一、分析
1. 需求分析
从网上找工作,大家一般都会通过各种招聘网站去检索相关信息,今天利用爬虫采集招聘网站的职位信息,比如岗位名称,岗位要求,薪资,公司名称,公司规模,公司位置,福利待遇等最为关心的内容。在采集和解析完成后,使用 Excel 或 csv 文件保存。
2. 目标网页结构的分析
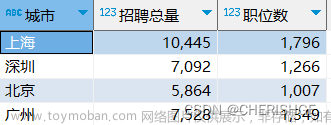
以 "智联招聘" PC 端网页为例,搜索和打开该网站,并进行账密登陆(主要是为了避免 Session 访问限制)。接着,选择目标城市,并搜索与 Python 相关的职位信息,网站会返回相关招聘职位信息的分页结果,如图所示:
通过简单的验证,可以发现当前网页不存在动态渲染,也不存在严格的反爬虫机制。
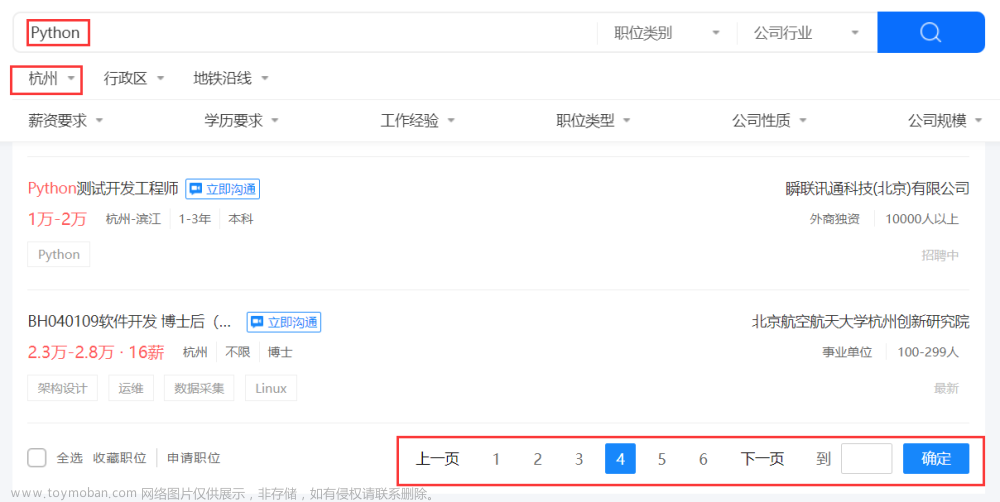
那么,就从第一页开始分析。通过【F12】打开 Google 浏览器的控制台,通过【元素】栏可快速定位到职位列表所在的位置(即 class 为 positionlist 的 div 标签),然后拿该列表下的其中一个“class=joblist-box__item clearfix” 的 div 标签分析,需要的招聘信息基本都在它下面的3个 div 标签内,如下:
如果使用 CSS 选择器的话,定位到职位列表,可以这样做:
soup.find_all('div', class_='joblist-box__item clearfix')对于需求分析中所说的目标数据,则需要进一步展开元素标签,都可以找到具体的位置,如下:
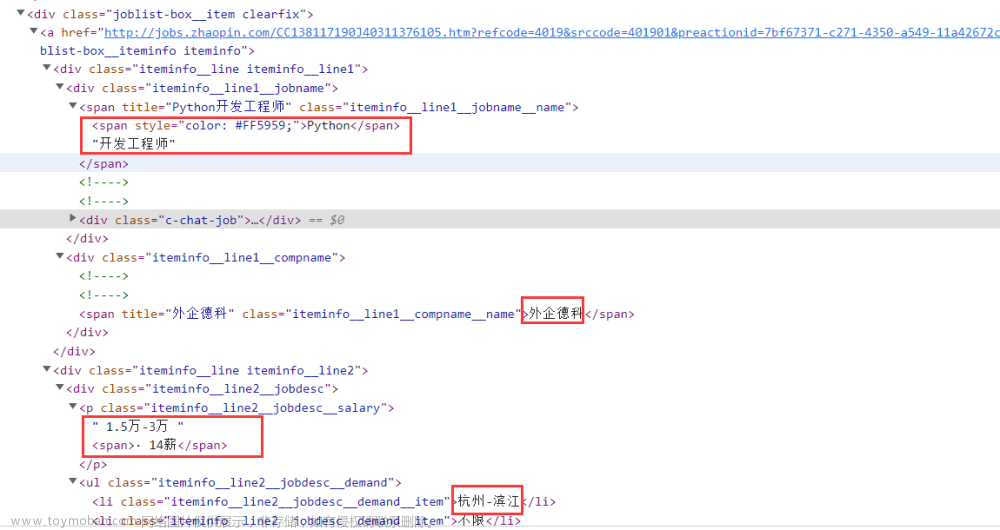
这里才到了最关键的地方,即解析出目标数据,以当前这条招聘信息为例,可以这样做:
# 岗位名称
soup.select("div[class='iteminfo__line1__jobname'] > span[class='iteminfo__line1__jobname__name']")[0].get_text().strip()
# 公司名称
soup.select("div[class='iteminfo__line1__compname'] > span")[0].get_text().strip()
# 薪资
soup.select("div[class='iteminfo__line2__jobdesc'] > p")[0].get_text().strip()
# 公司位置
soup.select("div[class='iteminfo__line2__jobdesc'] > ul[class='iteminfo__line2__jobdesc__demand']")[0].get_text().strip().split(" ")[0]如果遍历第一页的所有招聘信息,在循环中把 select(xxx)[0] 换成 select(xxx)[i] 就可以了。
3. 分页分析
实际上,我们不止会爬取第一页数据,根据情况会需要指定爬取页数,或者爬取所有页。此时,就得寻找请求 URL 的规律了,第一页的 URL 为:
https://sou.zhaopin.com/?jl=653&kw=Python点击第二页,第三页.....一直到最后一页,URL变化为:
https://sou.zhaopin.com/?jl=653&kw=Python&p=1
https://sou.zhaopin.com/?jl=653&kw=Python&p=2
......
https://sou.zhaopin.com/?jl=653&kw=Python&p=6这样就可以找到明显的规律,我们把第一页的 URL 也按这种方式拼接一个 &p=1,得到的结果与第一页是一样的。因此,通过这个参数 p 就可以控制爬取的页数。
那爬取所有页呢,该如何判断当前页到了最后一页了?经分析发现,分页区域在 "class=pagination clearfix" 的 div 标签内,准确点说是在 "class=pagination__pages" 的 div 标签内,如下所示:
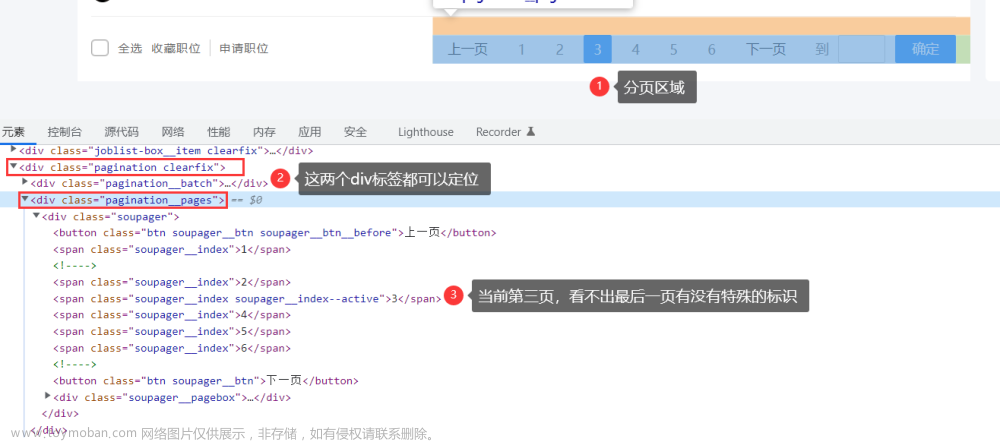
点击到第3页,仍无法区分最后一页的标识,当尝试点击到最后一页(第6页)时,就可以看到不同了,下一页的 div 会多出一个class属性,如下所示:
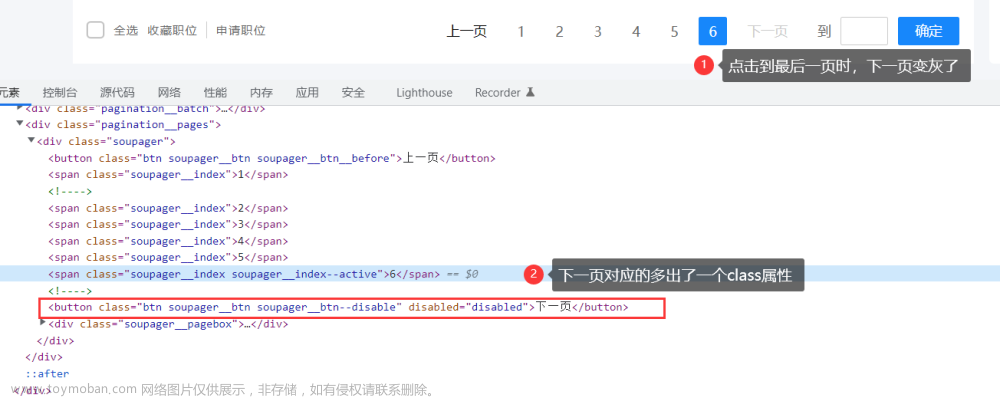
此时,利用这个明显的特征,可以这样写解析表达式,轻松定位到最后一页:
soup.select("div[class='pagination__pages'] > button[class='btn soupager__btn soupager__btn--disable']")只要判断出 last_page 是否为空值即可,为空说明不是最后一页。经过上述的一番分析,对该招聘网站页面的爬取解析似乎已胸有成竹了。
接下来,选择 request + BeautifulSoup + CSS 选择器的技术方案,实现我们的爬虫目标。
二、代码实现
1. 主体方法的实现
思路如下:
- 拼接请求的 url,发起 get 请求(支持分页操作),返回响应码为200的话,循环获取 html 网页源代码;
- 将 html 网页源代码保存成 txt 文件,便于分析和查看问题(比如乱码情况等);
- 接着,解析 html 页面,并提取出目标数据,并保存成可选格式的文件,比如 csv 文件等。
代码如下:
def process_zhilianzhaopin(baseUrl, pages, fileType, savePath):
results = [['岗位名称', '公司名称', '岗位薪资', '岗位要求', '公司位置', '福利待遇']]
headers = UserAgent(path='D:\\XXX\\reptile\\fake_useragent.json').google
# 根据入参pages,拼接请求url,控制爬取的页数
for page in range(1, int(pages) + 1):
url = baseUrl + str(page)
response = requests.get(url, headers)
print(f"current url:{url},status_code={response.status_code}")
if response.status_code == 200:
html = response.text
html2txt(html, page, savePath)
parser_html_by_bs(html, page, results, fileType, savePath)
else:
print(f"error,response code is {response.status_code} !")
print('爬取页面并解析数据完毕,棒棒哒.....................................')2. 保存网页源代码
注意:前提要保证保存网页源代码的路径是存在的。
def html2txt(html, page, savePath):
with open(f'{savePath}\\html2txt\\zhilianzhaopin_python_html_{page}.txt', 'w', encoding='utf-8') as wf:
wf.write(html)
print(f'write boss_python_html_{page}.txt is success!!!')3. 解析网页源代码
解析流程:
- 整体思路:先进行末页判断;非末页的话,再定位当前页的网页元素,并提取目标数据;提取的数据写入指定格式文件。
def parser_html_by_bs(html, current_page, results, fileType, savePath):
soup = BeautifulSoup(html, "html.parser")
# 判断当前页是否为最后一页
if not judge_last_page(current_page, soup):
# 定位网页元素,获取目标数据
get_target_info(soup, results)
# 并将解析的数据写入指定文件类型
write2file(current_page,results, fileType, savePath)- 判断当前页是否为最后一页,是的话不再解析,否则,继续解析。判断代码如下:
def judge_last_page(current_page, soup):
last_page = soup \
.select("div[class='pagination__pages'] > button[class='btn soupager__btn soupager__btn--disable']")
if len(last_page) != 0:
print("current_page is last_page,page num is " + str(last_page))
return True
print(f"current_page is {current_page},last_page is {last_page}")
return False- 解析网页源代码中的 '岗位名称', '公司名称', '岗位薪资', '岗位要求', '公司位置', '福利待遇' 等内容,组装成数据列表写入结果列表,如下:
def get_target_info(soup, results):
jobList = soup.find_all('div', class_='joblist-box__item clearfix')
# print(f"jobList: {jobList},size is {len(jobList)}")
for i in range(0, len(jobList)):
job_name = soup.select("div[class='iteminfo__line1__jobname'] > span[class='iteminfo__line1__jobname__name']")[i].get_text().strip()
company_name = soup.select("div[class='iteminfo__line1__compname'] > span")[i].get_text().strip()
salary = soup.select("div[class='iteminfo__line2__jobdesc'] > p")[i].get_text().strip()
desc_list = soup.select("div[class='iteminfo__line2__jobdesc'] > ul[class='iteminfo__line2__jobdesc__demand']")[i].get_text().strip()
# print(f"job_name={job_name} , company_name={company_name}, salary={salary}, tag_list=null, job_area={desc_list.split(' ')[0]}, info_desc=null")
results.append([job_name,company_name,salary,desc_list.split(" ")[1] + "," + desc_list.split(" ")[2], desc_list.split(" ")[0],"暂时无法获取"])4. 写入指定文件的方法实现
注意:前提要保证保存写入文件的路径是存在的,这里以写入 csv 文件为例,如果要写入其他文件,可新增条件分支判断自行实现。
def write2file(current_page, results, fileType, savePath):
if fileType.endswith(".csv"):
with open(f'{savePath}\\to_csv\\zhilianzhaopin_python.csv', 'a+', encoding='utf-8-sig', newline='') as af:
writer = csv.writer(af)
writer.writerows(results)
print(f'第{current_page}页爬取数据保存csv成功!')5. 开启测试
if __name__ == '__main__':
base_url = "https://sou.zhaopin.com/?jl=653&kw=Python&p="
save_path = "D:\\XXX\\zhilianzhaopin_python"
page_total = "2"
process_zhilianzhaopin(base_url, page_total, ".csv", save_path)以爬取前两页数据为例,把 page_total 赋值为2即可,控制台输出的日志如下:
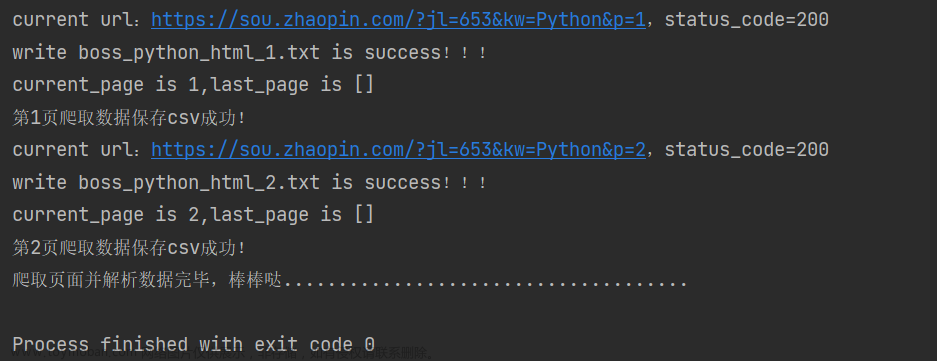
保存网页源代码的文本文件,测试效果如下:

解析的数据写入 csv 文件,测试效果如下:

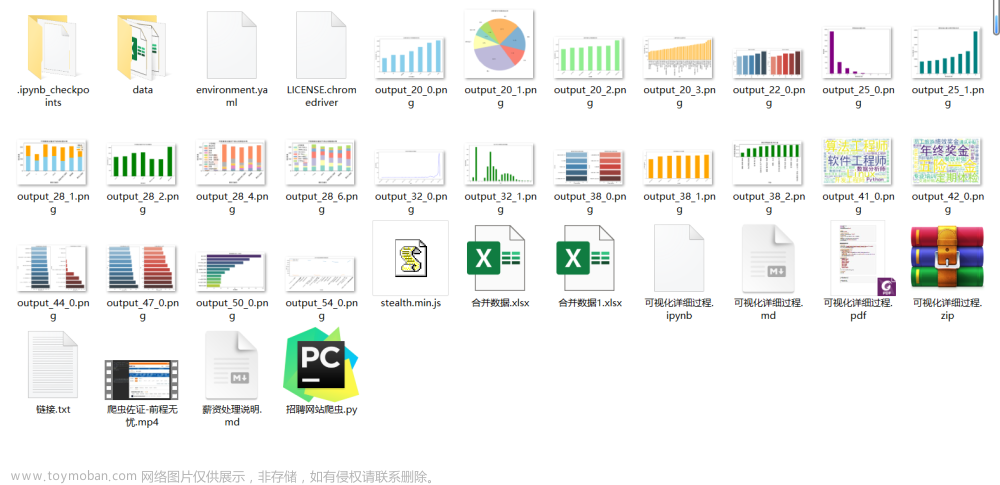
打开该 csv 文件,可以看到爬取 2 页总共 40 条的职位信息,内容如下:

如果验证测试爬取所有页的结果(总共有 6 页),我们把测试代码中的 page_total 赋值为 6 即可。
7. 遇到的问题记录
爬取过程中,避免不了出现各种各样的问题,有些暂时还无法解决,甚是头大,这里记录一下。
<1>. 乱码
写入 CSV 文件时,遇到了中文乱码情况,爬取到的中文乱的不堪入目。最后,将 encoding='utf-8' 改成 encoding='utf-8-sig' 就可以解决了!
<2>. 重复数据
以前两页为例,写入 CSV 文件的数据时,出现了重复的情况。经过分析,爬取代码的流程应该没什么问题,而问题在于:无论请求的是第几页的数据,服务器返回的数据都是默认数据?!最直观的验证是 zhilianzhaopin_python_html_1.txt 和 zhilianzhaopin_python_html_2.txt 网页源代码文件的内容是一模一样的,而通过日志打印出的链接去访问,却找不到其中的岗位或公司名称!
至此,恍然大悟啊!智联招聘网站还是开启了反爬虫机制,只不过比较隐蔽,不太好发现和验证,因为爬取者可以爬取到网页数据。如果对爬取的数据不进行细致的验证或分析,很难发现存在这种情况,会误以为爬取成功了呢!
<3>. 末页判断不生效
末页判断不生效的问题,一开始困扰着我。从爬取数据的内容分析来看,网站开启了反爬虫机制,导致无论哪一页的请求,都会被定向请求默认的网页源代码,所以末页的标签永远不会出现了。哎,真是大坑啊!!!
最后
爬虫就是如此,有时候自己觉得已经绕过了网站的爬虫机制,然而等到数据验证和清洗环节才发现问题,这也为学习爬虫提了个醒吧。文章来源:https://www.toymoban.com/news/detail-782226.html
不过呢,本篇介绍的分析方法和代码实现,对于没有严格反爬虫的网页是可以通用的,重点在于网页结构的分析,网页元素的定位等内容。对于这种比较隐蔽的反扒机制,还是有办法能解决的,下篇将演示使用 selenium 模块解决这类问题。文章来源地址https://www.toymoban.com/news/detail-782226.html
到了这里,关于【爬虫系列】Python爬虫实战--招聘网站的职位信息爬取的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!