目标检测——下篇🍉
前言🎓
上一章介绍了目标检测上篇,主要为两阶段检测的R-CNN系列。这一章来学习一下目标检测下篇。R-CNN系列算法面临的一个问题,不是端到端的模型,几个构件拼凑在一起组成整个检测系统,操作起来比较复杂。而今天介绍的YOLO算法,操作简便且速度快,效果也不错。YOLO算法是一种典型的one-stage方法,它是You Only Look Once 的缩写,意思是神经网络只需要看一次图片,就能输出结果。
目标检测有两种实现,一种是one-stage,另一种是two-stage,它们的区别如名称所体现的,two-stage有一个region proposal过程,可以理解为网络会先生成目标候选区域,然后把所有的区域放进分类器分类,而one-stage会先把图片分割成一个个的image patch,然后每个image patch都有M个anchor box,把所有的anchor送进分类器输出分类和检测位置。很明显可以看出,后一种方法的速度会比较快。YOLO系列与R-CNN系列算法的区别在于以不同的方式处理对象检测。它将整个图像放在一个实例中,并预测这些框的边界框坐标和及所属类别概率。使用YOLO算法最大优的点是速度极快,每秒可处理45帧,也能够理解一般的对象表示。

一、R-CNN回顾
R-CNN系列不断升级的过程,就是对网络不断化简的过程,处理时间不断缩减,检测精度不断提高。
- R-CNN💛: Selective Search提取区域图片+Max Pooling层
- SPP-Net🧡:Max Pooling层升级为SPP层
- Fast R-CNN❤️:SPP层升级为RoI池化层,SVMs升级为N类Bounding box回归和(N+1)-way Softmax
- Faster R-CNN💜:Selective Search提取区域升级为RPN提取区域

R-CNN系列主要基于较早的CNN结构,如AlexNet、VGG。存在大量全连接网络,缺点就在于参数过多,影响模型训练速度。所以之后的趋势就是用全卷积网络替换全连接网络,比如ResNet、GoogLeNet相比于之前的网络全连接网络使用越来越少,只剩1个全连接层。
二、R-FCN
2016年Jifeng Dai等人提出一种基于区域的目标检测算法:R-FCN(Region-based Fully Convolutional Network),R-FCN可以看做是Faster RCNN的改进版,速度上提高了差不多3倍左右,mAP也有一点提升。而另外一类目标检测算法像YOLO,SSD等目标检测算法是不基于区域的。
论文:R-FCN:object detection via region-based fully convolutional networks
改进点:
- 提出Position-sensitive score maps来解决目标检测的位置敏感性问题
- 区域为基础的,全卷积网络的二阶段目标检测框架
- 比Faster-RCNN快2.5-20倍(在K40GPU上面使用ResNet-101网络可以达到 0.17 sec/image)
R-FCN和Faster R-CNN相比,R-FCN具有更深的共享卷积网络层,这样可以获得更加抽象的特征;同时,它没有RoI-wise subnetwork,不像Faster R-CNN的feature map左右都有对应的网络层,它是真正的全卷积网络架构;从图中的表格可以看出Faster R-CNN的共享卷积子网络是91层,RoI-wise子网络是10层,而R-FCN只有共享卷积子网络,深度为101层。与R-CNN相比,最大的不同就是直接获得整幅图像的feature map,再提取对应的ROI,而不是直接在不同的ROI上面获得相应的feature map。
R-FCN算法流程如下:
- 选择一张需要处理的图片,并对这张图片进行相应的预处理操作;
- 将预处理后的图片送入一个预训练好的分类网络中(这里使用了ResNet-101网络的Conv4之前的网络),固定其对应的网络参数
- 在预训练网络的最后一个卷积层获得的feature map上存在3个分支,第1个分支就是在该feature map上面进行RPN操作,获得相应的ROI;第2个分支就是在该feature map上获得一个KK(C+1)维的位置敏感得分映射(position-sensitive score map),用来进行分类;第3个分支就是在该feature map上获得一个4KK维的位置敏感得分映射,用来进行回归;
- 在KK(C+1)维的位置敏感得分映射和4KK维的位置敏感得分映射上面分别执行位置敏感的ROI池化操作(Position-Sensitive Rol Pooling,这里使用的是平均池化操作),获得对应的类别和位置信息。

性能提升:
R-FCN作为Faster RCNN的改进版,主要对原有的ROI Pooling层进行改进和移位,使得不会存在众多region proposal都得经过全连接层的情况,这样就加快了速度。另一方面改进是将原来的VGG16类型的主网络换成ResNet系列网络。而算法的另一部分RPN网络则和Faster RCNN基本差不多。

部分代码实现:
完整代码可以参考这篇文章:R-FCN Python版本实现
Demo_RFCN.py
import _init_paths
from fast_rcnn.config import cfg
from fast_rcnn.test import im_detect
from fast_rcnn.nms_wrapper import nms
from utils.timer import Timer
import matplotlib.pyplot as plt
import numpy as np
import scipy.io as sio
import caffe, os, sys, cv2
import argparse
CLASSES = ('__background__',
'aeroplane', 'bicycle', 'bird', 'boat',
'bottle', 'bus', 'car', 'cat', 'chair',
'cow', 'diningtable', 'dog', 'horse',
'motorbike', 'person', 'pottedplant',
'sheep', 'sofa', 'train', 'tvmonitor')
NETS = {'ResNet-101': ('ResNet-101',
'resnet101_rfcn_final.caffemodel'),
'ResNet-50': ('ResNet-50',
'resnet50_rfcn_final.caffemodel')}
def vis_detections(im, items):
"""Draw detected bounding boxes."""
rects = []
cas = []
for item in items:
class_name = item[0]
dets = item[1]
thresh = item[2]
inds = np.where(dets[:, -1] >= thresh)[0]
if len(inds) == 0:
continue
for i in inds:
bbox = dets[i, :4]
score = dets[i, -1]
rect = [bbox[0], bbox[1], bbox[2] - bbox[0], bbox[3] - bbox[1]]
rects.append(rect)
cs = [class_name, score]
cas.append(cs)
return rects, cas
def demo(net, image_name):
"""Detect object classes in an image using pre-computed object proposals."""
# Load the demo image
im_file = os.path.join(cfg.DATA_DIR, 'demo', image_name)
im = cv2.imread(im_file)
# Detect all object classes and regress object bounds
timer = Timer()
timer.tic()
scores, boxes = im_detect(net, im)
timer.toc()
print ('Detection took {:.3f}s for '
'{:d} object proposals').format(timer.total_time, boxes.shape[0])
# Visualize detections for each class
CONF_THRESH = 0.8
NMS_THRESH = 0.3
cand = []
for cls_ind, cls in enumerate(CLASSES[1:]):
cls_ind += 1 # because we skipped background
cls_boxes = boxes[:, 4:8]
cls_scores = scores[:, cls_ind]
dets = np.hstack((cls_boxes,
cls_scores[:, np.newaxis])).astype(np.float32)
keep = nms(dets, NMS_THRESH)
dets = dets[keep, :]
one = [cls, dets, CONF_THRESH]
cand.append(one)
rects, cas = vis_detections(im, cand)
fig, ax = plt.subplots(figsize=(12, 12))
im = im[:, :, (2, 1, 0)]
ax.imshow(im, aspect='equal')
for i in range(len(rects)):
r = rects[i]
ax.add_patch(
plt.Rectangle((r[0], r[1]), r[2], r[3] ,
fill=False, edgecolor='red', linewidth=3.5))
c = cas[i]
ax.text(r[0], r[1] - 2,
'{:s} {:.3f}'.format(c[0], c[1]),
bbox=dict(facecolor='blue', alpha=0.5),
fontsize=14, color='white')
plt.axis('off')
plt.tight_layout()
plt.draw()
plt.show()
def parse_args():
"""Parse input arguments."""
parser = argparse.ArgumentParser(description='Faster R-CNN demo')
parser.add_argument('--gpu', dest='gpu_id', help='GPU device id to use [0]',
default=0, type=int)
parser.add_argument('--cpu', dest='cpu_mode',
help='Use CPU mode (overrides --gpu)',
action='store_true')
parser.add_argument('--net', dest='demo_net', help='Network to use [ResNet-101]',
choices=NETS.keys(), default='ResNet-101')
args = parser.parse_args()
return args
if __name__ == '__main__':
cfg.TEST.HAS_RPN = True # Use RPN for proposals
args = parse_args()
prototxt = os.path.join(cfg.MODELS_DIR, NETS[args.demo_net][0],
'rfcn_end2end', 'test_agnostic.prototxt')
caffemodel = os.path.join(cfg.DATA_DIR, 'rfcn_models',
NETS[args.demo_net][1])
if not os.path.isfile(caffemodel):
raise IOError(('{:s} not found.\n').format(caffemodel))
if args.cpu_mode:
caffe.set_mode_cpu()
else:
caffe.set_mode_gpu()
caffe.set_device(args.gpu_id)
cfg.GPU_ID = args.gpu_id
net = caffe.Net(prototxt, caffemodel, caffe.TEST)
print '\n\nLoaded network {:s}'.format(caffemodel)
# Warmup on a dummy image
im = 128 * np.ones((300, 500, 3), dtype=np.uint8)
for i in xrange(2):
_, _= im_detect(net, im)
im_names = ['000456.jpg', '000542.jpg', '001150.jpg',
'001763.jpg', '004545.jpg']
for im_name in im_names:
print '~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~'
print 'Demo for data/demo/{}'.format(im_name)
demo(net, im_name)
三、YOLO系列
YOLO目标检测是一种突出且优秀的算法,其为“you only look once”的缩写,意为只需浏览一次即可识别出图中物体的类别与位置,且完美地平衡了检测速度和精度之间的关系。YOLO也由最初的YOLO v1发展到现在的YOLO v5。
1.YOLO v1
YOLO v1(You Only Look Once: Unified, Real-Time Object Detection),是Joseph Redmon和Ali Farhadi等人于2016年提出的基于单个神经网络的目标检测系统。核心思想是将整张图片作为网络的输入(类似于Faster-RCNN),直接在输出层对BBox的位置和类别进行回归。
论文:You Only Look Once: Unified, Real-Time Object Detection
YOLO v1算法流程:
- 将一幅图像分成SxS个网格(grid cell),如果某个object的中心 落在这个网格中,则这个网格就负责预测这个object。
- 每个网络需要预测B个BBox的位置信息和confidence(置信度)信息,一个BBox对应着四个位置信息和一个confidence信息。confidence代表了所预测的box中含有object的置信度和这个box预测的有多准两重信息。
- 每个bounding box要预测(x, y, w, h)和confidence共5个值,每个网格还要预测一个类别信息,记为C类。则SxS个网格,每个网格要预测B个bounding box还要预测C个categories。
- 输出就是SS(5*B+C)的一个tensor。(注意:class信息是针对每个网格的,confidence信息是针对每个bounding box的。)
- 得到每个box的class-specific confidence score以后,设置阈值,滤掉得分低的boxes,对保留的boxes进行NMS处理,就得到最终的检测结果。
代码下载:YOLO v1
build_network类:搭建YOLO v1网络,代码如下:
def build_network(self, #用slim构建网络,简单高效
images,
num_outputs,
alpha,
keep_prob=0.5,
is_training=True,
scope='yolo'):
with tf.variable_scope(scope):
with slim.arg_scope(
[slim.conv2d, slim.fully_connected], #卷积层加上全连接层
activation_fn=leaky_relu(alpha), #用的是leaky_relu激活函数
weights_regularizer=slim.l2_regularizer(0.0005), #L2正则化,防止过拟合
weights_initializer=tf.truncated_normal_initializer(0.0, 0.01) #权重初始化
):
#这里先执行填充操作
# t = [[2, 3, 4], [5, 6, 7]], paddings = [[1, 1], [2, 2]],mode = "CONSTANT"
#
# 那么sess.run(tf.pad(t, paddings, "CONSTANT"))
# 的输出结果为:
#
# array([[0, 0, 0, 0, 0, 0, 0],
# [0, 0, 2, 3, 4, 0, 0],
# [0, 0, 5, 6, 7, 0, 0],
# [0, 0, 0, 0, 0, 0, 0]], dtype=int32)
#
# 可以看到,上,下,左,右分别填充了1, 1, 2, 2
# 行刚好和paddings = [[1, 1], [2, 2]]
# 相等,零填充
#因为这里有4维,batch和channel维没有填充,只填充了image_height,image_width这两个维度,0填充
net = tf.pad(
images, np.array([[0, 0], [3, 3], [3, 3], [0, 0]]),
name='pad_1')
net = slim.conv2d(
net, 64, 7, 2, padding='VALID', scope='conv_2')
#这里的64是指卷积核个数,7是指卷积核的高度和宽度,2是指步长,valid表示没有填充
net = slim.max_pool2d(net, 2, padding='SAME', scope='pool_3') #max_pool, 大小2*2, stride:2
net = slim.conv2d(net, 192, 3, scope='conv_4') #这里的192是指卷积核的个数,3是指卷积核的高度和宽度,默认的步长为1
net = slim.max_pool2d(net, 2, padding='SAME', scope='pool_5') #max_pool,大小为2*2,strides:2
net = slim.conv2d(net, 128, 1, scope='conv_6') #128个卷积核,大小为1*1,默认步长为1
net = slim.conv2d(net, 256, 3, scope='conv_7') #256个卷积核,大小为3*3,默认步长为1
net = slim.conv2d(net, 256, 1, scope='conv_8') #256个卷积核,大小为1*1,默认步长为1
net = slim.conv2d(net, 512, 3, scope='conv_9') #512个卷积核,大小为3*3,默认步长为3
net = slim.max_pool2d(net, 2, padding='SAME', scope='pool_10') #max_pool, 大小为2*2,stride:2
net = slim.conv2d(net, 256, 1, scope='conv_11') #256个卷积核,大小为1*1, 默认步长为1
net = slim.conv2d(net, 512, 3, scope='conv_12') #512个卷积核,大小为3*3,默认步长为1
net = slim.conv2d(net, 256, 1, scope='conv_13') #256个卷积核,大小为1*1, 默认步长为1
net = slim.conv2d(net, 512, 3, scope='conv_14') #512个卷积核,大小为3*3, 默认步长为1
net = slim.conv2d(net, 256, 1, scope='conv_15') #256个卷积核,大小为1*1, 默认步长为1
net = slim.conv2d(net, 512, 3, scope='conv_16') #512个卷积核,大小为3*3, 默认步长为1
net = slim.conv2d(net, 256, 1, scope='conv_17') #256个卷积核,大小为1*1, 默认步长为1
net = slim.conv2d(net, 512, 3, scope='conv_18') #512个卷积核,大小为3*3, 默认步长为1
net = slim.conv2d(net, 512, 1, scope='conv_19') #256个卷积核,大小为1*1, 默认步长为1
net = slim.conv2d(net, 1024, 3, scope='conv_20') #1024个卷积核,大小为3*3,默认步长为1
net = slim.max_pool2d(net, 2, padding='SAME', scope='pool_21') # max_pool, 大小为2*2,strides: 2
net = slim.conv2d(net, 512, 1, scope='conv_22') #512卷积核,大小为1*1,默认步长为1
net = slim.conv2d(net, 1024, 3, scope='conv_23') #1024卷积核,大小为3*3,默认步长1
net = slim.conv2d(net, 512, 1, scope='conv_24') #512卷积核,大小为1*1,默认步长1
net = slim.conv2d(net, 1024, 3, scope='conv_25') #1024卷积核,大小为3*3, 默认步长为1
net = slim.conv2d(net, 1024, 3, scope='conv_26') #1024卷积核,大小为3*3,默认步长为1
net = tf.pad(
net, np.array([[0, 0], [1, 1], [1, 1], [0, 0]]),
name='pad_27') #padding, 第一个维度batch和第四个维度channels不用管,只padding卷积核的高度和宽度
net = slim.conv2d(
net, 1024, 3, 2, padding='VALID', scope='conv_28') #1024卷积核,大小3*3,步长为2
net = slim.conv2d(net, 1024, 3, scope='conv_29') #1024卷积核,大小为3*3,默认步长为1
net = slim.conv2d(net, 1024, 3, scope='conv_30') #1024卷积核,大小为3*3,默认步长为1
net = tf.transpose(net, [0, 3, 1, 2], name='trans_31') #转置,由[batch, image_height,image_width,channels]变成[bacth, channels, image_height,image_width]
net = slim.flatten(net, scope='flat_32') #将输入扁平化,但保留batch_size, 假设第一位是batch,实际上第一维也是batch
net = slim.fully_connected(net, 512, scope='fc_33') #全连接层,神经元个数
net = slim.fully_connected(net, 4096, scope='fc_34') #全连接层,神经元个数
net = slim.dropout( #dropout,防止过拟合
net, keep_prob=keep_prob, is_training=is_training,
scope='dropout_35')
net = slim.fully_connected( #全连接层
net, num_outputs, activation_fn=None, scope='fc_36')
return net #net shape[7*7*30]
2.YOLO v2
YOLO v2相对v1版本,在继续保持处理速度的基础上,从预测更准确,速度更快,识别对象更多,这三个方面进行了改进。其中识别更多对象也就是扩展到能够检测9000种不同对象,称之为YOLO 9000。
论文:YOLO v2(YOLO 9000)
改进点:
- Batch Normalization(批量归一化)
- High resolution classifier(高分辨率图像分类器)
- Convolution with anchor boxes(使用先验框)
- Dimension clusters(聚类提取先验框的尺度信息)
- Direct location prediction(约束预测边框的位置)
- Fine-Grained Features(passthrough层检测细粒度特征)
- Multi-ScaleTraining(多尺度图像训练)

代码下载:YOLO v2
搭建YOLO v2网络,代码如下:
class Yolov2(YoloABC):
def __init__(self, num_classes=20, weights_file=None, input_channels=3,
anchors = [(42.31,55.41), (102.17,128.30), (161.79,259.17), (303.08,154.90), (359.56,320.23)],
anchors_mask=[(0,1,2,3,4)], train_flag=1, clear=False, test_args=None):
""" Network initialisation """
super().__init__()
# Parameters
self.num_classes = num_classes
self.anchors = anchors
self.anchors_mask = anchors_mask
self.nloss = len(self.anchors_mask)
self.train_flag = train_flag
self.test_args = test_args
self.loss = None
self.postprocess = None
self.backbone = backbone.Darknet19()
self.head = head.Yolov2(num_anchors=len(anchors_mask[0]), num_classes=num_classes)
if weights_file is not None:
self.load_weights(weights_file, clear)
else:
self.init_weights(slope=0.1)
def _forward(self, x):
middle_feats = self.backbone(x)
features = self.head(middle_feats) #模型最后的输出向量,是concat好的输出13*13*1024
loss_fn = loss.RegionLoss #进入损失函数
self.compose(x, features, loss_fn)
return features
def modules_recurse(self, mod=None):
""" This function will recursively loop over all module children.
Args:
mod (torch.nn.Module, optional): Module to loop over; Default **self**
"""
if mod is None:
mod = self
for module in mod.children():
if isinstance(module, (nn.ModuleList, nn.Sequential, backbone.Darknet19, head.Yolov2)):
yield from self.modules_recurse(module)
else:
yield module

3.YOLO v3
YOLO v3的先验检测(Prior detection)系统将分类器或定位器重新用于执行检测任务。他们将模型应用于图像的多个位置和尺度。而那些评分较高的区域就可以视为检测结果。此外,相对于其它目标检测方法,我们使用了完全不同的方法。我们将一个单神经网络应用于整张图像,该网络将图像划分为不同的区域,因而预测每一块区域的边界框和概率,这些边界框会通过预测的概率加权。我们的模型相比于基于分类器的系统有一些优势。它在测试时会查看整个图像,所以它的预测利用了图像中的全局信息。与需要数千张单一目标图像的 R-CNN 不同,它通过单一网络评估进行预测。 YOLO v3 检测非常快,一般它比 R-CNN 快 1000 倍、比 Fast R-CNN 快 100 倍。
论文:YOLOv3: An Incremental Improvement
改进点:
- 多尺度预测 (引入FPN)。
- 更好的基础分类网络(darknet-53, 类似于ResNet引入残差结构)。
- 分类器不在使用Softmax,分类损失采用binary cross-entropy loss(二分类交叉损失熵)
通过特征提取网络对输入特征提取特征,得到特定大小的特征图输出。输入图像分成13×13的grid cell,接着如果真实框中某个object的中心坐标落在某个grid cell中,那么就由该grid cell来预测该object。每个object有固定数量的bounding box,YOLO v3中有三个bounding box,使用逻辑回归确定用来预测的回归框。
YOLO v3算法流程:
1.从特征获取预测结果:yolov3提取多特征层进行目标检测,一共提取三个特征层,三个特征层位于主干特征提取网络darknet53的不同位置,分别位于中间层,中下层,底层,三个特征层的shape分别为(52,52,256)、(26,26,512)、(13,13,1024),这三个特征层后面用于与上采样后的其他特征层堆叠拼接(Concat);第三个特征层(13,13,1024)进行5次卷积处理(为了特征提取),处理完后一部分用于卷积+上采样UpSampling,另一部分用于输出对应的预测结果(13,13,75),Conv2D 3×3和Conv2D1×1两个卷积起通道调整的作用,调整成输出需要的大小。卷积+上采样后得到(26,26,256)的特征层,然后与Darknet53网络中的特征层(26,26,512)进行拼接,得到的shape为(26,26,768),再进行5次卷积,处理完后一部分用于卷积上采样,另一部分用于输出对应的预测结果(26,26,75),Conv2D 3×3和Conv2D1×1同上为通道调整之后再将3中卷积+上采样的特征层与shape为(52,52,256)的特征层拼接(Concat),再进行卷积得到shape为(52,52,128)的特征层,最后再Conv2D 3×3和Conv2D1×1两个卷积,得到(52,52,75)特征层。
2.预测结果的解码:解码过程就是计算得出最后显示的边界框的坐标bx,by,以及宽高bw,bh,这样就得出了边界框的位置。
3.对预测出的边界框得分排序与非极大抑制筛选:取出每一类得分大于一定阈值的框和得分进行排序。利用框的位置和得分进行非极大抑制。最后可以得出概率最大的边界框,也就是最后显示出的框。

完整代码:YOLO v3
搭建YOLO v3网络,代码如下:
def __build_nework(self, input_data):
"""经过Darknet-53后,分出三个分支y1,y2,y3"""
route_1, route_2, input_data = backbone.darknet53(input_data, self.trainable)
#(Conv + BN + leaky_relu)×5
input_data = common.convolutional(input_data, (1, 1, 1024, 512), self.trainable, 'conv52')
input_data = common.convolutional(input_data, (3, 3, 512, 1024), self.trainable, 'conv53')
input_data = common.convolutional(input_data, (1, 1, 1024, 512), self.trainable, 'conv54')
input_data = common.convolutional(input_data, (3, 3, 512, 1024), self.trainable, 'conv55')
input_data = common.convolutional(input_data, (1, 1, 1024, 512), self.trainable, 'conv56')
conv_lobj_branch = common.convolutional(input_data, (3, 3, 512, 1024), self.trainable, name='conv_lobj_branch')
#y1的输出[None,13,13,3*(80+5)=255],用于检测大物体
conv_lbbox = common.convolutional(conv_lobj_branch, (1, 1, 1024, 3*(self.num_class + 5)),
trainable=self.trainable, name='conv_lbbox', activate=False, bn=False)
input_data = common.convolutional(input_data, (1, 1, 512, 256), self.trainable, 'conv57')
input_data = common.upsample(input_data, name='upsample0', method=self.upsample_method)
#第一个concat操作
with tf.variable_scope('route_1'):
input_data = tf.concat([input_data, route_2], axis=-1)
input_data = common.convolutional(input_data, (1, 1, 768, 256), self.trainable, 'conv58')
input_data = common.convolutional(input_data, (3, 3, 256, 512), self.trainable, 'conv59')
input_data = common.convolutional(input_data, (1, 1, 512, 256), self.trainable, 'conv60')
input_data = common.convolutional(input_data, (3, 3, 256, 512), self.trainable, 'conv61')
input_data = common.convolutional(input_data, (1, 1, 512, 256), self.trainable, 'conv62')
conv_mobj_branch = common.convolutional(input_data, (3, 3, 256, 512), self.trainable, name='conv_mobj_branch' )
#y2的输出[None,26,26,3*(80+5)=255],用于检测中等物体
conv_mbbox = common.convolutional(conv_mobj_branch, (1, 1, 512, 3*(self.num_class + 5)),
trainable=self.trainable, name='conv_mbbox', activate=False, bn=False)
input_data = common.convolutional(input_data, (1, 1, 256, 128), self.trainable, 'conv63')
input_data = common.upsample(input_data, name='upsample1', method=self.upsample_method)
#第二个concat操作
with tf.variable_scope('route_2'):
input_data = tf.concat([input_data, route_1], axis=-1)
input_data = common.convolutional(input_data, (1, 1, 384, 128), self.trainable, 'conv64')
input_data = common.convolutional(input_data, (3, 3, 128, 256), self.trainable, 'conv65')
input_data = common.convolutional(input_data, (1, 1, 256, 128), self.trainable, 'conv66')
input_data = common.convolutional(input_data, (3, 3, 128, 256), self.trainable, 'conv67')
input_data = common.convolutional(input_data, (1, 1, 256, 128), self.trainable, 'conv68')
conv_sobj_branch = common.convolutional(input_data, (3, 3, 128, 256), self.trainable, name='conv_sobj_branch')
#y3的输出[None,52,52,3*(80+5)=255],用于检测小物体
conv_sbbox = common.convolutional(conv_sobj_branch, (1, 1, 256, 3*(self.num_class + 5)),
trainable=self.trainable, name='conv_sbbox', activate=False, bn=False)
return conv_lbbox, conv_mbbox, conv_sbbox
主干网络darknet.py 53层
from __future__ import division
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
import numpy as np
from util import *
def get_test_input():
img = cv2.imread("dog-cycle-car.png")
img = cv2.resize(img, (416,416)) #Resize to the input dimension
img_ = img[:,:,::-1].transpose((2,0,1)) #img是【h,w,channel】,这里的img[:,:,::-1]是将第三个维度channel从opencv的BGR转化为pytorch的RGB,然后transpose((2,0,1))的意思是将[height,width,channel]->[channel,height,width]
img_ = img_[np.newaxis,:,:,:]/255.0 #Add a channel at 0 (for batch) | Normalise
img_ = torch.from_numpy(img_).float() #Convert to float
img_ = Variable(img_) # Convert to Variable
return img_
def parse_cfg(cfgfile):
"""
输入: 配置文件路径
返回值: 列表对象,其中每一个元素为一个字典类型对应于一个要建立的神经网络模块(层)
"""
# 加载文件并过滤掉文本中多余内容
file = open(cfgfile, 'r')
lines = file.read().split('\n') # store the lines in a list等价于readlines
lines = [x for x in lines if len(x) > 0] # 去掉空行
lines = [x for x in lines if x[0] != '#'] # 去掉以#开头的注释行
lines = [x.rstrip().lstrip() for x in lines] # 去掉左右两边的空格(rstricp是去掉右边的空格,lstrip是去掉左边的空格)
# cfg文件中的每个块用[]括起来最后组成一个列表,一个block存储一个块的内容,即每个层用一个字典block存储。
block = {}
blocks = []
for line in lines:
if line[0] == "[": # 这是cfg文件中一个层(块)的开始
if len(block) != 0: # 如果块内已经存了信息, 说明是上一个块的信息还没有保存
blocks.append(block) # 那么这个块(字典)加入到blocks列表中去
block = {} # 覆盖掉已存储的block,新建一个空白块存储描述下一个块的信息(block是字典)
block["type"] = line[1:-1].rstrip() # 把cfg的[]中的块名作为键type的值
else:
key,value = line.split("=") #按等号分割
block[key.rstrip()] = value.lstrip()#左边是key(去掉右空格),右边是value(去掉左空格),形成一个block字典的键值对
blocks.append(block) # 退出循环,将最后一个未加入的block加进去
# print('\n\n'.join([repr(x) for x in blocks]))
return blocks
# 配置文件定义了6种不同type
# 'net': 相当于超参数,网络全局配置的相关参数
# {'convolutional', 'net', 'route', 'shortcut', 'upsample', 'yolo'}
# cfg = parse_cfg("cfg/yolov3.cfg")
# print(cfg)
class EmptyLayer(nn.Module):
"""
为shortcut layer / route layer 准备, 具体功能不在此实现,在Darknet类的forward函数中有体现
"""
def __init__(self):
super(EmptyLayer, self).__init__()
class DetectionLayer(nn.Module):
'''yolo 检测层的具体实现, 在特征图上使用锚点预测目标区域和类别, 功能函数在predict_transform中'''
def __init__(self, anchors):
super(DetectionLayer, self).__init__()
self.anchors = anchors
def create_modules(blocks):
net_info = blocks[0] # blocks[0]存储了cfg中[net]的信息,它是一个字典,获取网络输入和预处理相关信息
module_list = nn.ModuleList() # module_list用于存储每个block,每个block对应cfg文件中一个块,类似[convolutional]里面就对应一个卷积块
prev_filters = 3 #初始值对应于输入数据3通道,用来存储我们需要持续追踪被应用卷积层的卷积核数量(上一层的卷积核数量(或特征图深度))
output_filters = [] #我们不仅需要追踪前一层的卷积核数量,还需要追踪之前每个层。随着不断地迭代,我们将每个模块的输出卷积核数量添加到 output_filters 列表上。
for index, x in enumerate(blocks[1:]): #这里,我们迭代block[1:] 而不是blocks,因为blocks的第一个元素是一个net块,它不属于前向传播。
module = nn.Sequential()# 这里每个块用nn.sequential()创建为了一个module,一个module有多个层
#check the type of block
#create a new module for the block
#append to module_list
if (x["type"] == "convolutional"):
''' 1. 卷积层 '''
# 获取激活函数/批归一化/卷积层参数(通过字典的键获取值)
activation = x["activation"]
try:
batch_normalize = int(x["batch_normalize"])
bias = False#卷积层后接BN就不需要bias
except:
batch_normalize = 0
bias = True #卷积层后无BN层就需要bias
filters= int(x["filters"])
padding = int(x["pad"])
kernel_size = int(x["size"])
stride = int(x["stride"])
if padding:
pad = (kernel_size - 1) // 2
else:
pad = 0
# 开始创建并添加相应层
# Add the convolutional layer
# nn.Conv2d(self, in_channels, out_channels, kernel_size, stride=1, padding=0, bias=True)
conv = nn.Conv2d(prev_filters, filters, kernel_size, stride, pad, bias = bias)
module.add_module("conv_{0}".format(index), conv)
#Add the Batch Norm Layer
if batch_normalize:
bn = nn.BatchNorm2d(filters)
module.add_module("batch_norm_{0}".format(index), bn)
#Check the activation.
#It is either Linear or a Leaky ReLU for YOLO
# 给定参数负轴系数0.1
if activation == "leaky":
activn = nn.LeakyReLU(0.1, inplace = True)
module.add_module("leaky_{0}".format(index), activn)
elif (x["type"] == "upsample"):
'''
2. upsampling layer
没有使用 Bilinear2dUpsampling
实际使用的为最近邻插值
'''
stride = int(x["stride"])#这个stride在cfg中就是2,所以下面的scale_factor写2或者stride是等价的
upsample = nn.Upsample(scale_factor = 2, mode = "nearest")
module.add_module("upsample_{}".format(index), upsample)
# route layer -> Empty layer
# route层的作用:当layer取值为正时,输出这个正数对应的层的特征,如果layer取值为负数,输出route层向后退layer层对应层的特征
elif (x["type"] == "route"):
x["layers"] = x["layers"].split(',')
#Start of a route
start = int(x["layers"][0])
#end, if there exists one.
try:
end = int(x["layers"][1])
except:
end = 0
#Positive anotation: 正值
if start > 0:
start = start - index
if end > 0:# 若end>0,由于end= end - index,再执行index + end输出的还是第end层的特征
end = end - index
route = EmptyLayer()
module.add_module("route_{0}".format(index), route)
if end < 0: #若end<0,则end还是end,输出index+end(而end<0)故index向后退end层的特征。
filters = output_filters[index + start] + output_filters[index + end]
else: #如果没有第二个参数,end=0,则对应下面的公式,此时若start>0,由于start = start - index,再执行index + start输出的还是第start层的特征;若start<0,则start还是start,输出index+start(而start<0)故index向后退start层的特征。
filters= output_filters[index + start]
#shortcut corresponds to skip connection
elif x["type"] == "shortcut":
shortcut = EmptyLayer() #使用空的层,因为它还要执行一个非常简单的操作(加)。没必要更新 filters 变量,因为它只是将前一层的特征图添加到后面的层上而已。
module.add_module("shortcut_{}".format(index), shortcut)
#Yolo is the detection layer
elif x["type"] == "yolo":
mask = x["mask"].split(",")
mask = [int(x) for x in mask]
anchors = x["anchors"].split(",")
anchors = [int(a) for a in anchors]
anchors = [(anchors[i], anchors[i+1]) for i in range(0, len(anchors),2)]
anchors = [anchors[i] for i in mask]
detection = DetectionLayer(anchors)# 锚点,检测,位置回归,分类,这个类见predict_transform中
module.add_module("Detection_{}".format(index), detection)
module_list.append(module)
prev_filters = filters
output_filters.append(filters)
return (net_info, module_list)
class Darknet(nn.Module):
def __init__(self, cfgfile):
super(Darknet, self).__init__()
self.blocks = parse_cfg(cfgfile) #调用parse_cfg函数
self.net_info, self.module_list = create_modules(self.blocks)#调用create_modules函数
def forward(self, x, CUDA):
modules = self.blocks[1:] # 除了net块之外的所有,forward这里用的是blocks列表中的各个block块字典
outputs = {} #We cache the outputs for the route layer
write = 0#write表示我们是否遇到第一个检测。write=0,则收集器尚未初始化,write=1,则收集器已经初始化,我们只需要将检测图与收集器级联起来即可。
for i, module in enumerate(modules):
module_type = (module["type"])
if module_type == "convolutional" or module_type == "upsample":
x = self.module_list[i](x)
elif module_type == "route":
layers = module["layers"]
layers = [int(a) for a in layers]
if (layers[0]) > 0:
layers[0] = layers[0] - i
# 如果只有一层时。从前面的if (layers[0]) > 0:语句中可知,如果layer[0]>0,则输出的就是当前layer[0]这一层的特征,如果layer[0]<0,输出就是从route层(第i层)向后退layer[0]层那一层得到的特征
if len(layers) == 1:
x = outputs[i + (layers[0])]
#第二个元素同理
else:
if (layers[1]) > 0:
layers[1] = layers[1] - i
map1 = outputs[i + layers[0]]
map2 = outputs[i + layers[1]]
x = torch.cat((map1, map2), 1)#第二个参数设为 1,这是因为我们希望将特征图沿anchor数量的维度级联起来。
elif module_type == "shortcut":
from_ = int(module["from"])
x = outputs[i-1] + outputs[i+from_] # 求和运算,它只是将前一层的特征图添加到后面的层上而已
elif module_type == 'yolo':
anchors = self.module_list[i][0].anchors
#从net_info(实际就是blocks[0],即[net])中get the input dimensions
inp_dim = int (self.net_info["height"])
#Get the number of classes
num_classes = int (module["classes"])
#Transform
x = x.data # 这里得到的是预测的yolo层feature map
# 在util.py中的predict_transform()函数利用x(是传入yolo层的feature map),得到每个格子所对应的anchor最终得到的目标
# 坐标与宽高,以及出现目标的得分与每种类别的得分。经过predict_transform变换后的x的维度是(batch_size, grid_size*grid_size*num_anchors, 5+类别数量)
x = predict_transform(x, inp_dim, anchors, num_classes, CUDA)
if not write: #if no collector has been intialised. 因为一个空的tensor无法与一个有数据的tensor进行concatenate操作,
detections = x #所以detections的初始化在有预测值出来时才进行,
write = 1 #用write = 1标记,当后面的分数出来后,直接concatenate操作即可。
else:
'''
变换后x的维度是(batch_size, grid_size*grid_size*num_anchors, 5+类别数量),这里是在维度1上进行concatenate,即按照
anchor数量的维度进行连接,对应教程part3中的Bounding Box attributes图的行进行连接。yolov3中有3个yolo层,所以
对于每个yolo层的输出先用predict_transform()变成每行为一个anchor对应的预测值的形式(不看batch_size这个维度,x剩下的
维度可以看成一个二维tensor),这样3个yolo层的预测值按照每个方框对应的行的维度进行连接。得到了这张图处所有anchor的预测值,后面的NMS等操作可以一次完成
'''
detections = torch.cat((detections, x), 1)# 将在3个不同level的feature map上检测结果存储在 detections 里
outputs[i] = x
return detections
# blocks = parse_cfg('cfg/yolov3.cfg')
# x,y = create_modules(blocks)
# print(y)
def load_weights(self, weightfile):
#Open the weights file
fp = open(weightfile, "rb")
#The first 5 values are header information
# 1. Major version number
# 2. Minor Version Number
# 3. Subversion number
# 4,5. Images seen by the network (during training)
header = np.fromfile(fp, dtype = np.int32, count = 5)# 这里读取first 5 values权重
self.header = torch.from_numpy(header)
self.seen = self.header[3]
weights = np.fromfile(fp, dtype = np.float32)#加载 np.ndarray 中的剩余权重,权重是以float32类型存储的
ptr = 0
for i in range(len(self.module_list)):
module_type = self.blocks[i + 1]["type"] # blocks中的第一个元素是网络参数和图像的描述,所以从blocks[1]开始读入
#If module_type is convolutional load weights
#Otherwise ignore.
if module_type == "convolutional":
model = self.module_list[i]
try:
batch_normalize = int(self.blocks[i+1]["batch_normalize"]) # 当有bn层时,"batch_normalize"对应值为1
except:
batch_normalize = 0
conv = model[0]
if (batch_normalize):
bn = model[1]
#Get the number of weights of Batch Norm Layer
num_bn_biases = bn.bias.numel()
#Load the weights
bn_biases = torch.from_numpy(weights[ptr:ptr + num_bn_biases])
ptr += num_bn_biases
bn_weights = torch.from_numpy(weights[ptr: ptr + num_bn_biases])
ptr += num_bn_biases
bn_running_mean = torch.from_numpy(weights[ptr: ptr + num_bn_biases])
ptr += num_bn_biases
bn_running_var = torch.from_numpy(weights[ptr: ptr + num_bn_biases])
ptr += num_bn_biases
#Cast the loaded weights into dims of model weights.
bn_biases = bn_biases.view_as(bn.bias.data)
bn_weights = bn_weights.view_as(bn.weight.data)
bn_running_mean = bn_running_mean.view_as(bn.running_mean)
bn_running_var = bn_running_var.view_as(bn.running_var)
#Copy the data to model 将从weights文件中得到的权重bn_biases复制到model中(bn.bias.data)
bn.bias.data.copy_(bn_biases)
bn.weight.data.copy_(bn_weights)
bn.running_mean.copy_(bn_running_mean)
bn.running_var.copy_(bn_running_var)
else:#如果 batch_normalize 的检查结果不是 True,只需要加载卷积层的偏置项
#Number of biases
num_biases = conv.bias.numel()
#Load the weights
conv_biases = torch.from_numpy(weights[ptr: ptr + num_biases])
ptr = ptr + num_biases
#reshape the loaded weights according to the dims of the model weights
conv_biases = conv_biases.view_as(conv.bias.data)
#Finally copy the data
conv.bias.data.copy_(conv_biases)
#Let us load the weights for the Convolutional layers
num_weights = conv.weight.numel()
#Do the same as above for weights
conv_weights = torch.from_numpy(weights[ptr:ptr+num_weights])
ptr = ptr + num_weights
conv_weights = conv_weights.view_as(conv.weight.data)
conv.weight.data.copy_(conv_weights)
4.YOLO v4
2020年,YOLO v4是一种单阶段目标检测算法,该算法在YOLO v3的基础上添加了一些新的改进思路,使得其速度与精度都得到了极大的性能提升。主要的改进思路如下所示:
- 输入端:在模型训练阶段,做了一些改进操作,主要包括Mosaic数据增强、cmBN、SAT自对抗训练;
- BackBone基准网络:融合其它检测算法中的一些新思路,主要包括:CSPDarknet53、Mish激活函数、Dropblock;
- Neck中间层:目标检测网络在BackBone与最后的Head输出层之间往往会插入一些层,Yolov4中添加了SPP模块、FPN+PAN结构;
- Head输出层:输出层的锚框机制与YOLOv3相同,主要改进的是训练时的损失函数CIOU_Loss,以及预测框筛选的DIOU_nms。
论文:YOLO v4: Optimal Speed and Accuracy of Object Detection
YOLO v4的结构图和YOLO v3相比,多了CSP结构,PAN结构。蓝色框中为网络中常用的几个模块:
- CBM:YOLO v4网络结构中的最小组件,其由Conv(卷积)+ BN + Mish激活函数组成。
- CBL:YOLO v4网络结构中的最小组件,其由Conv(卷积)+ BN + Leaky relu激活函数组成。
- Res unit:残差组件,借鉴ResNet网络中的残差结构,让网络可以构建的更深。
- CSPX:借鉴CSPNet网络结构,由三个CBM卷积层和X个Res unint模块Concat组成。
- SPP:采用1×1,5×5,9×9,13×13的最大池化的方式,进行多尺度融合。

代码下载:YOLO v4:AB大神Darknet版本的源码实现
YOLOv4代码实现🌞:
# 导入对应的python三方包
import torch
from torch import nn
import torch.nn.functional as F
from tool.torch_utils import *
from tool.yolo_layer import YoloLayer
# Mish激活函数类
class Mish(torch.nn.Module):
def __init__(self):
super().__init__()
def forward(self, x):
x = x * (torch.tanh(torch.nn.functional.softplus(x)))
return x
# 上采样操作类
class Upsample(nn.Module):
def __init__(self):
super(Upsample, self).__init__()
def forward(self, x, target_size, inference=False):
assert (x.data.dim() == 4)
# _, _, tH, tW = target_size
if inference:
#B = x.data.size(0)
#C = x.data.size(1)
#H = x.data.size(2)
#W = x.data.size(3)
return x.view(x.size(0), x.size(1), x.size(2), 1, x.size(3), 1).\
expand(x.size(0), x.size(1), x.size(2), target_size[2] // x.size(2), x.size(3), target_size[3] // x.size(3)).\
contiguous().view(x.size(0), x.size(1), target_size[2], target_size[3])
else:
return F.interpolate(x, size=(target_size[2], target_size[3]), mode='nearest')
# Conv+BN+Activation模块
class Conv_Bn_Activation(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, stride, activation, bn=True, bias=False):
super().__init__()
pad = (kernel_size - 1) // 2
self.conv = nn.ModuleList()
if bias:
self.conv.append(nn.Conv2d(in_channels, out_channels, kernel_size, stride, pad))
else:
self.conv.append(nn.Conv2d(in_channels, out_channels, kernel_size, stride, pad, bias=False))
if bn:
self.conv.append(nn.BatchNorm2d(out_channels))
if activation == "mish":
self.conv.append(Mish())
elif activation == "relu":
self.conv.append(nn.ReLU(inplace=True))
elif activation == "leaky":
self.conv.append(nn.LeakyReLU(0.1, inplace=True))
elif activation == "linear":
pass
else:
print("activate error !!! {} {} {}".format(sys._getframe().f_code.co_filename,
sys._getframe().f_code.co_name, sys._getframe().f_lineno))
def forward(self, x):
for l in self.conv:
x = l(x)
return x
# Res残差块类
class ResBlock(nn.Module):
"""
Sequential residual blocks each of which consists of \
two convolution layers.
Args:
ch (int): number of input and output channels.
nblocks (int): number of residual blocks.
shortcut (bool): if True, residual tensor addition is enabled.
"""
def __init__(self, ch, nblocks=1, shortcut=True):
super().__init__()
self.shortcut = shortcut
self.module_list = nn.ModuleList()
for i in range(nblocks):
resblock_one = nn.ModuleList()
resblock_one.append(Conv_Bn_Activation(ch, ch, 1, 1, 'mish'))
resblock_one.append(Conv_Bn_Activation(ch, ch, 3, 1, 'mish'))
self.module_list.append(resblock_one)
def forward(self, x):
for module in self.module_list:
h = x
for res in module:
h = res(h)
x = x + h if self.shortcut else h
return x
# 下采样方法1
class DownSample1(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = Conv_Bn_Activation(3, 32, 3, 1, 'mish')
self.conv2 = Conv_Bn_Activation(32, 64, 3, 2, 'mish')
self.conv3 = Conv_Bn_Activation(64, 64, 1, 1, 'mish')
# [route]
# layers = -2
self.conv4 = Conv_Bn_Activation(64, 64, 1, 1, 'mish')
self.conv5 = Conv_Bn_Activation(64, 32, 1, 1, 'mish')
self.conv6 = Conv_Bn_Activation(32, 64, 3, 1, 'mish')
# [shortcut]
# from=-3
# activation = linear
self.conv7 = Conv_Bn_Activation(64, 64, 1, 1, 'mish')
# [route]
# layers = -1, -7
self.conv8 = Conv_Bn_Activation(128, 64, 1, 1, 'mish')
def forward(self, input):
x1 = self.conv1(input)
x2 = self.conv2(x1)
x3 = self.conv3(x2)
# route -2
x4 = self.conv4(x2)
x5 = self.conv5(x4)
x6 = self.conv6(x5)
# shortcut -3
x6 = x6 + x4
x7 = self.conv7(x6)
# [route]
# layers = -1, -7
x7 = torch.cat([x7, x3], dim=1)
x8 = self.conv8(x7)
return x8
# 下采样方法2
class DownSample2(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = Conv_Bn_Activation(64, 128, 3, 2, 'mish')
self.conv2 = Conv_Bn_Activation(128, 64, 1, 1, 'mish')
# r -2
self.conv3 = Conv_Bn_Activation(128, 64, 1, 1, 'mish')
self.resblock = ResBlock(ch=64, nblocks=2)
# s -3
self.conv4 = Conv_Bn_Activation(64, 64, 1, 1, 'mish')
# r -1 -10
self.conv5 = Conv_Bn_Activation(128, 128, 1, 1, 'mish')
def forward(self, input):
x1 = self.conv1(input)
x2 = self.conv2(x1)
x3 = self.conv3(x1)
r = self.resblock(x3)
x4 = self.conv4(r)
x4 = torch.cat([x4, x2], dim=1)
x5 = self.conv5(x4)
return x5
# 下采样方法3
class DownSample3(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = Conv_Bn_Activation(128, 256, 3, 2, 'mish')
self.conv2 = Conv_Bn_Activation(256, 128, 1, 1, 'mish')
self.conv3 = Conv_Bn_Activation(256, 128, 1, 1, 'mish')
self.resblock = ResBlock(ch=128, nblocks=8)
self.conv4 = Conv_Bn_Activation(128, 128, 1, 1, 'mish')
self.conv5 = Conv_Bn_Activation(256, 256, 1, 1, 'mish')
def forward(self, input):
x1 = self.conv1(input)
x2 = self.conv2(x1)
x3 = self.conv3(x1)
r = self.resblock(x3)
x4 = self.conv4(r)
x4 = torch.cat([x4, x2], dim=1)
x5 = self.conv5(x4)
return x5
# 下采样方法4
class DownSample4(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = Conv_Bn_Activation(256, 512, 3, 2, 'mish')
self.conv2 = Conv_Bn_Activation(512, 256, 1, 1, 'mish')
self.conv3 = Conv_Bn_Activation(512, 256, 1, 1, 'mish')
self.resblock = ResBlock(ch=256, nblocks=8)
self.conv4 = Conv_Bn_Activation(256, 256, 1, 1, 'mish')
self.conv5 = Conv_Bn_Activation(512, 512, 1, 1, 'mish')
def forward(self, input):
x1 = self.conv1(input)
x2 = self.conv2(x1)
x3 = self.conv3(x1)
r = self.resblock(x3)
x4 = self.conv4(r)
x4 = torch.cat([x4, x2], dim=1)
x5 = self.conv5(x4)
return x5
# 下采样方法5
class DownSample5(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = Conv_Bn_Activation(512, 1024, 3, 2, 'mish')
self.conv2 = Conv_Bn_Activation(1024, 512, 1, 1, 'mish')
self.conv3 = Conv_Bn_Activation(1024, 512, 1, 1, 'mish')
self.resblock = ResBlock(ch=512, nblocks=4)
self.conv4 = Conv_Bn_Activation(512, 512, 1, 1, 'mish')
self.conv5 = Conv_Bn_Activation(1024, 1024, 1, 1, 'mish')
def forward(self, input):
x1 = self.conv1(input)
x2 = self.conv2(x1)
x3 = self.conv3(x1)
r = self.resblock(x3)
x4 = self.conv4(r)
x4 = torch.cat([x4, x2], dim=1)
x5 = self.conv5(x4)
return x5
# Neck网络类
class Neck(nn.Module):
def __init__(self, inference=False):
super().__init__()
self.inference = inference
self.conv1 = Conv_Bn_Activation(1024, 512, 1, 1, 'leaky')
self.conv2 = Conv_Bn_Activation(512, 1024, 3, 1, 'leaky')
self.conv3 = Conv_Bn_Activation(1024, 512, 1, 1, 'leaky')
# SPP
self.maxpool1 = nn.MaxPool2d(kernel_size=5, stride=1, padding=5 // 2)
self.maxpool2 = nn.MaxPool2d(kernel_size=9, stride=1, padding=9 // 2)
self.maxpool3 = nn.MaxPool2d(kernel_size=13, stride=1, padding=13 // 2)
# R -1 -3 -5 -6
# SPP
self.conv4 = Conv_Bn_Activation(2048, 512, 1, 1, 'leaky')
self.conv5 = Conv_Bn_Activation(512, 1024, 3, 1, 'leaky')
self.conv6 = Conv_Bn_Activation(1024, 512, 1, 1, 'leaky')
self.conv7 = Conv_Bn_Activation(512, 256, 1, 1, 'leaky')
# UP
self.upsample1 = Upsample()
# R 85
self.conv8 = Conv_Bn_Activation(512, 256, 1, 1, 'leaky')
# R -1 -3
self.conv9 = Conv_Bn_Activation(512, 256, 1, 1, 'leaky')
self.conv10 = Conv_Bn_Activation(256, 512, 3, 1, 'leaky')
self.conv11 = Conv_Bn_Activation(512, 256, 1, 1, 'leaky')
self.conv12 = Conv_Bn_Activation(256, 512, 3, 1, 'leaky')
self.conv13 = Conv_Bn_Activation(512, 256, 1, 1, 'leaky')
self.conv14 = Conv_Bn_Activation(256, 128, 1, 1, 'leaky')
# UP
self.upsample2 = Upsample()
# R 54
self.conv15 = Conv_Bn_Activation(256, 128, 1, 1, 'leaky')
# R -1 -3
self.conv16 = Conv_Bn_Activation(256, 128, 1, 1, 'leaky')
self.conv17 = Conv_Bn_Activation(128, 256, 3, 1, 'leaky')
self.conv18 = Conv_Bn_Activation(256, 128, 1, 1, 'leaky')
self.conv19 = Conv_Bn_Activation(128, 256, 3, 1, 'leaky')
self.conv20 = Conv_Bn_Activation(256, 128, 1, 1, 'leaky')
def forward(self, input, downsample4, downsample3, inference=False):
x1 = self.conv1(input)
x2 = self.conv2(x1)
x3 = self.conv3(x2)
# SPP
m1 = self.maxpool1(x3)
m2 = self.maxpool2(x3)
m3 = self.maxpool3(x3)
spp = torch.cat([m3, m2, m1, x3], dim=1)
# SPP end
x4 = self.conv4(spp)
x5 = self.conv5(x4)
x6 = self.conv6(x5)
x7 = self.conv7(x6)
# UP
up = self.upsample1(x7, downsample4.size(), self.inference)
# R 85
x8 = self.conv8(downsample4)
# R -1 -3
x8 = torch.cat([x8, up], dim=1)
x9 = self.conv9(x8)
x10 = self.conv10(x9)
x11 = self.conv11(x10)
x12 = self.conv12(x11)
x13 = self.conv13(x12)
x14 = self.conv14(x13)
# UP
up = self.upsample2(x14, downsample3.size(), self.inference)
# R 54
x15 = self.conv15(downsample3)
# R -1 -3
x15 = torch.cat([x15, up], dim=1)
x16 = self.conv16(x15)
x17 = self.conv17(x16)
x18 = self.conv18(x17)
x19 = self.conv19(x18)
x20 = self.conv20(x19)
return x20, x13, x6
# Head网络类
class Yolov4Head(nn.Module):
def __init__(self, output_ch, n_classes, inference=False):
super().__init__()
self.inference = inference
self.conv1 = Conv_Bn_Activation(128, 256, 3, 1, 'leaky')
self.conv2 = Conv_Bn_Activation(256, output_ch, 1, 1, 'linear', bn=False, bias=True)
self.yolo1 = YoloLayer(
anchor_mask=[0, 1, 2], num_classes=n_classes,
anchors=[12, 16, 19, 36, 40, 28, 36, 75, 76, 55, 72, 146, 142, 110, 192, 243, 459, 401],
num_anchors=9, stride=8)
# R -4
self.conv3 = Conv_Bn_Activation(128, 256, 3, 2, 'leaky')
# R -1 -16
self.conv4 = Conv_Bn_Activation(512, 256, 1, 1, 'leaky')
self.conv5 = Conv_Bn_Activation(256, 512, 3, 1, 'leaky')
self.conv6 = Conv_Bn_Activation(512, 256, 1, 1, 'leaky')
self.conv7 = Conv_Bn_Activation(256, 512, 3, 1, 'leaky')
self.conv8 = Conv_Bn_Activation(512, 256, 1, 1, 'leaky')
self.conv9 = Conv_Bn_Activation(256, 512, 3, 1, 'leaky')
self.conv10 = Conv_Bn_Activation(512, output_ch, 1, 1, 'linear', bn=False, bias=True)
self.yolo2 = YoloLayer(
anchor_mask=[3, 4, 5], num_classes=n_classes,
anchors=[12, 16, 19, 36, 40, 28, 36, 75, 76, 55, 72, 146, 142, 110, 192, 243, 459, 401],
num_anchors=9, stride=16)
# R -4
self.conv11 = Conv_Bn_Activation(256, 512, 3, 2, 'leaky')
# R -1 -37
self.conv12 = Conv_Bn_Activation(1024, 512, 1, 1, 'leaky')
self.conv13 = Conv_Bn_Activation(512, 1024, 3, 1, 'leaky')
self.conv14 = Conv_Bn_Activation(1024, 512, 1, 1, 'leaky')
self.conv15 = Conv_Bn_Activation(512, 1024, 3, 1, 'leaky')
self.conv16 = Conv_Bn_Activation(1024, 512, 1, 1, 'leaky')
self.conv17 = Conv_Bn_Activation(512, 1024, 3, 1, 'leaky')
self.conv18 = Conv_Bn_Activation(1024, output_ch, 1, 1, 'linear', bn=False, bias=True)
self.yolo3 = YoloLayer(
anchor_mask=[6, 7, 8], num_classes=n_classes,
anchors=[12, 16, 19, 36, 40, 28, 36, 75, 76, 55, 72, 146, 142, 110, 192, 243, 459, 401],
num_anchors=9, stride=32)
def forward(self, input1, input2, input3):
x1 = self.conv1(input1)
x2 = self.conv2(x1)
x3 = self.conv3(input1)
# R -1 -16
x3 = torch.cat([x3, input2], dim=1)
x4 = self.conv4(x3)
x5 = self.conv5(x4)
x6 = self.conv6(x5)
x7 = self.conv7(x6)
x8 = self.conv8(x7)
x9 = self.conv9(x8)
x10 = self.conv10(x9)
# R -4
x11 = self.conv11(x8)
# R -1 -37
x11 = torch.cat([x11, input3], dim=1)
x12 = self.conv12(x11)
x13 = self.conv13(x12)
x14 = self.conv14(x13)
x15 = self.conv15(x14)
x16 = self.conv16(x15)
x17 = self.conv17(x16)
x18 = self.conv18(x17)
if self.inference:
y1 = self.yolo1(x2)
y2 = self.yolo2(x10)
y3 = self.yolo3(x18)
return get_region_boxes([y1, y2, y3])
else:
return [x2, x10, x18]
# 整个Yolov4网络类
class Yolov4(nn.Module):
def __init__(self, yolov4conv137weight=None, n_classes=80, inference=False):
super().__init__()
output_ch = (4 + 1 + n_classes) * 3
# backbone
self.down1 = DownSample1()
self.down2 = DownSample2()
self.down3 = DownSample3()
self.down4 = DownSample4()
self.down5 = DownSample5()
# neck
self.neek = Neck(inference)
# yolov4conv137
if yolov4conv137weight:
_model = nn.Sequential(self.down1, self.down2, self.down3, self.down4, self.down5, self.neek)
pretrained_dict = torch.load(yolov4conv137weight)
model_dict = _model.state_dict()
# 1. filter out unnecessary keys
pretrained_dict = {k1: v for (k, v), k1 in zip(pretrained_dict.items(), model_dict)}
# 2. overwrite entries in the existing state dict
model_dict.update(pretrained_dict)
_model.load_state_dict(model_dict)
# head
self.head = Yolov4Head(output_ch, n_classes, inference)
def forward(self, input):
d1 = self.down1(input)
d2 = self.down2(d1)
d3 = self.down3(d2)
d4 = self.down4(d3)
d5 = self.down5(d4)
x20, x13, x6 = self.neek(d5, d4, d3)
output = self.head(x20, x13, x6)
return output
5.YOLO v5
2020年2月YOLO之父Joseph Redmon宣布退出计算机视觉研究领域,2020年 4月23日YOLO v4 发布,之后2020 年6月10日YOLO v5发布。大家对YOLO V5命名是争议很大,因为YOLOV5相对于YOLOV4来说创新性的地方很少。不过它的性能应该还是有的,现在kaggle上active检测的比赛小麦检测前面的选手大部分用的都是YOLOV5的框架。目前YOLO V5一共有5个版本,Yolov5n、Yolov5s、Yolov5m、Yolov5l和Yolov5x,如上图所示在。表现非常出色,在工业和科研上取得了广泛的应用,本文只是简单介绍YoloV5的模型和实现官网pytorch代码训练自己的目标任务。
YOLO V5主要分为Backbone、Neck和Prediction三个部分:
- Backbone :在不同细粒度的图像上提取特征的卷积神经网络。
- Neck:混合和组合图像特征的网络层,并将图像特征传递到预测层,Neck结构借鉴PAN结构。
- Prediction:对图像特征进行预测,生成边界框和预测类别。

官方代码:YOLO v5
YOLO v5代码实现:
train.py
"""Train a YOLOv5 model on a custom dataset
Usage:
$ python path/to/train.py --data coco128.yaml --weights yolov5s.pt --img 640
"""
import argparse
import logging
import os
import random
import sys
import time
import warnings
from copy import deepcopy
from pathlib import Path
from threading import Thread
import math
import numpy as np
import torch.distributed as dist
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torch.optim.lr_scheduler as lr_scheduler
import torch.utils.data
import yaml
from torch.cuda import amp
from torch.nn.parallel import DistributedDataParallel as DDP
from torch.utils.tensorboard import SummaryWriter
from tqdm import tqdm
FILE = Path(__file__).absolute()
sys.path.append(FILE.parents[0].as_posix()) # add yolov5/ to path
import val # for end-of-epoch mAP
from models.experimental import attempt_load
from models.yolo import Model
from utils.autoanchor import check_anchors
from utils.datasets import create_dataloader
from utils.general import labels_to_class_weights, increment_path, labels_to_image_weights, init_seeds, \
strip_optimizer, get_latest_run, check_dataset, check_file, check_git_status, check_img_size, \
check_requirements, print_mutation, set_logging, one_cycle, colorstr
from utils.google_utils import attempt_download
from utils.loss import ComputeLoss
from utils.plots import plot_images, plot_labels, plot_results, plot_evolution
from utils.torch_utils import ModelEMA, select_device, intersect_dicts, torch_distributed_zero_first, de_parallel
from utils.wandb_logging.wandb_utils import WandbLogger, check_wandb_resume
from utils.metrics import fitness
logger = logging.getLogger(__name__)
LOCAL_RANK = int(os.getenv('LOCAL_RANK', -1)) # https://pytorch.org/docs/stable/elastic/run.html
RANK = int(os.getenv('RANK', -1))
WORLD_SIZE = int(os.getenv('WORLD_SIZE', 1))
def train(hyp, # path/to/hyp.yaml or hyp dictionary
opt,
device,
):
save_dir, epochs, batch_size, weights, single_cls, evolve, data, cfg, resume, noval, nosave, workers, = \
opt.save_dir, opt.epochs, opt.batch_size, opt.weights, opt.single_cls, opt.evolve, opt.data, opt.cfg, \
opt.resume, opt.noval, opt.nosave, opt.workers
# Directories
save_dir = Path(save_dir)
wdir = save_dir / 'weights'
wdir.mkdir(parents=True, exist_ok=True) # make dir
last = wdir / 'last.pt'
best = wdir / 'best.pt'
results_file = save_dir / 'results.txt'
# Hyperparameters
if isinstance(hyp, str):
with open(hyp) as f:
hyp = yaml.safe_load(f) # load hyps dict
logger.info(colorstr('hyperparameters: ') + ', '.join(f'{k}={v}' for k, v in hyp.items()))
# Save run settings
with open(save_dir / 'hyp.yaml', 'w') as f:
yaml.safe_dump(hyp, f, sort_keys=False)
with open(save_dir / 'opt.yaml', 'w') as f:
yaml.safe_dump(vars(opt), f, sort_keys=False)
# Configure
plots = not evolve # create plots
cuda = device.type != 'cpu'
init_seeds(1 + RANK)
with open(data) as f:
data_dict = yaml.safe_load(f) # data dict
# Loggers
loggers = {'wandb': None, 'tb': None} # loggers dict
if RANK in [-1, 0]:
# TensorBoard
if not evolve:
prefix = colorstr('tensorboard: ')
logger.info(f"{prefix}Start with 'tensorboard --logdir {opt.project}', view at http://localhost:6006/")
loggers['tb'] = SummaryWriter(str(save_dir))
# W&B
opt.hyp = hyp # add hyperparameters
run_id = torch.load(weights).get('wandb_id') if weights.endswith('.pt') and os.path.isfile(weights) else None
run_id = run_id if opt.resume else None # start fresh run if transfer learning
wandb_logger = WandbLogger(opt, save_dir.stem, run_id, data_dict)
loggers['wandb'] = wandb_logger.wandb
if loggers['wandb']:
data_dict = wandb_logger.data_dict
weights, epochs, hyp = opt.weights, opt.epochs, opt.hyp # may update weights, epochs if resuming
nc = 1 if single_cls else int(data_dict['nc']) # number of classes
names = ['item'] if single_cls and len(data_dict['names']) != 1 else data_dict['names'] # class names
assert len(names) == nc, '%g names found for nc=%g dataset in %s' % (len(names), nc, data) # check
is_coco = data.endswith('coco.yaml') and nc == 80 # COCO dataset
# Model
pretrained = weights.endswith('.pt')
if pretrained:
with torch_distributed_zero_first(RANK):
weights = attempt_download(weights) # download if not found locally
ckpt = torch.load(weights, map_location=device) # load checkpoint
model = Model(cfg or ckpt['model'].yaml, ch=3, nc=nc, anchors=hyp.get('anchors')).to(device) # create
exclude = ['anchor'] if (cfg or hyp.get('anchors')) and not resume else [] # exclude keys
state_dict = ckpt['model'].float().state_dict() # to FP32
state_dict = intersect_dicts(state_dict, model.state_dict(), exclude=exclude) # intersect
model.load_state_dict(state_dict, strict=False) # load
logger.info('Transferred %g/%g items from %s' % (len(state_dict), len(model.state_dict()), weights)) # report
else:
model = Model(cfg, ch=3, nc=nc, anchors=hyp.get('anchors')).to(device) # create
with torch_distributed_zero_first(RANK):
check_dataset(data_dict) # check
train_path = data_dict['train']
val_path = data_dict['val']
# Freeze
freeze = [] # parameter names to freeze (full or partial)
for k, v in model.named_parameters():
v.requires_grad = True # train all layers
if any(x in k for x in freeze):
print('freezing %s' % k)
v.requires_grad = False
# Optimizer
nbs = 64 # nominal batch size
accumulate = max(round(nbs / batch_size), 1) # accumulate loss before optimizing
hyp['weight_decay'] *= batch_size * accumulate / nbs # scale weight_decay
logger.info(f"Scaled weight_decay = {hyp['weight_decay']}")
pg0, pg1, pg2 = [], [], [] # optimizer parameter groups
for k, v in model.named_modules():
if hasattr(v, 'bias') and isinstance(v.bias, nn.Parameter):
pg2.append(v.bias) # biases
if isinstance(v, nn.BatchNorm2d):
pg0.append(v.weight) # no decay
elif hasattr(v, 'weight') and isinstance(v.weight, nn.Parameter):
pg1.append(v.weight) # apply decay
if opt.adam:
optimizer = optim.Adam(pg0, lr=hyp['lr0'], betas=(hyp['momentum'], 0.999)) # adjust beta1 to momentum
else:
optimizer = optim.SGD(pg0, lr=hyp['lr0'], momentum=hyp['momentum'], nesterov=True)
optimizer.add_param_group({'params': pg1, 'weight_decay': hyp['weight_decay']}) # add pg1 with weight_decay
optimizer.add_param_group({'params': pg2}) # add pg2 (biases)
logger.info('Optimizer groups: %g .bias, %g conv.weight, %g other' % (len(pg2), len(pg1), len(pg0)))
del pg0, pg1, pg2
# Scheduler https://arxiv.org/pdf/1812.01187.pdf
# https://pytorch.org/docs/stable/_modules/torch/optim/lr_scheduler.html#OneCycleLR
if opt.linear_lr:
lf = lambda x: (1 - x / (epochs - 1)) * (1.0 - hyp['lrf']) + hyp['lrf'] # linear
else:
lf = one_cycle(1, hyp['lrf'], epochs) # cosine 1->hyp['lrf']
scheduler = lr_scheduler.LambdaLR(optimizer, lr_lambda=lf)
# plot_lr_scheduler(optimizer, scheduler, epochs)
# EMA
ema = ModelEMA(model) if RANK in [-1, 0] else None
# Resume
start_epoch, best_fitness = 0, 0.0
if pretrained:
# Optimizer
if ckpt['optimizer'] is not None:
optimizer.load_state_dict(ckpt['optimizer'])
best_fitness = ckpt['best_fitness']
# EMA
if ema and ckpt.get('ema'):
ema.ema.load_state_dict(ckpt['ema'].float().state_dict())
ema.updates = ckpt['updates']
# Results
if ckpt.get('training_results') is not None:
results_file.write_text(ckpt['training_results']) # write results.txt
# Epochs
start_epoch = ckpt['epoch'] + 1
if resume:
assert start_epoch > 0, '%s training to %g epochs is finished, nothing to resume.' % (weights, epochs)
if epochs < start_epoch:
logger.info('%s has been trained for %g epochs. Fine-tuning for %g additional epochs.' %
(weights, ckpt['epoch'], epochs))
epochs += ckpt['epoch'] # finetune additional epochs
del ckpt, state_dict
# Image sizes
gs = max(int(model.stride.max()), 32) # grid size (max stride)
nl = model.model[-1].nl # number of detection layers (used for scaling hyp['obj'])
imgsz, imgsz_val = [check_img_size(x, gs) for x in opt.img_size] # verify imgsz are gs-multiples
# DP mode
if cuda and RANK == -1 and torch.cuda.device_count() > 1:
logging.warning('DP not recommended, instead use torch.distributed.run for best DDP Multi-GPU results.\n'
'See Multi-GPU Tutorial at https://github.com/ultralytics/yolov5/issues/475 to get started.')
model = torch.nn.DataParallel(model)
# SyncBatchNorm
if opt.sync_bn and cuda and RANK != -1:
raise Exception('can not train with --sync-bn, known issue https://github.com/ultralytics/yolov5/issues/3998')
model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model).to(device)
logger.info('Using SyncBatchNorm()')
# Trainloader
dataloader, dataset = create_dataloader(train_path, imgsz, batch_size // WORLD_SIZE, gs, single_cls,
hyp=hyp, augment=True, cache=opt.cache_images, rect=opt.rect, rank=RANK,
workers=workers,
image_weights=opt.image_weights, quad=opt.quad, prefix=colorstr('train: '))
mlc = np.concatenate(dataset.labels, 0)[:, 0].max() # max label class
nb = len(dataloader) # number of batches
assert mlc < nc, 'Label class %g exceeds nc=%g in %s. Possible class labels are 0-%g' % (mlc, nc, data, nc - 1)
# Process 0
if RANK in [-1, 0]:
valloader = create_dataloader(val_path, imgsz_val, batch_size // WORLD_SIZE * 2, gs, single_cls,
hyp=hyp, cache=opt.cache_images and not noval, rect=True, rank=-1,
workers=workers,
pad=0.5, prefix=colorstr('val: '))[0]
if not resume:
labels = np.concatenate(dataset.labels, 0)
c = torch.tensor(labels[:, 0]) # classes
# cf = torch.bincount(c.long(), minlength=nc) + 1. # frequency
# model._initialize_biases(cf.to(device))
if plots:
plot_labels(labels, names, save_dir, loggers)
if loggers['tb']:
loggers['tb'].add_histogram('classes', c, 0) # TensorBoard
# Anchors
if not opt.noautoanchor:
check_anchors(dataset, model=model, thr=hyp['anchor_t'], imgsz=imgsz)
model.half().float() # pre-reduce anchor precision
# DDP mode
if cuda and RANK != -1:
model = DDP(model, device_ids=[LOCAL_RANK], output_device=LOCAL_RANK)
# Model parameters
hyp['box'] *= 3. / nl # scale to layers
hyp['cls'] *= nc / 80. * 3. / nl # scale to classes and layers
hyp['obj'] *= (imgsz / 640) ** 2 * 3. / nl # scale to image size and layers
hyp['label_smoothing'] = opt.label_smoothing
model.nc = nc # attach number of classes to model
model.hyp = hyp # attach hyperparameters to model
model.gr = 1.0 # iou loss ratio (obj_loss = 1.0 or iou)
model.class_weights = labels_to_class_weights(dataset.labels, nc).to(device) * nc # attach class weights
model.names = names
# Start training
t0 = time.time()
nw = max(round(hyp['warmup_epochs'] * nb), 1000) # number of warmup iterations, max(3 epochs, 1k iterations)
# nw = min(nw, (epochs - start_epoch) / 2 * nb) # limit warmup to < 1/2 of training
last_opt_step = -1
maps = np.zeros(nc) # mAP per class
results = (0, 0, 0, 0, 0, 0, 0) # P, R, mAP@.5, mAP@.5-.95, val_loss(box, obj, cls)
scheduler.last_epoch = start_epoch - 1 # do not move
scaler = amp.GradScaler(enabled=cuda)
compute_loss = ComputeLoss(model) # init loss class
logger.info(f'Image sizes {imgsz} train, {imgsz_val} val\n'
f'Using {dataloader.num_workers} dataloader workers\n'
f'Logging results to {save_dir}\n'
f'Starting training for {epochs} epochs...')
for epoch in range(start_epoch, epochs): # epoch ------------------------------------------------------------------
model.train()
# Update image weights (optional)
if opt.image_weights:
# Generate indices
if RANK in [-1, 0]:
cw = model.class_weights.cpu().numpy() * (1 - maps) ** 2 / nc # class weights
iw = labels_to_image_weights(dataset.labels, nc=nc, class_weights=cw) # image weights
dataset.indices = random.choices(range(dataset.n), weights=iw, k=dataset.n) # rand weighted idx
# Broadcast if DDP
if RANK != -1:
indices = (torch.tensor(dataset.indices) if RANK == 0 else torch.zeros(dataset.n)).int()
dist.broadcast(indices, 0)
if RANK != 0:
dataset.indices = indices.cpu().numpy()
# Update mosaic border
# b = int(random.uniform(0.25 * imgsz, 0.75 * imgsz + gs) // gs * gs)
# dataset.mosaic_border = [b - imgsz, -b] # height, width borders
mloss = torch.zeros(4, device=device) # mean losses
if RANK != -1:
dataloader.sampler.set_epoch(epoch)
pbar = enumerate(dataloader)
logger.info(('\n' + '%10s' * 8) % ('Epoch', 'gpu_mem', 'box', 'obj', 'cls', 'total', 'labels', 'img_size'))
if RANK in [-1, 0]:
pbar = tqdm(pbar, total=nb) # progress bar
optimizer.zero_grad()
for i, (imgs, targets, paths, _) in pbar: # batch -------------------------------------------------------------
ni = i + nb * epoch # number integrated batches (since train start)
imgs = imgs.to(device, non_blocking=True).float() / 255.0 # uint8 to float32, 0-255 to 0.0-1.0
# Warmup
if ni <= nw:
xi = [0, nw] # x interp
# model.gr = np.interp(ni, xi, [0.0, 1.0]) # iou loss ratio (obj_loss = 1.0 or iou)
accumulate = max(1, np.interp(ni, xi, [1, nbs / batch_size]).round())
for j, x in enumerate(optimizer.param_groups):
# bias lr falls from 0.1 to lr0, all other lrs rise from 0.0 to lr0
x['lr'] = np.interp(ni, xi, [hyp['warmup_bias_lr'] if j == 2 else 0.0, x['initial_lr'] * lf(epoch)])
if 'momentum' in x:
x['momentum'] = np.interp(ni, xi, [hyp['warmup_momentum'], hyp['momentum']])
# Multi-scale
if opt.multi_scale:
sz = random.randrange(imgsz * 0.5, imgsz * 1.5 + gs) // gs * gs # size
sf = sz / max(imgs.shape[2:]) # scale factor
if sf != 1:
ns = [math.ceil(x * sf / gs) * gs for x in imgs.shape[2:]] # new shape (stretched to gs-multiple)
imgs = F.interpolate(imgs, size=ns, mode='bilinear', align_corners=False)
# Forward
with amp.autocast(enabled=cuda):
pred = model(imgs) # forward
loss, loss_items = compute_loss(pred, targets.to(device)) # loss scaled by batch_size
if RANK != -1:
loss *= WORLD_SIZE # gradient averaged between devices in DDP mode
if opt.quad:
loss *= 4.
# Backward
scaler.scale(loss).backward()
# Optimize
if ni - last_opt_step >= accumulate:
scaler.step(optimizer) # optimizer.step
scaler.update()
optimizer.zero_grad()
if ema:
ema.update(model)
last_opt_step = ni
# Print
if RANK in [-1, 0]:
mloss = (mloss * i + loss_items) / (i + 1) # update mean losses
mem = '%.3gG' % (torch.cuda.memory_reserved() / 1E9 if torch.cuda.is_available() else 0) # (GB)
s = ('%10s' * 2 + '%10.4g' * 6) % (
f'{epoch}/{epochs - 1}', mem, *mloss, targets.shape[0], imgs.shape[-1])
pbar.set_description(s)
# Plot
if plots and ni < 3:
f = save_dir / f'train_batch{ni}.jpg' # filename
Thread(target=plot_images, args=(imgs, targets, paths, f), daemon=True).start()
if loggers['tb'] and ni == 0: # TensorBoard
with warnings.catch_warnings():
warnings.simplefilter('ignore') # suppress jit trace warning
loggers['tb'].add_graph(torch.jit.trace(de_parallel(model), imgs[0:1], strict=False), [])
elif plots and ni == 10 and loggers['wandb']:
wandb_logger.log({'Mosaics': [loggers['wandb'].Image(str(x), caption=x.name) for x in
save_dir.glob('train*.jpg') if x.exists()]})
# end batch ------------------------------------------------------------------------------------------------
# Scheduler
lr = [x['lr'] for x in optimizer.param_groups] # for loggers
scheduler.step()
# DDP process 0 or single-GPU
if RANK in [-1, 0]:
# mAP
ema.update_attr(model, include=['yaml', 'nc', 'hyp', 'gr', 'names', 'stride', 'class_weights'])
final_epoch = epoch + 1 == epochs
if not noval or final_epoch: # Calculate mAP
wandb_logger.current_epoch = epoch + 1
results, maps, _ = val.run(data_dict,
batch_size=batch_size // WORLD_SIZE * 2,
imgsz=imgsz_val,
model=ema.ema,
single_cls=single_cls,
dataloader=valloader,
save_dir=save_dir,
save_json=is_coco and final_epoch,
verbose=nc < 50 and final_epoch,
plots=plots and final_epoch,
wandb_logger=wandb_logger,
compute_loss=compute_loss)
# Write
with open(results_file, 'a') as f:
f.write(s + '%10.4g' * 7 % results + '\n') # append metrics, val_loss
# Log
tags = ['train/box_loss', 'train/obj_loss', 'train/cls_loss', # train loss
'metrics/precision', 'metrics/recall', 'metrics/mAP_0.5', 'metrics/mAP_0.5:0.95',
'val/box_loss', 'val/obj_loss', 'val/cls_loss', # val loss
'x/lr0', 'x/lr1', 'x/lr2'] # params
for x, tag in zip(list(mloss[:-1]) + list(results) + lr, tags):
if loggers['tb']:
loggers['tb'].add_scalar(tag, x, epoch) # TensorBoard
if loggers['wandb']:
wandb_logger.log({tag: x}) # W&B
# Update best mAP
fi = fitness(np.array(results).reshape(1, -1)) # weighted combination of [P, R, mAP@.5, mAP@.5-.95]
if fi > best_fitness:
best_fitness = fi
wandb_logger.end_epoch(best_result=best_fitness == fi)
# Save model
if (not nosave) or (final_epoch and not evolve): # if save
ckpt = {'epoch': epoch,
'best_fitness': best_fitness,
'training_results': results_file.read_text(),
'model': deepcopy(de_parallel(model)).half(),
'ema': deepcopy(ema.ema).half(),
'updates': ema.updates,
'optimizer': optimizer.state_dict(),
'wandb_id': wandb_logger.wandb_run.id if loggers['wandb'] else None}
# Save last, best and delete
torch.save(ckpt, last)
if best_fitness == fi:
torch.save(ckpt, best)
if loggers['wandb']:
if ((epoch + 1) % opt.save_period == 0 and not final_epoch) and opt.save_period != -1:
wandb_logger.log_model(last.parent, opt, epoch, fi, best_model=best_fitness == fi)
del ckpt
# end epoch ----------------------------------------------------------------------------------------------------
# end training -----------------------------------------------------------------------------------------------------
if RANK in [-1, 0]:
logger.info(f'{epoch - start_epoch + 1} epochs completed in {(time.time() - t0) / 3600:.3f} hours.\n')
if plots:
plot_results(save_dir=save_dir) # save as results.png
if loggers['wandb']:
files = ['results.png', 'confusion_matrix.png', *[f'{x}_curve.png' for x in ('F1', 'PR', 'P', 'R')]]
wandb_logger.log({"Results": [loggers['wandb'].Image(str(save_dir / f), caption=f) for f in files
if (save_dir / f).exists()]})
if not evolve:
if is_coco: # COCO dataset
for m in [last, best] if best.exists() else [last]: # speed, mAP tests
results, _, _ = val.run(data_dict,
batch_size=batch_size // WORLD_SIZE * 2,
imgsz=imgsz_val,
model=attempt_load(m, device).half(),
single_cls=single_cls,
dataloader=valloader,
save_dir=save_dir,
save_json=True,
plots=False)
# Strip optimizers
for f in last, best:
if f.exists():
strip_optimizer(f) # strip optimizers
if loggers['wandb']: # Log the stripped model
loggers['wandb'].log_artifact(str(best if best.exists() else last), type='model',
name='run_' + wandb_logger.wandb_run.id + '_model',
aliases=['latest', 'best', 'stripped'])
wandb_logger.finish_run()
torch.cuda.empty_cache()
return results
def parse_opt(known=False):
parser = argparse.ArgumentParser()
parser.add_argument('--weights', type=str, default='yolov5s.pt', help='initial weights path')
parser.add_argument('--cfg', type=str, default='', help='model.yaml path')
parser.add_argument('--data', type=str, default='data/coco128.yaml', help='dataset.yaml path')
parser.add_argument('--hyp', type=str, default='data/hyps/hyp.scratch.yaml', help='hyperparameters path')
parser.add_argument('--epochs', type=int, default=300)
parser.add_argument('--batch-size', type=int, default=16, help='total batch size for all GPUs')
parser.add_argument('--img-size', nargs='+', type=int, default=[640, 640], help='[train, val] image sizes')
parser.add_argument('--rect', action='store_true', help='rectangular training')
parser.add_argument('--resume', nargs='?', const=True, default=False, help='resume most recent training')
parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')
parser.add_argument('--noval', action='store_true', help='only validate final epoch')
parser.add_argument('--noautoanchor', action='store_true', help='disable autoanchor check')
parser.add_argument('--evolve', type=int, nargs='?', const=300, help='evolve hyperparameters for x generations')
parser.add_argument('--bucket', type=str, default='', help='gsutil bucket')
parser.add_argument('--cache-images', action='store_true', help='cache images for faster training')
parser.add_argument('--image-weights', action='store_true', help='use weighted image selection for training')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%')
parser.add_argument('--single-cls', action='store_true', help='train multi-class data as single-class')
parser.add_argument('--adam', action='store_true', help='use torch.optim.Adam() optimizer')
parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode')
parser.add_argument('--workers', type=int, default=8, help='maximum number of dataloader workers')
parser.add_argument('--project', default='runs/train', help='save to project/name')
parser.add_argument('--entity', default=None, help='W&B entity')
parser.add_argument('--name', default='exp', help='save to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
parser.add_argument('--quad', action='store_true', help='quad dataloader')
parser.add_argument('--linear-lr', action='store_true', help='linear LR')
parser.add_argument('--label-smoothing', type=float, default=0.0, help='Label smoothing epsilon')
parser.add_argument('--upload_dataset', action='store_true', help='Upload dataset as W&B artifact table')
parser.add_argument('--bbox_interval', type=int, default=-1, help='Set bounding-box image logging interval for W&B')
parser.add_argument('--save_period', type=int, default=-1, help='Log model after every "save_period" epoch')
parser.add_argument('--artifact_alias', type=str, default="latest", help='version of dataset artifact to be used')
parser.add_argument('--local_rank', type=int, default=-1, help='DDP parameter, do not modify')
opt = parser.parse_known_args()[0] if known else parser.parse_args()
return opt
def main(opt):
set_logging(RANK)
if RANK in [-1, 0]:
print(colorstr('train: ') + ', '.join(f'{k}={v}' for k, v in vars(opt).items()))
check_git_status()
check_requirements(exclude=['thop'])
# Resume
wandb_run = check_wandb_resume(opt)
if opt.resume and not wandb_run: # resume an interrupted run
ckpt = opt.resume if isinstance(opt.resume, str) else get_latest_run() # specified or most recent path
assert os.path.isfile(ckpt), 'ERROR: --resume checkpoint does not exist'
with open(Path(ckpt).parent.parent / 'opt.yaml') as f:
opt = argparse.Namespace(**yaml.safe_load(f)) # replace
opt.cfg, opt.weights, opt.resume = '', ckpt, True # reinstate
logger.info('Resuming training from %s' % ckpt)
else:
# opt.hyp = opt.hyp or ('hyp.finetune.yaml' if opt.weights else 'hyp.scratch.yaml')
opt.data, opt.cfg, opt.hyp = check_file(opt.data), check_file(opt.cfg), check_file(opt.hyp) # check files
assert len(opt.cfg) or len(opt.weights), 'either --cfg or --weights must be specified'
opt.img_size.extend([opt.img_size[-1]] * (2 - len(opt.img_size))) # extend to 2 sizes (train, val)
opt.name = 'evolve' if opt.evolve else opt.name
opt.save_dir = str(increment_path(Path(opt.project) / opt.name, exist_ok=opt.exist_ok or opt.evolve))
# DDP mode
device = select_device(opt.device, batch_size=opt.batch_size)
if LOCAL_RANK != -1:
from datetime import timedelta
assert torch.cuda.device_count() > LOCAL_RANK, 'insufficient CUDA devices for DDP command'
torch.cuda.set_device(LOCAL_RANK)
device = torch.device('cuda', LOCAL_RANK)
dist.init_process_group(backend="nccl" if dist.is_nccl_available() else "gloo", timeout=timedelta(seconds=60))
assert opt.batch_size % WORLD_SIZE == 0, '--batch-size must be multiple of CUDA device count'
assert not opt.image_weights, '--image-weights argument is not compatible with DDP training'
# Train
if not opt.evolve:
train(opt.hyp, opt, device)
if WORLD_SIZE > 1 and RANK == 0:
_ = [print('Destroying process group... ', end=''), dist.destroy_process_group(), print('Done.')]
# Evolve hyperparameters (optional)
else:
# Hyperparameter evolution metadata (mutation scale 0-1, lower_limit, upper_limit)
meta = {'lr0': (1, 1e-5, 1e-1), # initial learning rate (SGD=1E-2, Adam=1E-3)
'lrf': (1, 0.01, 1.0), # final OneCycleLR learning rate (lr0 * lrf)
'momentum': (0.3, 0.6, 0.98), # SGD momentum/Adam beta1
'weight_decay': (1, 0.0, 0.001), # optimizer weight decay
'warmup_epochs': (1, 0.0, 5.0), # warmup epochs (fractions ok)
'warmup_momentum': (1, 0.0, 0.95), # warmup initial momentum
'warmup_bias_lr': (1, 0.0, 0.2), # warmup initial bias lr
'box': (1, 0.02, 0.2), # box loss gain
'cls': (1, 0.2, 4.0), # cls loss gain
'cls_pw': (1, 0.5, 2.0), # cls BCELoss positive_weight
'obj': (1, 0.2, 4.0), # obj loss gain (scale with pixels)
'obj_pw': (1, 0.5, 2.0), # obj BCELoss positive_weight
'iou_t': (0, 0.1, 0.7), # IoU training threshold
'anchor_t': (1, 2.0, 8.0), # anchor-multiple threshold
'anchors': (2, 2.0, 10.0), # anchors per output grid (0 to ignore)
'fl_gamma': (0, 0.0, 2.0), # focal loss gamma (efficientDet default gamma=1.5)
'hsv_h': (1, 0.0, 0.1), # image HSV-Hue augmentation (fraction)
'hsv_s': (1, 0.0, 0.9), # image HSV-Saturation augmentation (fraction)
'hsv_v': (1, 0.0, 0.9), # image HSV-Value augmentation (fraction)
'degrees': (1, 0.0, 45.0), # image rotation (+/- deg)
'translate': (1, 0.0, 0.9), # image translation (+/- fraction)
'scale': (1, 0.0, 0.9), # image scale (+/- gain)
'shear': (1, 0.0, 10.0), # image shear (+/- deg)
'perspective': (0, 0.0, 0.001), # image perspective (+/- fraction), range 0-0.001
'flipud': (1, 0.0, 1.0), # image flip up-down (probability)
'fliplr': (0, 0.0, 1.0), # image flip left-right (probability)
'mosaic': (1, 0.0, 1.0), # image mixup (probability)
'mixup': (1, 0.0, 1.0), # image mixup (probability)
'copy_paste': (1, 0.0, 1.0)} # segment copy-paste (probability)
with open(opt.hyp) as f:
hyp = yaml.safe_load(f) # load hyps dict
if 'anchors' not in hyp: # anchors commented in hyp.yaml
hyp['anchors'] = 3
assert LOCAL_RANK == -1, 'DDP mode not implemented for --evolve'
opt.noval, opt.nosave = True, True # only val/save final epoch
# ei = [isinstance(x, (int, float)) for x in hyp.values()] # evolvable indices
yaml_file = Path(opt.save_dir) / 'hyp_evolved.yaml' # save best result here
if opt.bucket:
os.system('gsutil cp gs://%s/evolve.txt .' % opt.bucket) # download evolve.txt if exists
for _ in range(opt.evolve): # generations to evolve
if Path('evolve.txt').exists(): # if evolve.txt exists: select best hyps and mutate
# Select parent(s)
parent = 'single' # parent selection method: 'single' or 'weighted'
x = np.loadtxt('evolve.txt', ndmin=2)
n = min(5, len(x)) # number of previous results to consider
x = x[np.argsort(-fitness(x))][:n] # top n mutations
w = fitness(x) - fitness(x).min() + 1E-6 # weights (sum > 0)
if parent == 'single' or len(x) == 1:
# x = x[random.randint(0, n - 1)] # random selection
x = x[random.choices(range(n), weights=w)[0]] # weighted selection
elif parent == 'weighted':
x = (x * w.reshape(n, 1)).sum(0) / w.sum() # weighted combination
# Mutate
mp, s = 0.8, 0.2 # mutation probability, sigma
npr = np.random
npr.seed(int(time.time()))
g = np.array([x[0] for x in meta.values()]) # gains 0-1
ng = len(meta)
v = np.ones(ng)
while all(v == 1): # mutate until a change occurs (prevent duplicates)
v = (g * (npr.random(ng) < mp) * npr.randn(ng) * npr.random() * s + 1).clip(0.3, 3.0)
for i, k in enumerate(hyp.keys()): # plt.hist(v.ravel(), 300)
hyp[k] = float(x[i + 7] * v[i]) # mutate
# Constrain to limits
for k, v in meta.items():
hyp[k] = max(hyp[k], v[1]) # lower limit
hyp[k] = min(hyp[k], v[2]) # upper limit
hyp[k] = round(hyp[k], 5) # significant digits
# Train mutation
results = train(hyp.copy(), opt, device)
# Write mutation results
print_mutation(hyp.copy(), results, yaml_file, opt.bucket)
# Plot results
plot_evolution(yaml_file)
print(f'Hyperparameter evolution complete. Best results saved as: {yaml_file}\n'
f'Command to train a new model with these hyperparameters: $ python train.py --hyp {yaml_file}')
def run(**kwargs):
# Usage: import train; train.run(imgsz=320, weights='yolov5m.pt')
opt = parse_opt(True)
for k, v in kwargs.items():
setattr(opt, k, v)
main(opt)
if __name__ == "__main__":
opt = parse_opt()
main(opt)
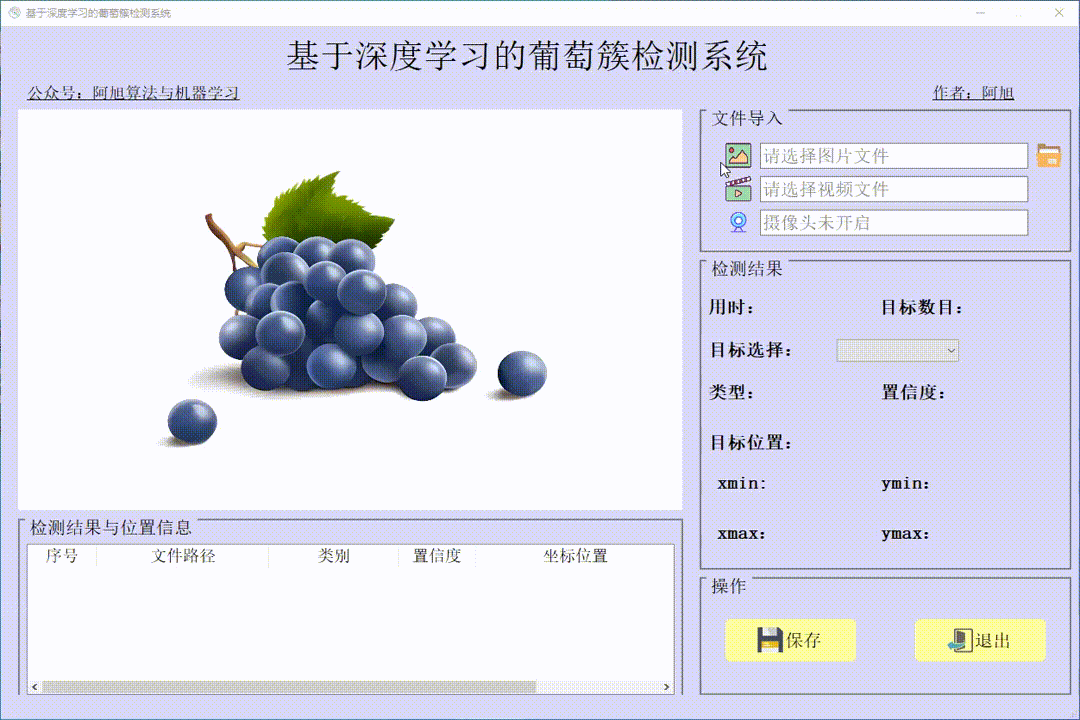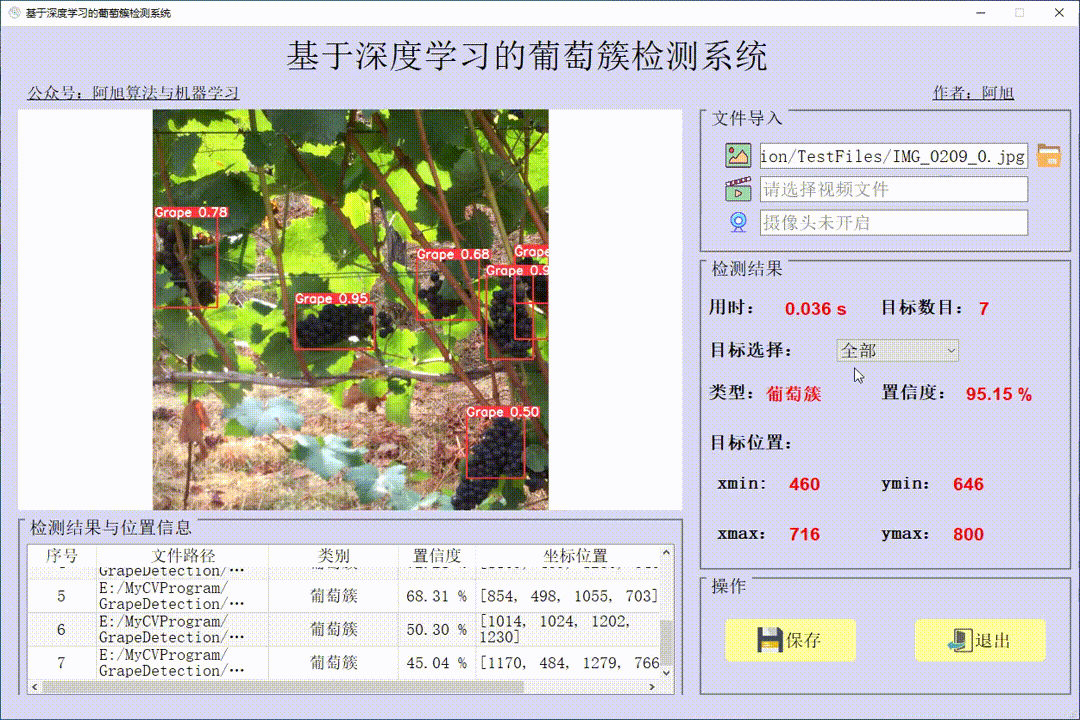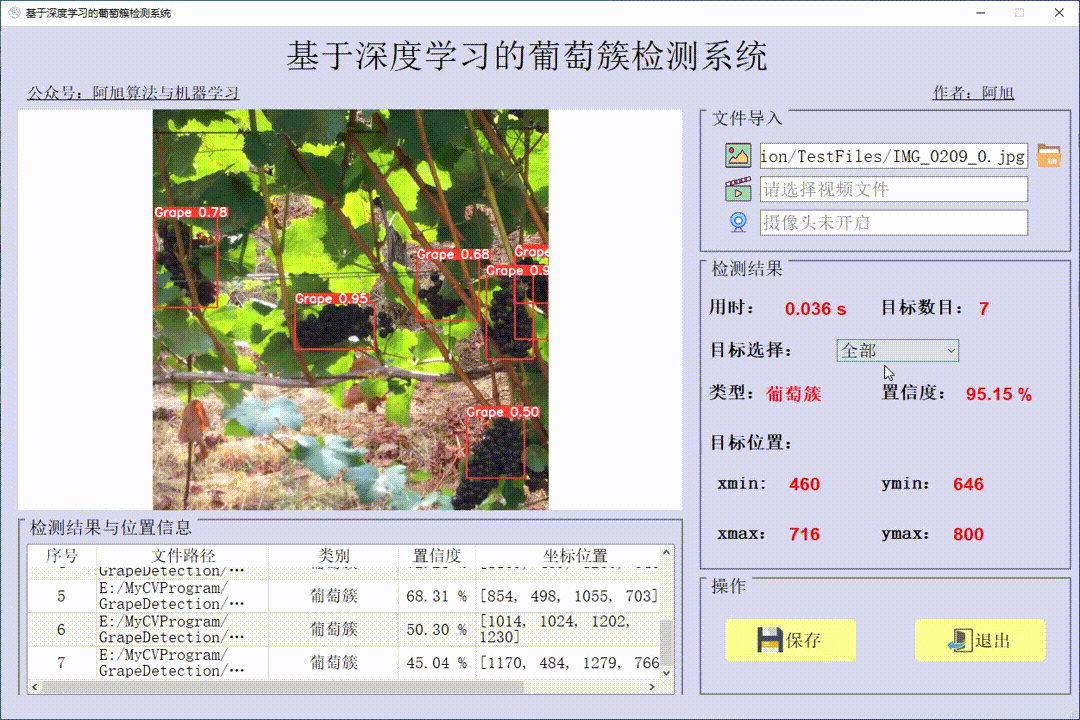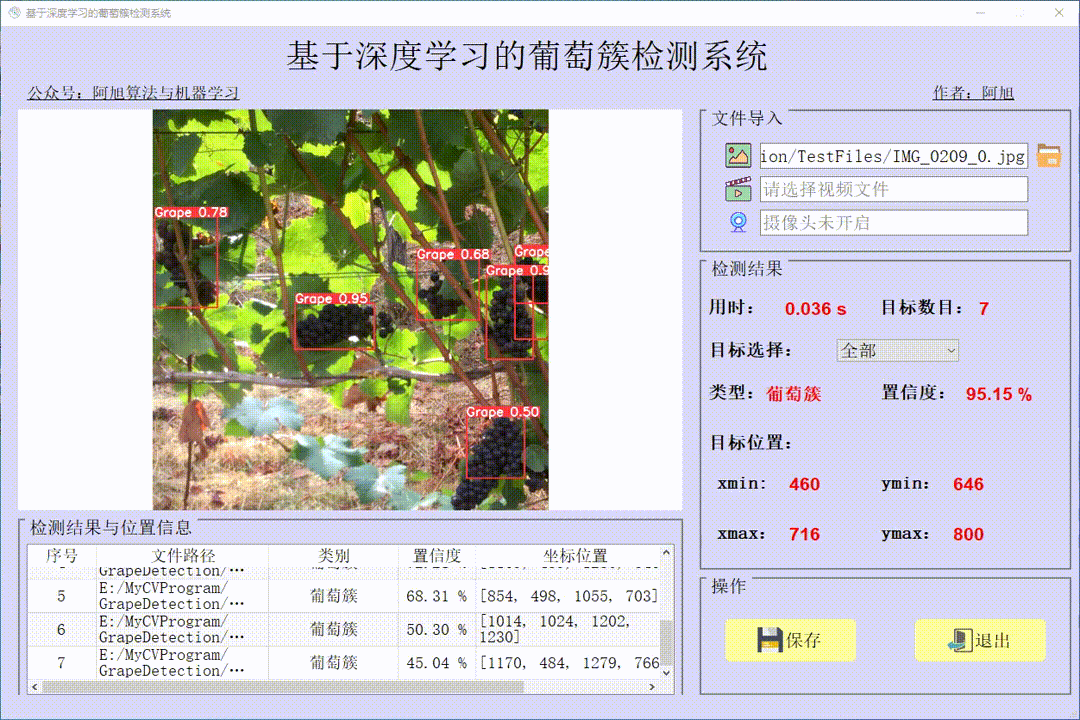
有意思的小项目😁,大家可以自己学习实现一下:
🎄基于YOLOv5的王者荣耀目标检测
🎈YOLOV5-王者荣耀 目标检测 全网最全最火的YOLOv5应用实战训练和讲解
实现效果如下:
YOLO v5目标检测王者荣耀效果视频文章来源:https://www.toymoban.com/news/detail-782925.html
总结🎠
今天介绍了第二类计算机视觉任务-目标检测的下半部分,主要为单阶段目标检测算法YOLO系列。下一节将会介绍第三类计算机视觉任务图像分割,敬请期待🚗文章来源地址https://www.toymoban.com/news/detail-782925.html
到了这里,关于【深度学习】(五)目标检测——下篇的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!