最近一直在学习使用 Stable Diffusion,目前开始学习 LoRA 训练,试图使用 LoRA 微调预训练模型,实现脸型替换等常用功能
-
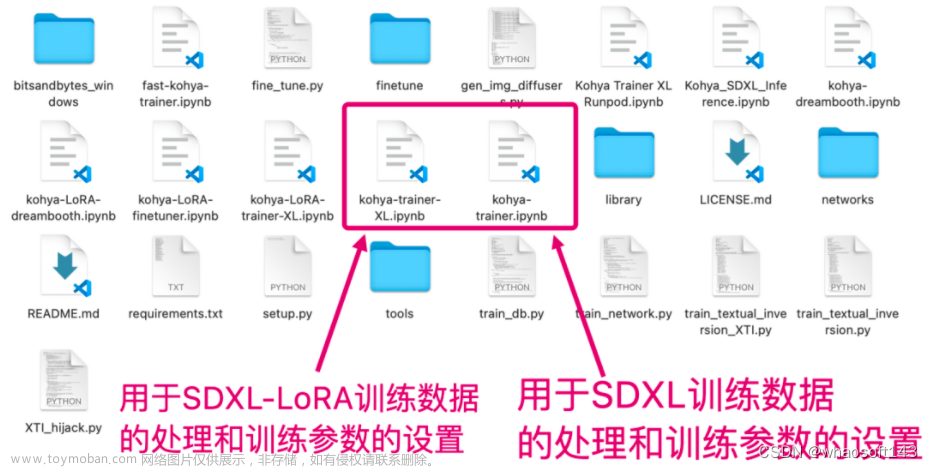
最开始我跑去了 LoRA 的官方仓库,虽然找到了
lora_pti工具,但是没有理解数据集的准备方式,翻阅代码也没有理解到有用的信息 -
后面我找到了
SDWebUI的Images Processing工具,它可以裁切缩放原始图像,最重要的是Use deepbooru for caption这个选项,可以自动为图片添加标签 -
尝试执行了之后,发现
SDWebUI会把所有图像转换为PNG,并且把自动生成的标注信息保存在同名的TXT文件中 -
找到了
diffusers库官方给的示例脚本train_text_to_image_lora.py,看了一遍参数,发现传入参数需要huggingface的datasets数据集格式 -
翻阅 官方文档,写了一段简单的代码,从
SDWebUI的Images Processing输出目录,生成metadata.jsonl文件,构建符合格式的数据集目录 -
跑了一下,居然爆了我的 3090 涡轮卡的 24G 显存,找到了一片文章,可以优化参数 ,减少内存占用文章来源:https://www.toymoban.com/news/detail-782726.html
https://www.cnblogs.com/huggingface/p/17108402.html文章来源地址https://www.toymoban.com/news/detail-782726.html
export MODEL_NAME="runwayml/stable-diffusion-v1-5"
export OUTPUT_DIR="/sddata/finetune/lora/pokemon"
export HUB_MODEL_ID="pokemon-lora"
export DATASET_NAME="lambdalabs/pokemon-blip-captions"
accelerate launch --mixed_precision="fp16" train_text_to_image_lora.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--dataset_name=$DATASET_NAME \
--dataloader_num_workers=8 \
--resolution=512 --center_crop --random_flip \
--train_batch_size=1 \
--gradient_accumulation_steps=4 \
--max_train_steps=15000 \
--learning_rate=1e-04 \
--max_grad_norm=1 \
--lr_scheduler="cosine" --lr_warmup_steps=0 \
--output_dir=${OUTPUT_DIR} \
--push_to_hub \
--hub_model_id=${HUB_MODEL_ID} \
--report_to=wandb \
--checkpointing_steps=500 \
--validation_prompt="Totoro" \
--seed=1337
到了这里,关于StableDiffusion 学习笔记 - 训练 LoRA的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!