项目功能简介:
1.交互式配置;
2.两种任意关键词来源(直接输入、本地关键词文件);
3.自动翻页(无限爬取);
4.指定最大翻页页码;
5.数据保存到csv文件;
6.程序支持打包成exe文件;
7.项目操作说明文档;
一.最终效果

视频演示:
用python爬取微博关键词搜索结果、exe文件视频演示
二.项目代码
2.1 数据来源分析
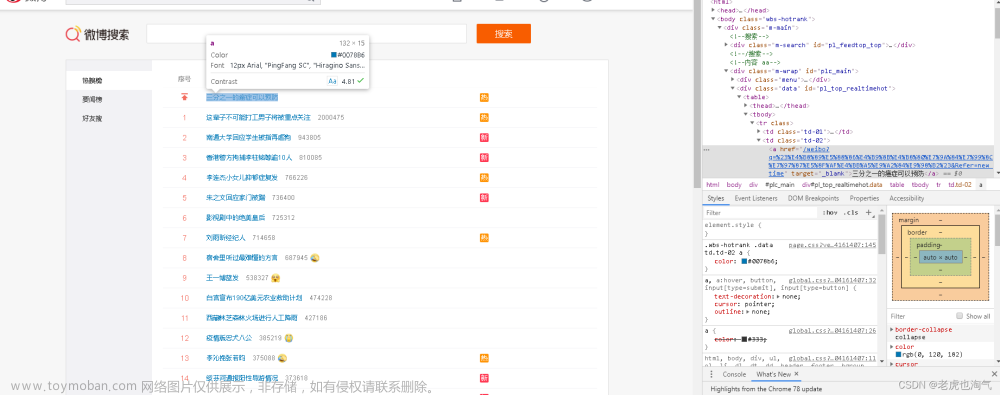
使用chrome浏览器,F12打开调试面板,使用元素选择工具确定元素位置,如下图

确定页面元素:
说明:为何不直接调用接口获取数据呢? 通过调试面板会发现,搜索结果数据不是前后端分离方式返回到web端,而是通过服务端渲染之后一起发送到web端,所以只能对html解析,获取到关键字段内容。
2.2 解析数据
解析html需要使用bs4库,使用前请确保已经安装成功: pip install bs4,查看本地是否已经安装: pip list,如下图:

from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'html.parser')
elements = soup.select('#pl_feedlist_index .card-wrap')
高能总结:1. soup.select选择器返回的对象还能继续选择元素,例如上面的elements,
elements.select_one('.card .info #title');2. 元素如果使用了class对应选择器中用.,id用#,元素标签直接用标签名称,例如div、span、ul等等。
三.批量保存数据
数据保存使用pandas,因此需要先安装: pip install pandas,解析道的数据单行保存读写文件太费时间,使用pandas批量保存,用法如下:
import pandas as pd
list = [
{
"keywords":"",
...
"like":"",
},{
"keywords":"",
...
"like":"",
}
]
df = pd.DataFrame(list)
df.to_csv('result.csv', index=False, columns=["keywords", "nickname", "publish_time", "device_info", "weibo_content", "forward", "comment", "like"])
高能总结:1. df.to_csv保存数据时,如果不存在
result.csv文件会自动创建;2.往已经存在数据的result.csv文件中追加数据,使用追加方式:df.to_csv('result.csv', index=False, mode='a', header=False)
pandas保存检查完整代码:
import pandas as pd
import os
class DataTool:
def __init__(self):
self.file_path = 'result.csv'
def check_data(self):
if os.path.exists(self.file_path):
with open(self.file_path, 'r') as file:
first_line = file.readline()
if first_line.strip():
return True
else:
return False
else:
return False
def data_to_save(self, list, page):
df = pd.DataFrame(list)
print("数据保存中...")
if page == 1:
has_file = self.check_data()
if not has_file:
df.to_csv(self.file_path, index=False, columns=["keywords", "nickname", "publish_time", "device_info", "weibo_content", "forward", "comment", "like"])
return
df.to_csv(self.file_path, index=False, mode='a', header=False)
下面是pandas库的优点总结:
Pandas 是一个强大的数据处理和分析库,它在数据科学和数据分析领域非常受欢迎。以下是一些 Pandas 库的主要优点:
1.数据结构:Pandas 提供了两个主要的数据结构,DataFrame 和 Series,它们使数据的处理和分析变得更加容易。DataFrame 是一个二维表格,类似于关系型数据库表,而 Series 是一个一维数组,类似于列表或数组。这两种数据结构使得处理不同类型的数据变得更加方便。
2.数据清洗:Pandas 提供了丰富的数据清洗工具,包括处理缺失值、重复值、异常值等的功能。你可以轻松地对数据进行清洗、填充缺失值、删除重复行等操作。
3.灵活的数据操作:Pandas 允许你进行各种灵活的数据操作,包括筛选、过滤、排序、合并、重塑和透视表等。这使得数据分析更加容易,你可以按照需要对数据进行各种操作,而不需要编写复杂的循环和逻辑。
4.数据分组和聚合:Pandas 提供了强大的分组和聚合功能,允许你根据一个或多个列对数据进行分组,并应用聚合函数(如求和、平均值、计数等)来汇总数据。这对于生成统计信息和汇总报告非常有用。
5.时间序列处理:Pandas 支持时间序列数据的处理和分析,包括日期和时间的解析、重采样、滚动窗口计算等。这对于金融分析、天气数据、股票市场分析等领域非常有用。
6.丰富的数据输入/输出:Pandas 支持多种数据格式的读写,包括 CSV、Excel、SQL 数据库、JSON、HTML、Parquet 等,使得数据的导入和导出非常方便。
7.集成性:Pandas 可以与其他数据科学库(如 NumPy、Matplotlib、Scikit-Learn)无缝集成,使得数据分析和建模工作更加流畅。
四.运行过程

五.项目说明文档
 文章来源:https://www.toymoban.com/news/detail-782455.html
文章来源:https://www.toymoban.com/news/detail-782455.html
六.获取完整源码
爱学习的小伙伴,本次案例的完整源码,已上传微信公众号“一个努力奔跑的snail”,后台回复 微博关键词 即可获取。文章来源地址https://www.toymoban.com/news/detail-782455.html
到了这里,关于【爬虫实战】用python爬取微博任意关键词搜索结果、exe文件的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!