Python应用开发——爬取网页图片
前言
当我们需要从网页上面下载很多图片的时候,一个一个手动保存实在是太累人了。那么有没有批量下载的办法呢?
答案是有的,Python爬虫就可以完美的做到这一点,而且作为一个Python的初学者,我可以很负责任的告诉你,这门语言入门挺简单的,特别是对于那些有其他编程语言经验的人。
1 爬取原理讲解
提示:没耐心看原理的同学可以直接跳到第2步实战。
网页上的图片其实都是存到一个服务器上面的,每张图片都会有一个对应的下载网址。
当我们在浏览器上打开一个包含很多图片的网址时,这个网址其实不是这些图片实际的地址,而是把所有图片的真实地址都包含在这个网址上面了。所以当我们在图片上面右键点击保存图片,其实是通过访问这张图片的下载网址来下载图片的。那么同样的,我们用Python爬取图片也是基于这个操作。
总而言之,爬取网页图片的根本方法就是在这个网页上找到图片的原图地址,然后下载保存。
实际操作的大概流程如下:
- 访问一个包含图片的网址。
- 分析这个网页的HTML源码,找到目标图片的下载地址。
- 通过图片地址下载保存到电脑上。
- 通过这个网址得到下一页或者下一个套图的网址。
- 继续重复上面4个操作。
1.1 查看网页源代码
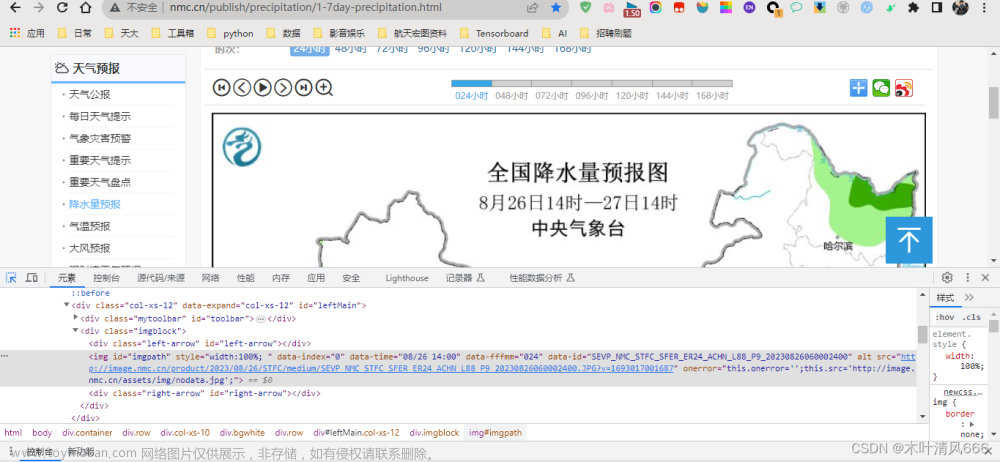
我们在浏览器上面随便打开一个有图片的网页,按F12就会弹出网页源代码。左边是网页的内容,右边则是HTML代码。
比如我打开一个网页(域名:Xgyw.Top,我这里只是举个例子,这个网站的网址是定期变的,过一段时间可能就打不开了)。
1.2 分析网页源码并制定对应的爬取方案
1) 找到目标图片的相关信息
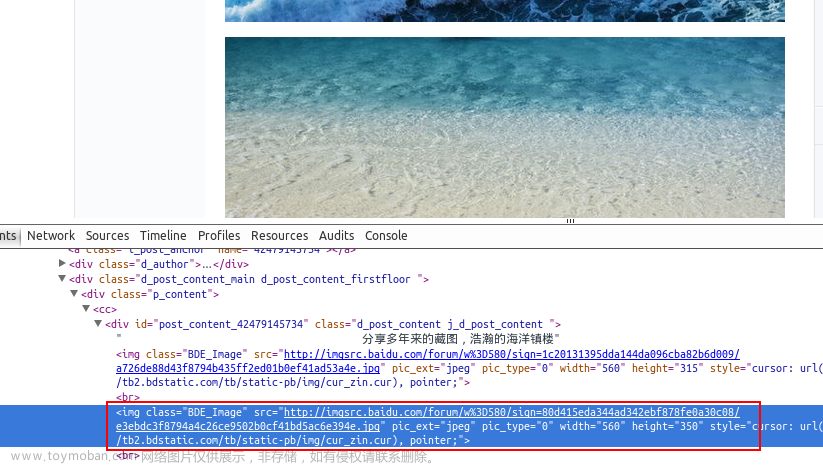
刚打开html源码的时候,很多内容是折叠起来的,我们可以展开,然后在这些源码里面找到我们需要下载的图片相关的信息。
网页里面的内容其实是一个个模块拼起来的,当鼠标放在某一行代码上面,这段源码对应的网页内容会出现一个蓝色的框框,通过这个提示我们可以很快的找到目标图片对应的那段代码。
2) 从图片信息中提取目标图片的下载地址
找到图片的信息之后就需要根据实际情况分析了,有些网页是直接把原图的完整网址放在这里了,这种就比较简单,我们直接把网址提取出来,然后访问这个网站下载图片即可。
但是有些网页是不会这么容易就让你得到这个网址的,比如我上面这个网站,一个网页有3张图片,但是都没有完整的提供图片地址,不过这个标签里面有一个src的信息,这里面的内容明显就跟图片的网址有关联。
我们这时可以在网页的图片上右键,在新标签页中打开图片,然后查看一下原图的网址。通过对比,我发现这里src的信息正是原图地址后面的一部分,而前面那部分则是一个固定的内容。也就是说这里他把一个完整的地址拆成了两部分,网页源代码里面只有后半部分的信息,很鸡贼。
但是找到规律了之后就好办了,我们只需要在Python的代码里面把这两段地址拼接起来就能得到一个完整的地址了。
提示:如果你没办法从这个网页中得到目标图片的地址,那就没办法继续往下走。
比如这个网页对图片做了加密,需要登录或者VIP权限才能查看到图片的信息,而你又没有的时候,就没办法通过这种方式爬取到目标图片了。
1.3 完善爬取流程和细节
当我们能够解决原图地址的问题,那么爬取就不是什么难事了,我们下一步需要做的是完善整个爬取的流程,以便于批量下载。
1) 根据网页排版确定哪些是目标图片
不同的网页排版可能会不同,比如有些网站一个网页里面只放3张图片,有的则放5张或者更多,而且除了目标图片边上可能也会有一些小的预览图,下一页等等。
我们需要在这些信息中准确的找到目标图片,这个就需要根据实际爬取的网页来编写爬取的代码了。方法是有很多的,要灵活使用,只要能达到目的就行,没有规定说一定要用哪种方法。
2) 爬取完一个网页之后自动查找下一个目标
图片比较多的时候,不可能把所有图片都放在一个网页上,所以很多时候需要跳转到下一页,这个时候我们就需要在HTML源码上面找到下一页的入口地址,或者通过观察每一页的网址并从中找到排列规律,然后跳转到下一个网页继续爬。
具体怎么找要看这个网页的源码是怎样的,原理跟查找原图地址是一样的,这里就不在过多赘述了。
3) 爬取目标图片的命名以及保存路径
我们下载完一张图片之后肯定是需要命名以及保存的,命名以及路径如果设置的不合理,到时候下载完就不好查找了,特别是一次性批量下载很多套图的时候,如果都堆到一个文件夹下面或者随机命名,到时候想找一张图片就跟大海捞针一样。
因此,我们需要提前想好文件的结构和图片的命名方式。
比如:很多网页上面本身就对套图进行了命名,那么我们就可以按照网页上面的命名创建文件夹,然后再把相应的图片放到这个文件夹下,按序号排列图片。
当然了,我这里只是举个例子,具体实施的时候你爱怎么搞就怎么搞。
4) 伪装成浏览器访问,防止网页有反爬机制
有些网站是有反爬机制的,如果它检查你的请求参数,发现不符合它的规则时,那么它就不会返回正确的信息给你,这也就没办法获取到目标图片的信息了。
因此,我们有时候需要伪装成正常的浏览器访问。
2 实战演练
2.1 PyCharm下载安装
这个是一个比较受欢迎的Python开发IDE,用起来也是十分的方便,具体怎么下载安装和使用,这里就不讲解了,网上都能找到教程,不懂的同学请自行查阅资料。
2.2 安装相应依赖包(类库)
下面是需要用到的一些库以及发布这篇博客时当前的版本,其中有些是Python自带的标准库,不需要再安装了。
不会怎么安装库的同学请自行查找相关教程,可以在pycharm上直接装,也可以借助pip装。
| package | version |
|---|---|
| os | 注:python标准库,无需安装 |
| re | 注:python标准库,无需安装 |
| time | 注:python标准库,无需安装 |
| requests | v2.28.1 |
| bs4 | v0.01 |
2.3 编写代码
我这里还是以上面讲的那个很顶的网站为例,编写相应的爬取的代码。
其他的网站其实都是大同小异的,关键是要灵活运用。
根据上面讲解的原理以及对这个网站的分析,先写第一版代码,主要是确保目标图片能够正确的被下载保存,如果流程走通了,我们后面第二版再去完善一些细节,如果走不通,那就要重新分析,查找失败的原因。
第一版测试代码:
# 第一版
#-*-coding:utf-8-*-
import os
import re
import time
import requests
import bs4
from bs4 import BeautifulSoup
# 手动写入目标套图的首页地址
download_url = "https://www.xgmn09.com/XiaoYu/XiaoYu23172.html"
# 手动写入目标套图的页数
page_num = 25
# 创建一个文件夹用来保存图片
file_name = "测试图库"
# 目标图片下载地址的前半部分(固定不变那部分,后半段是变化的,需要解析网页得到)
imgae_down_url_1 = "https://jpxgyw.net"
# 创建文件夹
def CreateFolder(file):
"""创建存储数据文件夹"""
flag = 1
while flag == 1: # 若文件已存在,则不继续往下走以免覆盖了原文件
if not os.path.exists(file):
os.mkdir(file)
flag = 0
else:
print('该文件已存在,请重新输入')
flag = 1
time.sleep(1)
# 返回文件夹的路径,这里直接放这工程的根目录下
path = os.path.abspath(file) + "\\"
return path
# 下载图片
def DownloadPicture(download_url, list, path):
# 访问目标网址
r = requests.get(url=download_url, timeout=20)
r.encoding = r.apparent_encoding
soup = BeautifulSoup(r.text, "html.parser")
# 解析网址,提取目标图片相关信息,注:这里的解析方法是不固定的,可以根据实际的情况灵活使用
p = soup.find_all("p")
tag = p[0].find_all("img") # 得到该页面目标图片的信息
# 下载图片
j = 0
for i in range(list, list + 3):
if(j < len(tag) and tag[j].attrs['src'] != None) :
img_name = str(i) + ".jpg" # 以数字命名图片,图片格式为jpg
# 获取目标图片下载地址的后半部分
imgae_down_url_2 = tag[j].attrs['src']
j = j + 1
# 把目标图片地址的前后两部分拼接起来,得到完整的下载地址
imgae_down_url = imgae_down_url_1 + imgae_down_url_2
print("imgae_down_url: ", imgae_down_url)
# 下载图片
try:
img_data = requests.get(imgae_down_url)
except:
continue
# 保存图片
img_path = path + img_name
with open(img_path,'wb') as fp:
fp.write(img_data.content)
print(img_name, " ******下载完成!")
# 主函数
if __name__ == "__main__":
# 创建保存数据的文件夹
path = CreateFolder(file_name)
print("创建文件夹成功: ", path)
# 按页下载图片
for i in range(0, page_num):
if i == 0 :
page_url = download_url # 首页网址,注:因为这个网站首页和后面那些页面网址的规则不一样,所以这里要区分开来
else :
page_url = download_url[:-5] + "_" + str(i) + ".html" # 第2页往后的网址,都是用数字来排布页面
# 下载图片
# print("page_url: ", page_url)
DownloadPicture(page_url, i * 3, path) # 注:这个网站每一页最多是3张图片,每张图片我都用数字命名
print("全部下载完成!", "共" + str(len(os.listdir(path))) + "张图片")
运行测试:
运行之后我们可以通过输出的log看到每张图片的下载地址以及图片保存的一个情况,并且在项目工程的根目录下我们可以看到新建的这个文件夹以及里面的图片。
开始运行:
运行结束:
在工程根目录下自动创建的文件夹:
爬取到的图片:
图片这里就不放出来了,因为这个图片的问题我的文章发布了10天就被下架了,还有就是这个网站最近好像访问不了了,不知道是怎么回事,反正大家学方法就行了,还有很多其他网站可以实践。
至此,初步的流程是已经走通了。
2.4 补充细节和优化
前面的测试已经验证了这个流程是OK的,那么我们现在就可以在这个基础上继续补充一些细节,完善这套代码了。
我主要完善了以下几点:
- 文件保存的路径改成自定义,之前的代码是直接放在工程的根目录下的。
- 修改了文件夹的命名,由原来固定写死的命名改为从网页获取套图的名称,方便了我们后续批量操作。
- 套图的页面总数通过解析该套图的首页得到,不需要再手动输入了。
- 下载图片的时候增加了超时重连,防止意外出现的网络问题导致下载失败从而丢失某些图片。
- 在爬取图片之前先检查一下输入的地址,如果不是该套图的首页,则按这个网站的规则改成首页的地址。
注:这样一来我只需要输入该套图的任意一页地址,就能正确爬取到这个套图。 - 每个网页爬取的图片数量不再是固定的,而是根据这个网页本身存放目标图片的数量来爬取,动态变化。
注:之前按照我的分析,除了最后一页是不固定的,其他的页面都是3张图片,但是后来发现并不是所有套图都这样排版,如果都按3张爬取,虽然也不会漏,但是图片的命名排序中间会空一些数字,比如前面1-9都是正常排序,然后直接跳过10,从11继续往后排了。 - 增加了请求的headers,伪造成浏览器访问。
注:实际上这一步也可以不用,因为上面的第一版代码没加这个也能正常爬取,说明这个网站应该是没有反爬机制的。不过不管爬什么网页最好都加上,不然可能会有其他的意外。
第二版测试代码:
# 第二版
# -*-coding:utf-8-*-
import os
import re
import time
import requests
import bs4
from bs4 import BeautifulSoup
# 手动写入目标套图的首页地址
download_url = "https://www.xgmn09.com/XiaoYu/XiaoYu23172.html"
# 这里不需要手动输入页面数量了,可以通过解析首页地址得到总页面数
# page_num = 25
# 文件保存的绝对路径(D:\imgae\test_file),注:这个路径上面的文件夹一定是要已经创建好了的,不然运行会报错
file_path = "D:\\imgae\\test_file"
# 文件名通过网页得到,注:以网页上套图的名字命名
file_name = " "
# 目标图片下载地址的前半部分,注:固定不变那部分,后半段是变化的,需要解析网页得到
imgae_down_url_1 = "https://jpxgyw.net"
# 修改请求headers以伪装成浏览器访问,从而绕开网站的反爬机制获取正确的页面,注:这个需要根据自己浏览器的实际的信息改
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.54 Safari/537.36"
}
# 访问网页并返回HTML相关的信息
def getHTMLText(url, headers):
# 向目标服务器发起请求并返回响应
try:
r = requests.get(url=url, headers=headers, timeout=20)
r.encoding = r.apparent_encoding
soup = BeautifulSoup(r.text, "html.parser")
return soup
except:
return ""
# 获取该套图的名称和总页面数
def getFileName(url, headers):
# 从目标地址上面获取套图的名称
soup = getHTMLText(url, headers)
head1 = soup.find_all("header")
h1 = head1[1].find_all("h1")
name = h1[0].text
pagination = soup.find_all("div", "pagination")
a = pagination[0].find_all("a")
page = int(a[len(a) - 2].text)
return name, page
# 创建文件夹
def CreateFolder(file_name):
flag = True
num = 0
while flag == 1:
if num <= 0:
file = file_path + '\\' + file_name # 如果文件夹不存在,则创建文件夹
else:
file = file_path + '\\' + str(num) + '_' + file_name # 如果文件夹已存在,则在文件夹前面加上数字,防止覆盖掉以前保存过的文件
if not os.path.exists(file):
os.mkdir(file)
flag = False
else:
print('该文件名已存在,已重新命名')
flag = True
num += 1
# time.sleep(1)
# 返回文件存放的路径
path = os.path.abspath(file) + '\\'
return path
# 下载图片
def DownloadPicture(url, img_num, path):
# 访问目标网址
soup = getHTMLText(url, headers)
# 解析网址,提取目标图片相关信息,注:这里的解析方法是不固定的,可以根据实际的情况灵活使用
p = soup.find_all("p")
tag = p[0].find_all("img") # 得到该页面目标图片的信息
# 下载图片
for i in range(0, len(tag)):
if (tag[i].attrs['src'] != None):
# 解析网址,得到目标图片的下载地址
imgae_down_url_2 = tag[i].attrs['src'] # 获取目标图片下载地址的后半部分
imgae_url = imgae_down_url_1 + imgae_down_url_2 # 把目标图片地址的前后两部分拼接起来,得到完整的下载地址
print("imgae_url: ", imgae_url)
# 给图片命名
img_num += 1
name = tag[i].attrs['alt'] + '_' + str(img_num) # 获取img标签的alt属性,用来给保存的图片命名,图片格式为jpg
img_name = name + ".jpg"
# 下载图片
timeout = 5 # 超时重连次数
while timeout > 0:
try:
img_data = requests.get(url=imgae_url, headers=headers, timeout=30)
# 保存图片
img_path = path + img_name
with open(img_path, 'wb') as fp:
fp.write(img_data.content)
print(img_name, "******下载完成!")
timeout = 0
except:
print(img_name, "******等待超时,下载失败!")
time.sleep(1)
timeout -= 1
return img_num
# 主函数
if __name__ == "__main__":
# 记录下载时间
start = time.time()
# 检查网址,如果输入的网址不是首页,则改成首页地址
result = download_url.find('_')
if(result != -1):
new_str = ''
check_flag = 1
for i in range(0, len(download_url)):
if(download_url[i] != '_' and check_flag):
new_str = new_str + download_url[i]
else:
if(download_url[i] == '_'):
check_flag = 0
if(download_url[i] == '.'):
new_str = new_str + download_url[i]
check_flag = 1
download_url = new_str
print("new download_url: ", download_url)
# 创建保存数据的文件夹
file_name, page_num = getFileName(download_url, headers) # 获取套图名称
print("page_num: ", page_num)
path = CreateFolder(file_name)
print("创建文件夹成功: ", path)
# 按页下载图片
image_num = 0 # 当前累计下载图片总数
for i in range(0, int(page_num)):
if i == 0:
page_url = download_url # 首页网址,注:因为这个网站首页和后面那些页面网址的规则不一样,所以这里要区分开来
else:
page_url = download_url[:-5] + "_" + str(i) + ".html" # 第2页往后的网址,都是用数字来排布页面
# 下载图片
print("page_url: ", page_url)
image_num = DownloadPicture(page_url, image_num, path)
# image_num = num # 每下载完一页图片就累计当前下载图片总数
print("全部下载完成!", "共" + str(len(os.listdir(path))) + "张图片")
# 打印下载总耗时
end = time.time()
print("共耗时" + str(end - start) + "秒")
2.5 运行测试
运行结果:
上述需要完善的功能均已实现,nice!
到这里的话基本功能算是完成了,我们先设置好保存的路径,然后每次只需输入一个套图的地址就可以自动下载保存好。
其实这个代码还有很多地方可以继续优化的,不过我只是业余玩一下,就不搞那么复杂了,感兴趣的同学可以继续深入。
提示:上述这套代码只是针对这个测试网页当前的结构来解析的,如果后面这个网站做了修改或者换一个网站,那么这套代码不一定还能用,总的来说还是要根据实际的情况去做调整。
所以,如果这篇博客发布了很久以后你才看到,并且发现这套代码已经用不了,不用怀疑,这跟博主没有关系,我现在测试是OK的。
结束语
好了,关于如何用Python爬取网页图片的介绍就到这里了,内容不多,讲的也比较简单,主要还是要了解原理,大部分网页都是万变不离其中,原理懂了自然就能找到破解方法。
我自己也是一个初学者,如果哪里讲的不对或者有更好的方法,欢迎指正,如果还有什么问题,欢迎在评论区留言或者私信给我。
闲话:
可能有些同学会说:你这个代码需要一个一个输入太麻烦了,能不能批量爬取多个套图呢?
答案是当然可以,你可以从这个网站的首页开始进入,然后跳转到每个套图里面一个一个下载,直到把整个网站都爬完。也可以利用这个网站的检索功能,通过筛选关键字,把某些有共同特征的套图下载下来。
这些操作都是没问题的,问题是你顶得住吗?
PS:如果你有其他值得爬的网站也可以在评论区分享一下,独乐乐不如众乐乐。
想了解更多Python的内容,可以关注一下博主,后续我还会继续分享更多的经验给大家。
如果这篇文章能够帮到你,就…你懂得。

PS:这篇文章发布之后,有些同学问我说没有python的环境能不能用,于是我又改了一版代码生成了一个exe应用程序,不需要搭环境,只要是windows系统都可以运行。
下载地址:https://download.csdn.net/download/ShenZhen_zixian/86514142文章来源:https://www.toymoban.com/news/detail-782043.html
使用说明:
文件目录: 文章来源地址https://www.toymoban.com/news/detail-782043.html
文章来源地址https://www.toymoban.com/news/detail-782043.html
到了这里,关于Python应用开发——爬取网页图片的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!



![[爬虫篇]Python爬虫之爬取网页音频_爬虫怎么下载已经找到的声频](https://imgs.yssmx.com/Uploads/2024/04/855397-1.png)