全文链接:https://tecdat.cn/?p=34709
自2011年全球PC出货量达到历史最高的3.64亿台后,全球PC市场出货量已经连续四年下滑(点击文末“阅读原文”获取完整代码数据)。
相关视频
市场调研公司Gartner最新数据显示,2015年Q3全球PC销量同比降低7.7%,至7370万台。IDC数据更加不乐观,2015年Q3全球PC出货量共计7100万台,同比下降10.8%,相比之前预测的下滑9.2%更夸张。其中,中国市场下滑幅度预计在6%左右。本次调查就是针对笔记本电脑销量运用数据挖掘的方式展开讨论。
研究数据及范围
本研究以统计学原理为基础,通过网上收集已有的数据并调查,采用数据挖掘技术以及描述性的统计方法,对笔记本电脑销量问题进行研究,分析什么影响群众购买笔记本电脑情况。
本次数据是在数据网站搜集到的spss类型的数据,共有13个变量,5000多份数据资料,没有系统缺失值。其中5个定距变量,8个定类变量:

研究目的:
1、寻找影响笔记本电脑销量的主要因素。
2、建立基于数据挖掘技术的有关笔记本电脑销量预测模型。
研究方法
运用数据挖掘clemtime描述性分析,推断性分析,和建模分析。
分析过程
1.数据导入与异常值和离群值的处理

我们可以看见数据存在离群值和异常值,对于离群值,我采用coerce,即用距离离群值最近的正常值代替它们。对于极端值采用discard extremes,即剔除极端值。
点击标题查阅往期内容

R语言Apriori算法关联规则对中药用药复方配伍规律药方挖掘可视化

左右滑动查看更多
01

02

03

04

基本描述分析
通过clmtime描述性分析并作图,
销售价格与月成交量的基本关系:散点图,

价格越贵成交量越少,价格越便宜销售量就相对多。
月成交量与电脑屏幕尺寸的基本关系:散点堆积图

从图中可以看出,销售量峰值在15.6英寸到13英寸之间。

从图中可以看出散点集中在部分品牌,如联想,苹果,戴尔等;
模型简介
关联规则是数据挖掘算法中主要技术之一,是在无指导学习系统中挖掘本地模式的最普遍形式。在数据挖掘中,常见的关联规则挖掘模型有AIS、SETM、Apriori、DHP、MLT2L1、ML-TML1等。其中,Apriori算法是一种最有影响的挖掘关联规则频繁项集的模型。
Apriori模型原理
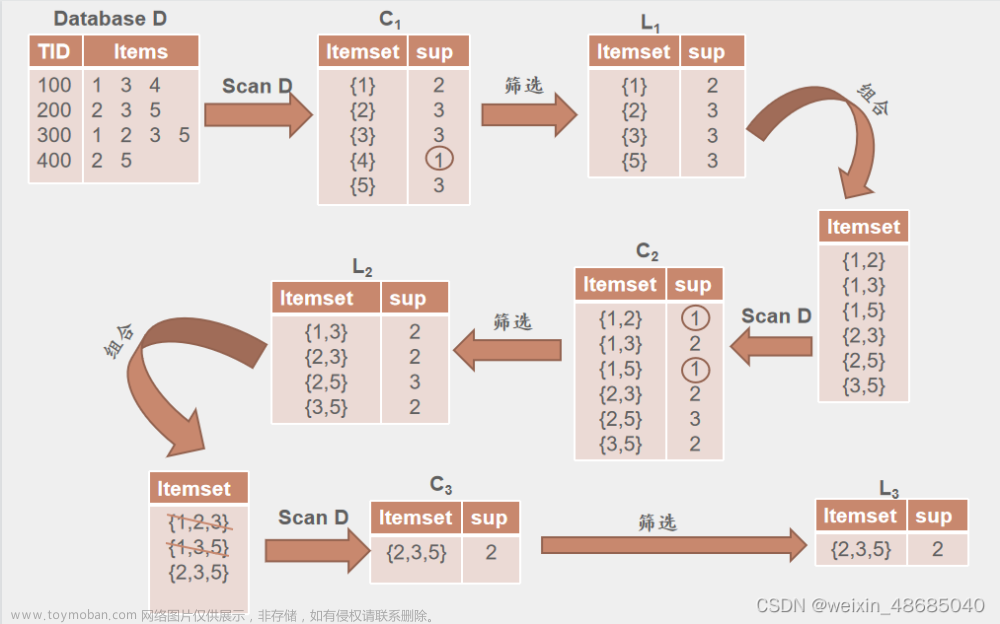
Apriori算法通过多次扫描事务数据库来产生频繁项目集,我们称这种方法为逐层搜索迭代法。具体地说,该算法的基本思想是通过对数据库的多次扫描来发现所有的频繁项集。首先第1遍扫描事务数据库生成频繁1项集,记为L1;然后基于L1第2遍扫描事务数据库生成频繁2项集,记为L2;依此迭代,基于L(k-1)第k遍扫描事务数据库生成频繁k项集,记为Lk。在后续的扫描中,首先以前一次所发现的所有频繁项集为基础,生成所有新的候选项集(Candidate Item sets),然后扫描数据库,计算这些候选项集的支持度,最后确定候选项集中哪些可成为频繁项集。重复上述过程直到再也产生不出新的频繁项集。

仿真
平台及数据
为了验证Apriori模型在DSS数据挖掘中应用的可行性,本文在SPSS modeler软件平台上对Apriori模型进行仿真。实验数据来自于某电商网站的DSS系统中的顾客及购买电脑数据。数据包括1277条购买事务记录,每条购买事务记录中包含内容:价格、月成交量、累计评价、人气、产品名称、能效等级、品牌、屏幕尺寸、显存容量、机械硬盘容量、内存容量等。本文结合Apriori模型分析DSS中的顾客信息及购买数据分析哪些特征电脑最有可能购买。
| 价格 | 月成交量 | 累计评价 | 人气 | 产品名称 | 能效等级 | 品牌 | 屏幕尺寸 | 显存容量 | 机械硬盘容量 | 内存容量 |
|---|---|---|---|---|---|---|---|---|---|---|
| 3299 | 205 | 1353 | 4099 | Acer/宏碁 E5 E5-572G-... | 一级 | Acer/宏碁 | 15.6英寸 | 2GB | 500GB | 4GB |
| 3299 | 205 | 1353 | 4099 | Acer/宏碁 E5 E5-572G-... | 一级 | Acer/宏碁 | 15.6英寸 | 2GB | 500GB | 4GB |
| 3609 | 183 | 2149 | 14134 | Acer/宏碁 E15 E5-572G-... | 一级 | Acer/宏碁 | 15.6英寸 | 2GB | 500GB | 4GB |
| 3609 | 183 | 2149 | 14134 | Acer/宏碁 E15 E5-572G-... | 一级 | Acer/宏碁 | 15.6英寸 | 2GB | 500GB | 4GB |
| 3609 | 183 | 2149 | 14134 | Acer/宏碁 E15 E5-572G-... | 一级 | Acer/宏碁 | 15.6英寸 | 2GB | 500GB | 4GB |
| 3609 | 183 | 2149 | 14134 | Acer/宏碁 E15 E5-572G-... | 一级 | Acer/宏碁 | 15.6英寸 | 2GB | 500GB | 4GB |
| ... | ||||||||||
| 4709 | 88 | 195 | 1409 | Acer/宏碁 威武 V5-591G | 一级 | Acer/宏碁 | 15.6英寸 | 2GB | 1TB | 8GB |
| 4709 | 88 | 195 | 1409 | Acer/宏碁 威武 V5-591G | 一级 | Acer/宏碁 | 15.6英寸 | 2GB | 1TB | 8GB |
| 4709 | 88 | 195 | 1409 | Acer/宏碁 威武 V5-591G | 一级 | Acer/宏碁 | 15.6英寸 | 2GB | 1TB | 8GB |
| 4400 | 88 | 159 | 4365 | Acer/宏碁 Aspire F15 F5... | 一级 | Acer/宏碁 | 15.6英寸 | 4GB | 1TB | 8GB |
| 7588 | 85 | 445 | 2492 | Apple/苹果 MacBook Air ... | 无 | Apple/苹果 | 13.3英寸 | 共享内存容量 | 无机械硬盘 | 4GB |
| 7588 | 85 | 445 | 2492 | Apple/苹果 MacBook Air ... | 无 | Apple/苹果 | 13.3英寸 | 共享内存容量 | 无机械硬盘 | 4GB |
实验结果及分析
本文分别用Apriori算法对数据进行处理挖掘,具体结果如下所示。
Apriori算法
虽然 Apriori 算法可以直接挖掘生成表中的交易数据集,但是为了关联挖掘其他算法的需要先把交易数据集转换成分析数据集,构建的数据流如图 1 所示。

通过格式转换,发现数据源中共有二十种电脑,设最低条件支持度为15%,最小规则置信度为30%,最大前项数为5,选择专家模式,挖掘出大类电脑的13条关联规则,如图 2 所示。生成的13条规则如下所示:

从实验结果来看,实验产生了三条置信度和支持度最高的关联规则:分别为能效等级 = 一级,品牌 = Lenovo/联想,支持度=19.27899686,置信度=97.5609756097561;m能效等级 = 一级,品牌 = Lenovo/联想 and 内存容量 = 4GB ,支持度=12.695924764890282 ,置信度=97.53086419753086;能效等级 = 一级, 品牌 = Lenovo/联想 and 显存容量 = 2GB 支持度=13.166144200626958 ,置信度=96.42857142857143。同时,三条关联规则的提升值都可以接受。因此,能效等级、品牌 = Lenovo/联想、内存容量是最可能连带销售的电脑特征。因此,在实际销售或者在电脑的摆放过程中,可以将这些特征的电脑进行捆绑销售。
分析及建议: 通过表 2 可以清晰的看到购买Lenovo/联想、能效等级 = 一级的顾客比较多,建议电商网站可以加大对这些电脑的采购,由上述结果可知,同时购买Lenovo/联想、能效等级 = 一级的顾客的情况占总订单数的19.27%,能效等级 = 一级,品牌 = Lenovo/联想 and 内存容量 = 4GB的订单分别占总订单数的12.69%,购买能效等级 = 一级电脑的人有97.530会购买Lenovo/联想,95%的人会购买华硕,由此可见,能效等级、内存、品牌这三种电脑特征关联度较高,可以将能效等级 = 一级、Lenovo/联想、华硕的电脑摆放在一块,从而增加销量。此外,在符合支持度和置信度的条件下没有顾客购买东芝、清华同方等,建议有关人员减少这几种电脑的进货量,但为了保持电脑的多样性,还是要适当地进货。

点击文末“阅读原文”
获取全文完整代码数据资料。
本文选自《SPSS modeler用关联规则Apriori模型对笔记本电脑购买事务销量研究》。


点击标题查阅往期内容
非线性混合效应 NLME模型对抗哮喘药物茶碱动力学研究
Python面板时间序列数据预测:格兰杰因果关系检验Granger causality test药品销售实例与可视化
R语言用关联规则和聚类模型挖掘处方数据探索药物配伍中的规律
用SPSS Modeler的Web复杂网络对所有腧穴进行关联规则分析
PYTHON在线零售数据关联规则挖掘APRIORI算法数据可视化
R语言关联规则模型(Apriori算法)挖掘杂货店的交易数据与交互可视化
R语言关联挖掘实例(购物篮分析)
python关联规则学习:FP-Growth算法对药品进行“菜篮子”分析
基于R的FP树fp growth 关联数据挖掘技术在煤矿隐患管理
python关联规则学习:FP-Growth算法对药品进行“菜篮子”分析
通过Python中的Apriori算法进行关联规则挖掘
Python中的Apriori关联算法-市场购物篮分析
R语言用关联规则和聚类模型挖掘处方数据探索药物配伍中的规律
在R语言中轻松创建关联网络
python主题建模可视化LDA和T-SNE交互式可视化
R语言时间序列数据指数平滑法分析交互式动态可视化
用R语言制作交互式图表和地图
如何用r语言制作交互可视化报告图表
K-means和层次聚类分析癌细胞系微阵列数据和树状图可视化比较
KMEANS均值聚类和层次聚类:亚洲国家地区生活幸福质量异同可视化分析和选择最佳聚类数
PYTHON实现谱聚类算法和改变聚类簇数结果可视化比较
有限混合模型聚类FMM、广义线性回归模型GLM混合应用分析威士忌市场和研究专利申请数据
R语言多维数据层次聚类散点图矩阵、配对图、平行坐标图、树状图可视化城市宏观经济指标数据
r语言有限正态混合模型EM算法的分层聚类、分类和密度估计及可视化
Python Monte Carlo K-Means聚类实战研究
R语言k-Shape时间序列聚类方法对股票价格时间序列聚类
R语言对用电负荷时间序列数据进行K-medoids聚类建模和GAM回归
R语言谱聚类、K-MEANS聚类分析非线性环状数据比较
R语言实现k-means聚类优化的分层抽样(Stratified Sampling)分析各市镇的人口
R语言聚类有效性:确定最优聚类数分析IRIS鸢尾花数据和可视化
Python、R对小说进行文本挖掘和层次聚类可视化分析案例
R语言k-means聚类、层次聚类、主成分(PCA)降维及可视化分析鸢尾花iris数据集
R语言有限混合模型(FMM,finite mixture model)EM算法聚类分析间歇泉喷发时间
R语言用温度对城市层次聚类、kmean聚类、主成分分析和Voronoi图可视化
R语言k-Shape时间序列聚类方法对股票价格时间序列聚类
R语言中的SOM(自组织映射神经网络)对NBA球员聚类分析
R语言复杂网络分析:聚类(社区检测)和可视化
R语言中的划分聚类模型
基于模型的聚类和R语言中的高斯混合模型
r语言聚类分析:k-means和层次聚类
SAS用K-Means 聚类最优k值的选取和分析
用R语言进行网站评论文本挖掘聚类
基于LDA主题模型聚类的商品评论文本挖掘
R语言鸢尾花iris数据集的层次聚类分析
R语言对用电负荷时间序列数据进行K-medoids聚类建模和GAM回归
R语言聚类算法的应用实例

 文章来源:https://www.toymoban.com/news/detail-782190.html
文章来源:https://www.toymoban.com/news/detail-782190.html
 文章来源地址https://www.toymoban.com/news/detail-782190.html
文章来源地址https://www.toymoban.com/news/detail-782190.html
到了这里,关于SPSS modeler用关联规则Apriori模型对笔记本电脑购买事务销量数据研究的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!