系统:Win10
Java:1.8.0_333
IDEA:2020.3.4
1.项目前言
1.1 项目需求
最近在看外国漫画的时候,发现有些漫画没有汉化的翻译,这哪看得懂。正想把那些日语输入到有道翻译一下,发现日文不会输。正巧之前有接触关于OCR的项目,所以便想用Java做一个小工具,实现图片的文字识别功能,于是我便开始了项目准备工作。
这里我只想简单的文字识别一下,所以为了省事就只考虑本地实现图片文字识别,不去申请云账号啥的了。所以需要对去了解OCR开源项目
1.2 OCR引擎选择
| OCR开源项目 | 简介 | 优点 | 劣势 |
|---|---|---|---|
| Tesseract | Tesseract 是谷歌开发并开源的图像文字识别引擎,使用python开发。 | 1. github上面star非常多,项目非常活跃 2. 识别的语言和文字非常多 3. 后面做背书的公司非常强(google) |
1. 不是专门针对中文场景 2. 相关文档主要是英文,对于阅读和理解起来有一定困难 3. 学习成本比较高 4. 源码较多,并且部分源码是c++,学习起来难度比较大 |
| PaddleOCR | PaddleOCR 是百度开源的中文识别的ocr开源软件 | 1. github上面star非常多,项目非常活跃 2. 模型只针对中文进行训练 3. 后面做背书的公司非常强(baidu) 4. 相关的中文文档非常齐全 5. 识别的精确度比较高 |
1. 目前使用的训练模型是基于百度公司自己的PaddlePaddle框架,对于小公司来说并不主流(对比于ts或者pytorch),所使用深度学习框架为后续其他深度学习无法做很好的铺垫 2. 项目整体比较复杂,学习成本较高 |
| EasyOCR | EasyOCR 是一个用 Python 编写的 OCR 库,用于识别图像中的文字并输出为文本,支持 80 多种语言。 | 1. github上面的star也是比较多,但是最近不是特别活跃 2. 支持的语言也是非常多的,多达80多种 3. 识别的精确度尚可 |
1. 从官方的页面体验来说识别的速度较慢 2. 识别的文字种类多,学习难度较高 3. 相关的官方文档是基于英文的,学习难度较高,对于新手不太友好 |
| chineseocr | … | 1. github上面的star也是比较多 2. 专门针对中文进行学习和训练的模型 3. 相关的文档比较多,上手相对比较容易 |
1. 因为没有大厂和公司的背书, 所以存在一些bug 2. 对于复杂场景下的效果不佳 3. 模型都是现成的,如果要新训练模型难度比较高 |
| chineseocr_lite | … | 1. github上面的star也是比较多 2. 专门针对中文进行学习和训练的模型 3. 相关的文档比较多,上手相对比较容易 4. 比较轻量级,部署也比较方便 |
… |
| TrWebOCR | … | 1. 部署简单 2. 使用简单 3. 有对应的web页面,测试方便 4. 有对应的web接口,方便调用 |
1. 核心模型不开源,无法进行再次学习 2. 无法进行后续训练 3. 必须要联网才能使用 4. 精度识别一般 5. 项目不是很活跃 |
| cnocr | … | 1. 使用简单 2. 文档齐全 3. 代码全部开源,可以进行修改 4. 预定义的模型较多 5. 便于学习和模型重新训练 |
1. 精确度不高 2. 没有对应的web界面和接口 3. 需要配合cnstd进行使用 |
因为我这里需要英文、日文识别,所以综合考虑,我选择了 Tessract,因为我使用的是 Java 语言,所以我选择直接调用 Tess4J 来实现我的需求
1.3 Tess4j介绍
Tess4j 的官网:https://tess4j.sourceforge.net
Tess4j 的 Maven 仓库:https://mvnrepository.com/artifact/net.sourceforge.tess4j/tess4j
Tess4J是对Tesseract OCR API 的Java JNA 封装。使 java 能够通过调用 Tess4J 的 API 来使用 Tesseract OCR。支持的格式包括 TIFF、JPEG、GIF、PNG、BMP、JPEG、PDF。Tess4J是 java 直接可使用的 jar 包,而 Tesseract OCR 是支持 Tess4J 进文件文字识别的基础,Tess4J 可直接使用 Maven 方式引入。
下面的是官网的首页图,从这里我们可以获得3个重要的信息:
1.这项目是Apache2.0的开源项目;2.支持Maven依赖导入;3.支持识别的种类很多,包括常用的PNG、JPEG等
2.项目实现
2.1 项目搭建
首先是引入 Maven 依赖,我这里直接使用最新的 Tess4J 依赖
<!-- Tess4J依赖 -->
<dependency>
<groupId>net.sourceforge.tess4j</groupId>
<artifactId>tess4j</artifactId>
<version>5.4.0</version>
</dependency>
然后就是下载 Tess4J 的所需要的语言库,我下载了 chi_sim.traineddata(中文简体)、eng.traineddata(英文)、jpn.traineddata(日文)三个语言库,存放在 resources 的 data 目录下(如下图所示,osd.traineddata 与页面分割模式有关,这里也一并下载了)
其他语言库可根据自己需求选择下载,tessdata 语言库下载地址:https://github.com/tesseract-ocr/tessdata
注意:如果你下载的语言库只有几十、几百kb,说明你下载异常了,程序启动不了的,解决办法就是连接外网下载
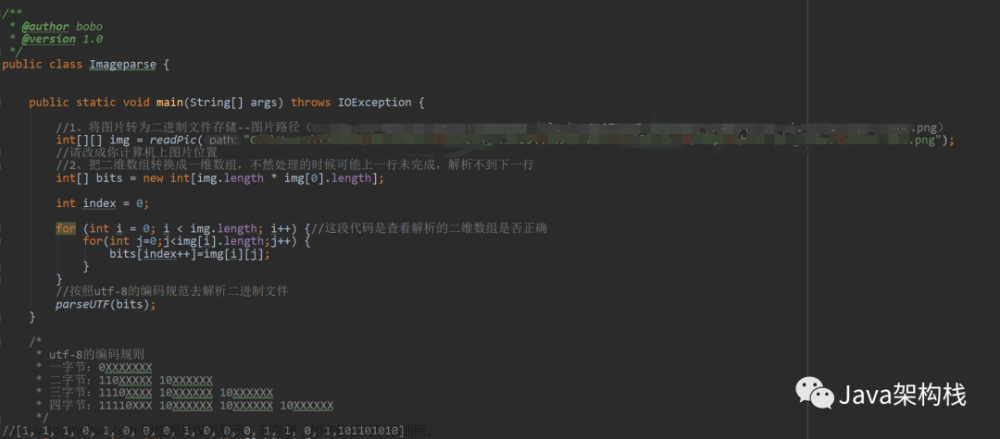
2.2 主要实现代码
// 执行OCR识别
private void execute(BufferedImage targetImage) {
try {
File tempFile = new File(tempImage);
if (tempFile == null) {
tempFile.mkdirs();
}
tempFile.mkdirs();
ImageIO.write(targetImage, "jpg", tempFile);
} catch (IOException e) {
e.printStackTrace();
}
File file = new File(tempImage);
ITesseract instance = new Tesseract();
// 设置语言库位置
instance.setDatapath("src/main/resources/data");
// 设置语言
instance.setLanguage(language);
Thread thread = new Thread() {
public void run() {
String result = null;
try {
result = instance.doOCR(file);
} catch (Exception e) {
e.printStackTrace();
}
resultArea.setText(result);
}
};
ProgressBar.show(this, thread, "图片正在识别中,请稍后...", "执行结束", "取消");
}
3.效果演示
3.1 中文识别
3.1.1 需要识别的图片

3.1.2 识别过程

3.1.3 识别结果
十 年 生 死 两 茫 茫 。 不 思 量 , 自 难 忘 。
干 里 孤 坟 , 无 处 话 凄 凉 。 纵 使 相 逢 应 不 识 , 尘 满 面 , 鬓 如 霜 。
夜 来 幽 梦 忽 还 乡 。 小 轩 窗 , 正 梳 妆 。
相 顾 无 言 , 惟 有 泪 十 行 。 料 得 年 年 肠 断 处 , 明 月 夜 , 短 松 岗 。
错了 “千里孤坟” 的 千 字,还有 “惟有泪千行” 的 千 字,
3.1.4 总结
当图片内的文字比较清晰时,中文的识别度还是挺高的,特别是图像对比度高的话对于文字识别成功影响很大;而且如果字体较为相近,则容易出错。
3.2 英文识别
3.2.1 需要识别的图片

3.2.2 识别过程

3.2.3 识别结果
Success is the sum of small efforts, repeated day in and day out.
Time waits for no one. Treasure every moment you have.
That there's some good in this world, and it's worth fighting for.
全对
3.2.4 总结
英文的识别还是简单,而且基本没有错,因为单词的形体就不会太复杂,这里的测试就一个单词没错,看来用来识别英文是没有问题的
3.3 日文识别
3.3.1 需要识别的图片

3.3.2 识别过程

3.3.3 识别结果
あ な た の 時 間 ( し じ か ん ) は 限 ( か ぎ ) ら れ て い る 。 だ か ら 他 の 誰 か の 人 生
を 生 き る な ん て 無 駄 ( む だ ) な ま ね は よ せ 。
す の も の に ベべ て 美 し さ は あ る が 、 す べ て の 者 に 見 え る わ け で は な い 。
好像也只错了一两处(不认识日文)
3.3.4 总结
从结果来说,日文的识别正确率也挺高的,看来只要中文正确率高,其他文字正确率应该都不低,毕竟复杂度摆在那
3.4 截图功能
这里有一个截图功能,可以直接截取需要识别的图片,然后进行识别。我透,这么简单的两个词都识别不出来,看来还需要好好锻炼 文章来源:https://www.toymoban.com/news/detail-783031.html
文章来源:https://www.toymoban.com/news/detail-783031.html
4.源码地址
Gitee:https://gitee.com/lijinjiang01/JavaOCR文章来源地址https://www.toymoban.com/news/detail-783031.html
到了这里,关于【项目管理】Java OCR实现图片文字识别的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!