一.语境化语言表示模型介绍
语境化语言表示模型(Contextualized Language Representation Models)是一类在自然语言处理领域中取得显著成功的模型,其主要特点是能够根据上下文动态地学习词汇和短语的表示。这些模型利用了上下文信息,使得同一词汇在不同语境中可以有不同的表示。以下是一些著名的语境化语言表示模型:
-
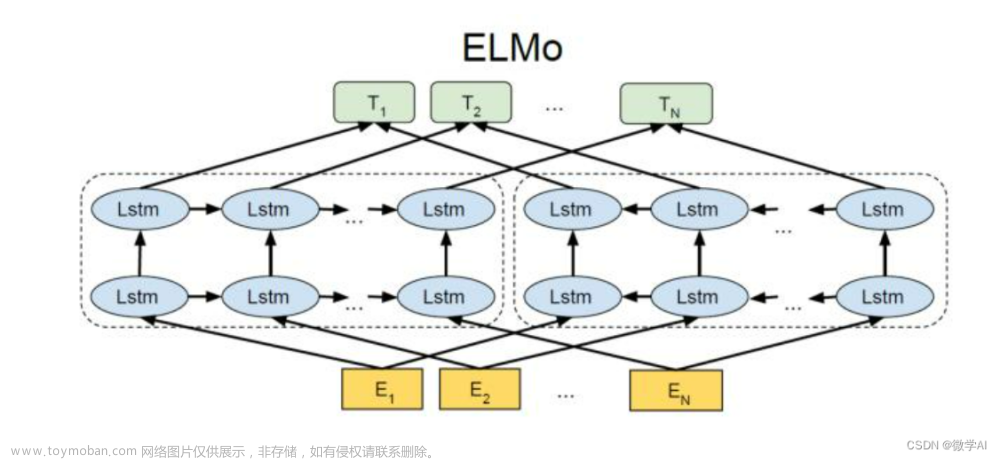
ELMo(Embeddings from Language Models): ELMo是一种基于LSTM(长短时记忆网络)的双向语言模型,通过在训练时考虑双向上下文信息,为每个词生成一个上下文相关的词向量。ELMo的词向量是通过将前向LSTM和后向LSTM的隐藏状态进行线性组合而得到的。
-
BERT(Bidirectional Encoder Representations from Transformers): BERT是一种基于Transformer架构的预训练模型,通过使用大规模的语言模型预训练来学习上下文相关的词表示。BERT考虑了一个词在句子中的左右上下文,并通过遮蔽掉一些词汇,训练模型来预测这些被遮蔽的词汇。
-
GPT(Generative Pre-trained Transformer): GPT是一系列基于Transformer的预训练模型,与BERT不同,GPT使用了单向的语言模型,即只考虑前面的上下文。GPT系列的模型通过自回归生成方式,逐个预测下一个词。
这些语境化语言表示模型在自然语言处理的多个任务中取得了显著的性能提升,包括文本分类、命名实体识别、情感分析、问答系统等。由于它们能够充分考虑上下文信息,更好地捕捉语义和语法结构,因此在处理复杂的自然语言任务时表现优异。
这些模型通常是在大规模语料库上进行预训练,然后在特定任务上进行微调。这使得它们能够在各种不同领域和任务中取得良好的泛化性能。
二.语境化语言表示模型-ELMO
ELMo(Embeddings from Language Models)是一种语境化语言表示模型,由斯坦福大学的研究团队于2018年提出。ELMo旨在通过使用深度双向LSTM(长短时记忆网络)来生成上下文相关的词向量,从而改进传统的静态词向量表示。
ELMo的主要特点包括:
双向上下文建模: ELMo通过使用双向LSTM模型,考虑了一个词在句子中的左右上下文信息。这使得生成的词向量能够更好地捕捉词汇在不同上下文中的含义。
层次化表示: ELMo的表示不是简单地从模型的最后一层获取,而是将多个LSTM层的隐藏状态进行线性组合,从而形成多层的语言表示。每一层都对应于不同抽象级别的语言表示,这种层次化的表示可以更好地适应不同任务。
预训练和微调: ELMo首先在大规模的语言模型预训练阶段进行学习,然后在特定任务上进行微调。预训练过程使得模型能够学习通用的语言表示,而微调过程则使得模型能够适应特定领域或任务的上下文。
ELMo的词向量表示是通过以下方式计算的:

其中,wi是第 i 个词汇,L是LSTM层数,hij 是第 j 层LSTM在第i个词汇上的隐藏状态,sj是模型学到的权重系数,γ是缩放系数。
ELMo的提出带来了对传统静态词向量的一些重要改进,主要体现在以下几个方面:
-
上下文相关性: ELMo生成的词向量是上下文相关的,能够捕捉每个词在不同上下文中的含义。这使得模型更加灵活,能够适应不同语境和任务的要求。
-
多层表示: ELMo采用了多层的双向LSTM,生成了多个层次的语言表示。每个层次对应不同抽象级别的语义信息,使得模型能够在更细粒度和更高层次上理解文本。
-
预训练和微调: ELMo首先在大规模语料上进行预训练,学习通用的语言表示,然后在特定任务上进行微调,适应特定领域或任务的上下文。这种两阶段的训练使得模型更具泛化性。
-
多任务学习: 由于ELMo的语言表示是通过多层双向LSTM的线性组合得到的,每一层都可以用于不同任务。这种多任务学习的特性使得模型能够在一个模型中同时适应多个任务。
ELMo在这些任务中的应用表现:
-
情感分析: 在情感分析任务中,理解文本中的情感极性对于判断文本的情感态度非常重要。ELMo能够捕捉词汇在句子中的不同语境,从而更好地理解和表示情感相关的信息,提高了情感分析模型的性能。
-
问答系统: 在问答系统中,理解问题和文本的语境是关键。ELMo生成的上下文相关的词向量可以更好地捕捉问题和答案之间的关系,使得问答系统更具智能性和准确性。
-
文本分类: 在文本分类任务中,ELMo的上下文相关性使得模型能够更好地理解文本中的语义信息。这对于区分不同类别的文本非常有帮助,提高了文本分类模型的准确性。
-
命名实体识别: 在命名实体识别任务中,ELMo的上下文相关的词向量有助于更好地理解文本中实体的边界和语境,提高了命名实体识别模型的精度。
总的来说,ELMo的应用范围广泛,其上下文相关的词向量表示在多个任务中都展现了显著的优势,使得模型能够更好地理解语言的复杂性和多义性。然而,也需要注意到后续出现的一些更先进的语境化表示模型(如BERT和GPT等)在某些任务上取得了更好的性能。
三.语境化语言表示模型-BERT向量

BERT(Bidirectional Encoder Representations from Transformers)模型是一种语境化语言表示模型,通过预训练来生成上下文相关的词向量。在BERT中,词向量通常被称为BERT向量。BERT向量的生成过程包括两个阶段:预训练和微调。
预训练阶段: 在预训练阶段,BERT模型通过大规模的无标签语料库进行训练。在这个阶段,BERT使用了两个任务来学习上下文相关的词向量:掩码语言模型(Masked Language Model, MLM)和下一句预测(Next Sentence Prediction, NSP)任务。
通过在输入文本中随机掩盖一些词汇,BERT模型被训练来预测被掩盖的词汇。同时,BERT模型还通过判断两个句子是否是原文中的连续句子来学习句子级别的关系。这个阶段的输出是每个位置上的上下文相关的词向量。
微调阶段: 在微调阶段,BERT模型根据具体的下游任务(如文本分类、命名实体识别等)的标签信息,使用带标签的数据对模型进行微调。在微调阶段,模型的参数会根据任务的特定目标进行调整,以适应特定任务的要求。微调可以在相对较小的标注数据集上进行,因为BERT已经在大规模的无标签数据上进行了预训练。
BERT向量的特点包括:
上下文相关性: 由于BERT是基于双向Transformer结构进行训练的,生成的词向量能够捕捉每个词在其上下文中的语义信息。
多层次表示: BERT模型包含多个Transformer层,每个层次都提供了一个不同抽象级别的表示。因此,BERT向量是一个多层次的表示,可以在不同任务中灵活应用。
预训练和微调: BERT向量在预训练阶段学习通用的语言表示,而在微调阶段可以根据具体任务的需求进行进一步优化。
BERT向量在自然语言处理的各个任务中都表现出色,取得了许多领域的最新性能。由于BERT的成功,许多后续的语境化语言表示模型(如GPT、RoBERTa等)也在此基础上进行了发展和改进。
四.语境化语言表示模型-GPT

GPT(Generative Pre-trained Transformer)是一种语境化语言表示模型,属于Transformer架构的一部分。与BERT不同,GPT是通过自回归方式进行训练的,即模型在生成文本时依次预测下一个词汇。以下是GPT的一些关键特点:
Transformer架构: GPT采用了Transformer架构,这种架构在处理序列数据时非常强大。Transformer使用注意力机制来捕捉输入序列中不同位置的关系,使得模型能够在长距离上捕捉依赖关系。
自回归训练: GPT采用自回归的方式进行训练。在训练过程中,模型通过最大化下一个词的条件概率来预测整个序列。这种方法使得GPT生成的语言表示更加连贯,适用于生成任务。
层次化表示: GPT模型通常包含多个Transformer层,每一层都提供了一个不同层次的语言表示。这种层次化的表示使得GPT能够理解文本的不同抽象级别的语义信息。
无监督预训练: 在预训练阶段,GPT通过大规模的无标签语料库进行自监督学习,学习通用的语言表示。预训练完成后,模型可以在各种下游任务上进行微调,以适应具体的应用。
生成任务应用: GPT最初设计用于生成任务,如文本生成、对话生成等。由于采用了自回归训练方式,GPT在生成连贯且富有语义的文本方面表现出色。
OpenAI的GPT系列: GPT的发展成为了一系列模型,包括GPT-2和GPT-3。这些模型在参数规模、性能和能力方面逐渐提升,GPT-3更是达到了数万亿个参数的规模。
GPT在多个自然语言处理任务中都取得了显著的成功,包括文本生成、对话系统、文本摘要等。然而,与BERT等其他模型相比,GPT的无监督训练方式也带来了一些挑战,例如对大规模数据和计算资源的需求。
五.语境化语言表示模型-XLNet
XLNet(eXtreme Learning Machine Network)是一种语境化语言表示模型,由谷歌AI团队于2019年提出。它结合了Transformer的架构和自回归(autoregressive)以及自编码(autoencoding)等训练目标,以提高对上下文的建模能力。以下是一些关键特点:
Transformer架构: XLNet采用Transformer的结构,包括自注意力机制。这使得模型能够有效捕捉文本中的长距离依赖关系。
自回归和自编码: XLNet结合了自回归和自编码两种训练目标。自回归部分通过最大化给定上下文条件下下一个词的概率,类似于GPT。自编码部分则通过最大化一个被随机掩码的词预测所有其他词的概率,类似于BERT。
Permutation Language Modeling(PLM): XLNet引入了Permutation Language Modeling任务,即对输入序列中的一些词的排列进行预测。这使得模型能够更好地理解词汇之间的全局关系。
两个流的架构: XLNet通过两个流的架构实现了自回归和自编码目标的融合。一个流负责从左到右的自回归目标,另一个流负责从右到左的自编码目标。这种设计使得模型更加全面地捕捉上下文信息。
超长序列: 由于采用了自回归的方式,XLNet相对于BERT等模型更容易处理长文本,因为它不需要将整个上下文序列压缩到一个固定长度。
XLNet在多个自然语言处理任务上表现出色,包括文本分类、问答系统、命名实体识别等。它的训练过程和细节相对复杂,需要大规模的数据和计算资源。以下是一个简化的伪代码示例,用于理解XLNet的基本训练流程:文章来源:https://www.toymoban.com/news/detail-782789.html
import torch
from torch.optim import Adam
from transformers import XLNetTokenizer, XLNetForSequenceClassification
# 使用预训练的XLNet模型和tokenizer
model = XLNetForSequenceClassification.from_pretrained('xlnet-base-cased')
tokenizer = XLNetTokenizer.from_pretrained('xlnet-base-cased')
# 数据准备
text_data = ["Your text data here...", "Another sentence...", ...]
labels = [0, 1, ...] # 根据任务的不同,labels会有所变化
tokenized_data = tokenizer(text_data, return_tensors='pt', padding=True, truncation=True)
labels = torch.tensor(labels)
# 模型和优化器
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
optimizer = Adam(model.parameters(), lr=2e-5)
# 训练过程
num_epochs = 3
for epoch in range(num_epochs):
model.train()
optimizer.zero_grad()
# 前向传播
outputs = model(**tokenized_data, labels=labels)
loss = outputs.loss
# 反向传播和优化
loss.backward()
optimizer.step()
print(f"Epoch {epoch + 1}/{num_epochs}, Loss: {loss.item()}")
# 保存训练好的模型
model.save_pretrained('path/to/save/model')
tokenizer.save_pretrained('path/to/save/tokenizer')
这里的代码是基于Hugging Face的transformers库,该库提供了方便的接口用于使用和微调预训练的XLNet模型。在实际应用中,你可能需要根据任务的不同对模型进行微调,调整模型的超参数,并根据实际情况对数据进行更详细的处理。文章来源地址https://www.toymoban.com/news/detail-782789.html
到了这里,关于语境化语言表示模型-ELMO、BERT、GPT、XLnet的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!