最大值池化,这样就得到了感兴趣区域的特征,并且统一了特征大小。
- 对ROI pooling层的输出(及感兴趣区域对应的特征图最大值池化后的特征)作为每个感兴趣区域的特征向量。
将感兴趣区域的特征向量与全连接层相连,并定义了多任务损失函数,分别与softmax分类器和boxbounding回归器相连,分别得到当前感兴趣区域的类别及坐标包围框。 - 对所有得到的包围框进行非极大值抑制(NMS),得到最终的检测结果。
Fast R-CNN性能提升:
代码实现可以参考下面的文章:
fast rcnn 代码解析
4.Faster R-CNN
经过R-CNN和Fast RCNN的积淀,Ross B. Girshick在2016年提出了新的Faster RCNN,在结构上,Faster RCNN已经将特征抽取(feature extraction),proposal提取,bounding box regression(rect refine),classification都整合在了一个网络中,使得综合性能有较大提高,在检测速度方面尤为明显。
论文地址:Faster R-CNN:Towards Real-Time Object Detection with Region Proposal Networks
改进点:
- 集成Region Proposal Network(RPN)网络
- Faster R-CNN = Fast RCNN + RPN
- 取代离线Selective Search模块
- 进一步共享卷积层计算
- 基于Attention注意机制
- Region proposals量少质优(300左右)

Faster RCNN其实可以分为4个主要内容:
- Conv layers。作为一种CNN网络目标检测方法,Faster RCNN首先使用一组基础的conv+relu+pooling层提取image的feature maps。该feature maps被共享用于后续RPN层和全连接层。
- Region Proposal Networks。RPN网络用于生成region proposals。该层通过softmax判断anchors属于positive或者negative,再利用bounding box regression修正anchors获得精确的proposals。
- Roi Pooling。该层收集输入的feature maps和proposals,综合这些信息后提取proposal feature maps,送入后续全连接层判定目标类别。
- Classification。利用proposal feature maps计算proposal的类别,同时再次bounding box regression获得检测框最终的精确位置。
算法整体架构可以阅读:Faster RCNN 实现思路详解
Faster R-CNN性能提升:
部分代码实现:
FasterRCNN.py:
import tensorflow as tf
import numpy as np
from model.rpn import RegionProposalNetwork, Extractor
from model.roi import RoIHead
from utils.anchor import loc2bbox, AnchorTargetCreator, ProposalTargetCreator
def _smooth_l1_loss(pred_loc, gt_loc, in_weight, sigma):
# pred_loc, gt_loc, in_weight
sigma2 = sigma ** 2
sigma2 = tf.constant(sigma2, dtype=tf.float32)
diff = in_weight * (pred_loc - gt_loc)
abs_diff = tf.math.abs(diff)
abs_diff = tf.cast(abs_diff, dtype=tf.float32)
flag = tf.cast(abs_diff.numpy() < (1./sigma2), dtype=tf.float32)
y = (flag * (sigma2 / 2.) * (diff ** 2) + (1 - flag) * (abs_diff - 0.5 / sigma2))
return tf.reduce_sum(y)
def _fast_rcnn_loc_loss(pred_loc, gt_loc, gt_label, sigma):
"""
:param pred_loc: 1,38,50,36
:param gt_loc: 17100,4
:param gt_label: 17100
"""
idx = gt_label > 0
idx = tf.stack([idx, idx, idx, idx], axis=1)
idx = tf.reshape(idx, [-1, 4])
in_weight = tf.cast(idx, dtype=tf.int32)
loc_loss = _smooth_l1_loss(pred_loc, gt_loc, in_weight.numpy(), sigma)
# Normalize by total number of negative and positive rois.
loc_loss /= (tf.reduce_sum(tf.cast(gt_label >= 0, dtype=tf.float32))) # ignore gt_label==-1 for rpn_loss
return loc_loss
class FasterRCNN(tf.keras.Model):
def __init__(self, n_class, pool_size):
super(FasterRCNN, self).__init__()
self.n_class = n_class
self.extractor = Extractor()
self.rpn = RegionProposalNetwork()
self.head = RoIHead(n_class, pool_size)
self.score_thresh = 0.7
self.nms_thresh = 0.3
def __call__(self, x):
img_size = x.shape[1:3]
feature_map, rpn_locs, rpn_scores, rois, roi_score, anchor = self.rpn(x)
roi_cls_locs, roi_scores = self.head(feature_map, rois, img_size)
return roi_cls_locs, roi_scores, rois
def predict(self, imgs):
bboxes = []
labels = []
scores = []
img_size = imgs.shape[1:3]
# (2000,84) (2000,21) (2000,4)
roi_cls_loc, roi_score, rois = self(imgs)
prob = tf.nn.softmax(roi_score, axis=-1)
prob = prob.numpy()
roi_cls_loc = roi_cls_loc.numpy()
roi_cls_loc = roi_cls_loc.reshape(-1, self.n_class, 4) # 2000, 21, 4
for label_index in range(1, self.n_class):
cls_bbox = loc2bbox(rois, roi_cls_loc[:, label_index, :])
# clip bounding box
cls_bbox[:, 0::2] = tf.clip_by_value(cls_bbox[:, 0::2], clip_value_min=0, clip_value_max=img_size[0])
cls_bbox[:, 1::2] = tf.clip_by_value(cls_bbox[:, 1::2], clip_value_min=0, clip_value_max=img_size[1])
cls_prob = prob[:, label_index]
mask = cls_prob > 0.05
cls_bbox = cls_bbox[mask]
cls_prob = cls_prob[mask]
keep = tf.image.non_max_suppression(cls_bbox, cls_prob, max_output_size=-1, iou_threshold=self.nms_thresh)
if len(keep) > 0:
bboxes.append(cls_bbox[keep.numpy()])
# The labels are in [0, self.n_class - 2].
labels.append((label_index - 1) * np.ones((len(keep),)))
scores.append(cls_prob[keep.numpy()])
if len(bboxes) > 0:
bboxes = np.concatenate(bboxes, axis=0).astype(np.float32)
labels = np.concatenate(labels, axis=0).astype(np.float32)
scores = np.concatenate(scores, axis=0).astype(np.float32)
return bboxes, labels, scores
class FasterRCNNTrainer(tf.keras.Model):
def __init__(self, faster_rcnn):
super(FasterRCNNTrainer, self).__init__()
self.faster_rcnn = faster_rcnn
self.rpn_sigma = 3.0
self.roi_sigma = 1.0
# target creator create gt_bbox gt_label etc as training targets.
self.anchor_target_creator = AnchorTargetCreator()
self.proposal_target_creator = ProposalTargetCreator()
def __call__(self, imgs, bbox, label, scale, training=None):
_, H, W, _ = imgs.shape
img_size = (H, W)
features = self.faster_rcnn.extractor(imgs, training=training)
rpn_locs, rpn_scores, roi, anchor = self.faster_rcnn.rpn(features, img_size, scale, training=training)
rpn_score = rpn_scores[0]
rpn_loc = rpn_locs[0]
sample_roi, gt_roi_loc, gt_roi_label = self.proposal_target_creator(roi, bbox.numpy(), label.numpy())
roi_cls_loc, roi_score = self.faster_rcnn.head(features, sample_roi, img_size, training=training)
# RPN losses
gt_rpn_loc, gt_rpn_label = self.anchor_target_creator(bbox.numpy(), anchor, img_size)
gt_rpn_label = tf.constant(gt_rpn_label, dtype=tf.int32)
gt_rpn_loc = tf.constant(gt_rpn_loc, dtype=tf.float32)
rpn_loc_loss = _fast_rcnn_loc_loss(rpn_loc, gt_rpn_loc, gt_rpn_label, self.rpn_sigma)
idx_ = gt_rpn_label != -1
rpn_cls_loss = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)(gt_rpn_label[idx_], rpn_score[idx_])
# ROI losses
n_sample = roi_cls_loc.shape[0]
roi_cls_loc = tf.reshape(roi_cls_loc, [n_sample, -1, 4])
idx_ = [[i, j] for i, j in zip(tf.range(n_sample), tf.constant(gt_roi_label))]
roi_loc = tf.gather_nd(roi_cls_loc, idx_)
gt_roi_label = tf.constant(gt_roi_label)
gt_roi_loc = tf.constant(gt_roi_loc)
roi_loc_loss = _fast_rcnn_loc_loss(roi_loc, gt_roi_loc, gt_roi_label, self.roi_sigma)
idx_ = gt_roi_label != 0
roi_cls_loss = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False)(gt_roi_label[idx_], roi_score[idx_])
return rpn_loc_loss, rpn_cls_loss, roi_loc_loss, roi_cls_loss
RPN网络:
import tensorflow as tf
import numpy as np
from utils.anchor import generate_anchor_base, ProposalCreator, _enumerate_shifted_anchor
class Extractor(tf.keras.Model):
def __init__(self):
super(Extractor, self).__init__()
# conv1
self.conv1_1 = tf.keras.layers.Conv2D(32, 3, activation='relu', padding='same')
self.conv1_2 = tf.keras.layers.Conv2D(32, 3, activation='relu', padding='same')
self.pool1 = tf.keras.layers.MaxPooling2D(2, strides=2, padding='same')
# conv2
self.conv2_1 = tf.keras.layers.Conv2D(64, 3, activation='relu', padding='same')
self.conv2_2 = tf.keras.layers.Conv2D(64, 3, activation='relu', padding='same')
self.pool2 = tf.keras.layers.MaxPooling2D(2, strides=2, padding='same')
# conv3
self.conv3_1 = tf.keras.layers.Conv2D(128, 3, activation='relu', padding='same')
self.conv3_2 = tf.keras.layers.Conv2D(128, 3, activation='relu', padding='same')
self.conv3_3 = tf.keras.layers.Conv2D(128, 3, activation='relu', padding='same')
self.pool3 = tf.keras.layers.MaxPooling2D(2, strides=2, padding='same')
# conv4
self.conv4_1 = tf.keras.layers.Conv2D(256, 3, activation='relu', padding='same')
self.conv4_2 = tf.keras.layers.Conv2D(256, 3, activation='relu', padding='same')
self.conv4_3 = tf.keras.layers.Conv2D(256, 3, activation='relu', padding='same')
self.pool4 = tf.keras.layers.MaxPooling2D(2, strides=2, padding='same')
# conv5
self.conv5_1 = tf.keras.layers.Conv2D(512, 3, activation='relu', padding='same')
self.conv5_2 = tf.keras.layers.Conv2D(512, 3, activation='relu', padding='same')
self.conv5_3 = tf.keras.layers.Conv2D(512, 3, activation='relu', padding='same')
def __call__(self, imgs, training=None):
h = self.pool1(self.conv1_2(self.conv1_1(imgs)))
h = self.pool2(self.conv2_2(self.conv2_1(h)))
h = self.pool3(self.conv3_3(self.conv3_2(self.conv3_1(h))))
h = self.pool4(self.conv4_3(self.conv4_2(self.conv4_1(h))))
h = self.conv5_3(self.conv5_2(self.conv5_1(h)))
return h
class RegionProposalNetwork(tf.keras.Model):
def __init__(self, ratios=[0.5, 1, 2], anchor_scales=[8, 16, 32]):
super(RegionProposalNetwork, self).__init__()
# region_proposal_conv
self.region_proposal_conv = tf.keras.layers.Conv2D(512, kernel_size=3, activation=tf.nn.relu, padding='same')
# Bounding Boxes Regression layer
self.loc = tf.keras.layers.Conv2D(36, kernel_size=1, padding='same')
# Output Scores layer
self.score = tf.keras.layers.Conv2D(18, kernel_size=1, padding='same')
self.anchor = generate_anchor_base(anchor_scales=anchor_scales, ratios=ratios)
self.proposal_layer = ProposalCreator()
def __call__(self, x, img_size, scale, training=None):
n, hh, ww, _ = x.shape
anchor = _enumerate_shifted_anchor(np.array(self.anchor), 16, hh, ww)
n_anchor = anchor.shape[0] // (hh * ww)
h = self.region_proposal_conv(x)
rpn_loc = self.loc(h) # [1, 38, 50, 36]
rpn_loc = tf.reshape(rpn_loc, [n, -1, 4])
rpn_score = self.score(h) # [1, 38, 50, 18]
# [1, 38, 50, 9, 2]
rpn_softmax_score = tf.nn.softmax(tf.reshape(rpn_score, [n, hh, ww, n_anchor, 2]), axis=-1)
rpn_fg_score = rpn_softmax_score[:, :, :, :, 1]
rpn_fg_score = tf.reshape(rpn_fg_score, [n, -1])
rpn_score = tf.reshape(rpn_score, [n, -1, 2])
roi = self.proposal_layer(rpn_loc[0].numpy(), rpn_fg_score[0].numpy(), anchor, img_size, scale)
return rpn_loc, rpn_score, roi, anchor
ROI.py:
import tensorflow as tf
def roi_pooling(feature, rois, img_size, pool_size):
"""
用tf.image.crop_and_resize实现roi_align
:param feature: 特征图[1, hh, ww, c]
:param rois: 原图的rois
:param img_size: 原图的尺寸
:param pool_size: align后的尺寸
"""
# 所有需要pool的框在batch中的对应图片序号,由于batch_size为1,因此box_ind里面的值都为0
box_ind = tf.zeros(rois.shape[0], dtype=tf.int32)
# ROI box coordinates. Must be normalized and ordered to [y1, x1, y2, x2]
# 在这里取到归一化框的坐标时需要的图片尺度
normalization = tf.cast(tf.stack([img_size[0], img_size[1], img_size[0], img_size[1]], axis=0), dtype=tf.float32)
# 归一化框的坐标为原图的0~1倍尺度
boxes = rois / normalization
# 进行ROI pool,之所以需要归一化框的坐标是因为tf接口的要求
# 2000,7,7,256
pool = tf.image.crop_and_resize(feature, boxes, box_ind, crop_size=pool_size)
return pool
class RoIPooling2D(tf.keras.Model):
def __init__(self, pool_size):
super(RoIPooling2D, self).__init__()
self.pool_size = pool_size
def __call__(self, feature, rois, img_size):
return roi_pooling(feature, rois, img_size, self.pool_size)
class RoIHead(tf.keras.Model):
def __init__(self, n_class, pool_size):
# n_class includes the background
super(RoIHead, self).__init__()
self.fc = tf.keras.layers.Dense(4096)
self.cls_loc = tf.keras.layers.Dense(n_class * 4)
self.score = tf.keras.layers.Dense(n_class)
self.n_class = n_class
self.roi = RoIPooling2D(pool_size)
def __call__(self, feature, rois, img_size, training=None):
rois = tf.constant(rois, dtype=tf.float32)
pool = self.roi(feature, rois, img_size)
pool = tf.reshape(pool, [rois.shape[0], -1])
fc = self.fc(pool)
roi_cls_locs = self.cls_loc(fc)
roi_scores = self.score(fc)
return roi_cls_locs, roi_scores
train.py:文章来源:https://www.toymoban.com/news/detail-781944.html
import datetime
from utils.config import Config
from model.fasterrcnn import FasterRCNNTrainer, FasterRCNN
import tensorflow as tf
from utils.data import Dataset
physical_devices = tf.config.experimental.list_physical_devices('GPU')
assert len(physical_devices) > 0, "Not enough GPU hardware devices available"
tf.config.experimental.set_memory_growth(physical_devices[0], True)
config = Config()
config._parse({})
print("读取数据中....")
dataset = Dataset(config)
frcnn = FasterRCNN(21, (7, 7))
print('model construct completed')
"""
feature_map, rpn_locs, rpn_scores, rois, roi_indices, anchor = frcnn.rpn(x, scale)
'''
feature_map : (1, 38, 50, 256) max= 0.0578503
rpn_locs : (1, 38, 50, 36) max= 0.058497224
rpn_scores : (1, 17100, 2) max= 0.047915094
rois : (2000, 4) max= 791.0
roi_indices :(2000,) max= 0
anchor : (17100, 4) max= 1154.0387
'''
bbox = bboxes
label = labels
rpn_score = rpn_scores
rpn_loc = rpn_locs
roi = rois
proposal_target_creator = ProposalTargetCreator()
sample_roi, gt_roi_loc, gt_roi_label, keep_index = proposal_target_creator(roi, bbox, label)
roi_cls_loc, roi_score = frcnn.head(feature_map, sample_roi, img_size)
'''
roi_cls_loc : (128, 84) max= 0.062198948
roi_score : (128, 21) max= 0.045144305
'''
anchor_target_creator = AnchorTargetCreator()
gt_rpn_loc, gt_rpn_label = anchor_target_creator(bbox, anchor, img_size)
rpn_loc_loss = _fast_rcnn_loc_loss(rpn_loc, gt_rpn_loc, gt_rpn_label, 3)
idx_ = gt_rpn_label != -1
rpn_cls_loss = tf.keras.losses.SparseCategoricalCrossentropy()(gt_rpn_label[idx_], rpn_score[0][idx_])
# ROI losses
n_sample = roi_cls_loc.shape[0]
roi_cls_loc = tf.reshape(roi_cls_loc, [n_sample, -1, 4])
idx_ = [[i,j] for i,j in zip(range(n_sample), gt_roi_label)]
roi_loc = tf.gather_nd(roi_cls_loc, idx_)
roi_loc_loss = _fast_rcnn_loc_loss(roi_loc, gt_roi_loc, gt_roi_label, 1)
roi_cls_loss = tf.keras.losses.SparseCategoricalCrossentropy()(gt_roi_label, roi_score)
"""
model = FasterRCNNTrainer(frcnn)
optimizer = tf.keras.optimizers.SGD(learning_rate=1e-3, momentum=0.9)
current_time = datetime.datetime.now().strftime("%Y%m%d-%H%M%S")
log_dir = 'logs/' + current_time
summary_writer = tf.summary.create_file_writer(log_dir)
epochs = 12
loss = []
for epoch in range(epochs):
for i in range(len(dataset)):
img, bboxes, labels, scale = dataset[1]
bboxes = tf.cast(bboxes, dtype=tf.float32)
labels = tf.cast(labels, dtype=tf.float32)
with tf.GradientTape() as tape:
rpn_loc_l, rpn_cls_l, roi_loc_l, roi_cls_l = model(img, bboxes, labels, scale, training=True)
total_loss = rpn_loc_l + rpn_cls_l + roi_loc_l + roi_cls_l
grads = tape.gradient(total_loss, model.trainable_variables)
optimizer.apply_gradients(zip(grads, model.trainable_variables))
if i % 1 == 0:
with summary_writer.as_default():
tf.summary.scalar('rpn_loc_loss', float(rpn_loc_l), step=i + epoch * len(dataset))
tf.summary.scalar('rpn_cls_loss', float(rpn_cls_l), step=i + epoch * len(dataset))
tf.summary.scalar('roi_loc_loss', float(roi_loc_l), step=i + epoch * len(dataset))
tf.summary.scalar('roi_cls_loss', float(roi_cls_l), step=i + epoch * len(dataset))
if i % 1000 == 0:
model.save_weights('frcnn.h5')
总结🎨
今天介绍了第二类计算机视觉任务-目标检测的上半部分,主要为两阶段目标检测算法。下一节将会介绍更加火爆的一阶段目标检测算法,包括近年来比较火的YOLO算法系列,敬请期待🚗文章来源地址https://www.toymoban.com/news/detail-781944.html
到了这里,关于【深度学习】(四)目标检测——上篇的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!