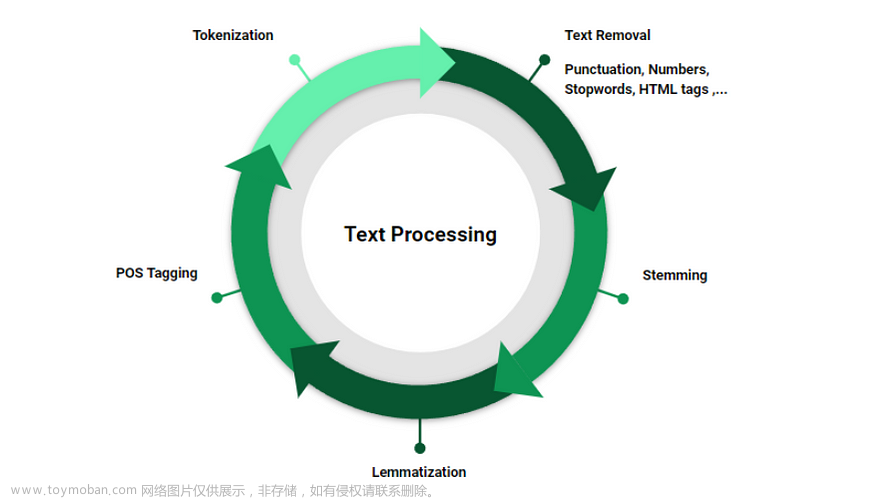
文本预处理及其作用:
文本语料在输送给模型前一般需要一系列的预处理工作,才能符合模型输入的要求,如:将文本转化成模型需要的张量,规范张量的尺寸等,而且科学的文本预处理环节还将有效指导模型超参数的选择,提升模型的评估指标。
文本预处理中包含的主要环节:
文本处理的基本方法
分词
分词就是将连续的字序列按照一定的规范重新组合成词序列的过程。我们知道,在英文的行文中,单词之间是以空格作为自然分界符的,而中文只是字、句和段能通过明显的分界符来简单划界,唯独词没有一个形式上的分界符, 分词过程就是找到这样分界符的过程。
中文(jieba)
精确模式
jieba.cut(content,cut_all=True)#返回对象
jieba.lcut(content,cut_all=True)#返回list全模式分词
jieba.cut(content,cut_all=True)#返回对象
jieba.lcut(content,cut_all=True)#返回list搜索引擎模式
jieba.cut_for_search(content)#返回对象
jieba.lcut_for_search(content)#返回list使用用户自定义词典:
添加自定义词典后,jieba能够准确识别词典中出现的词汇,提升整体的识别准确率。
词典格式:每一行分三部分:词语、词频(可省略)、词性(可省略),用空格隔开,顺序不可颠倒.
词典样式如下,具体词性含义请参照附录:jieba词性对照表,将该词典存为userdict.txt,方便之后加载使用
云计算导论 5 n导入设定的词典
jieba.load_userdict("userdict.txt")英文或中文(hanlp)
#中文分词
content="文本语料在输送给模型前一般需要一系列的预处理工作,才能符合模型输入的要求。"
tokenizer=hanlp.load('CTB6_CONVSEG')
tokenizer(content)
#英文分词
tokenizer = hanlp.pipelines.tok_ctb6_convseg()
content = "The cat is on the mat."
tokenizer(content)
英文(nltk)
import nltk
nltk.download('punkt') # 下载必要的数据
content = "The cat is on the mat."
tokens = nltk.word_tokenize(content)
print(tokens)
文本张量表示方法
将一段文本使用张量进行表示,其中一般将词汇为表示成向量,称作词向量,再由各个词向量按顺序组成矩阵形成文本表示。将文本表示成张量(矩阵)形式,能够使语言文本可以作为计算机处理程序的输入,接下来一系列的解析工作。
one-hot编码
又称独热编码,将每个词表示成具有n个元素的向量,这个词向量中只有一个元素是1,其他元素都是0,不同词汇元素为0的位置不同,其中n的大小是整个语料中不同词汇的总数。
制作映射器
import joblib
from keras.preprocessing.text import Tokenizer
vocab = ["云计算导论", "软件开发与重构", "企业应用开发", "人工智能导论", "用户体验设计"]
# Instantiate the Tokenizer
tokenizer = Tokenizer(num_words=None, char_level=False)
tokenizer.fit_on_texts(vocab)
for vocab_word in vocab:
zero_list = [0] * len(vocab)
token_index = tokenizer.texts_to_sequences([vocab_word])[0][0] - 1
zero_list[token_index] = 1
print(vocab_word, zero_list)
保存映射器
tokenizer_path="./Tokenizer"
joblib.dump(tokenizer,tokenizer_path)使用映射器
t=joblib.load('tokenizer.pkl')
token="xxx"
token_index=t.texts_to_sequences([token])[0][0]-1
zero_list=[0]*len(vocab)
zero_list[token_index]=1Word2vec
一种流行的将词汇表示成向量的无监督训练方法,该过程将构建神经网络模型,将网络参数作为词汇的向量表示,它包含CBOW和skipgram两种训练模式.
CBOW(学习过程)
给定一段用于训练的文本语料,再选定某段长度(窗口)作为研究对象,使用上下文词汇预测目标词汇。
CBOW的详情和实现
skipgram(实现过程)
给定一段用于训练的文本语料, 再选定某段长度(窗口)作为研究对象,使用目标词汇预测上下文词汇。
skipgram的详情和实现
代码实现
import fasttext
# 用无监督方法训练,参数来自'data/fil9'
model=fasttext.train_unsupervised('data/fil9')
# 查看某个词的词向量
model.get_word_vector('computer')
"""模型超参数设定
参数一:数据集。
参数二:训练模式(skpgram和cbow)。
参数三:dim默认为一百,随数据集增大而增大
参数四:epoch循环参数,默认为5。
参数五:lr学习率,【0.01,1】,默认0.05。
参数六:thread线程数,默认为12,一般和cpu核数相同。
"""
model=fasttext.train_unsupervised('data/fil9',"cbow",lr=0.1,epoch=25,dim=100,thread=48)
# 检验评估
model.get_nearest_neighbors('computer')
# 保存模型
model.save_model('data/fil9.bin')
# 加载模型
model =fasttext.load_model('data/fil9.bin')Word Embedding
狭义的word embedding是指在神经网络中加入的embedding层,对整个网络进行训练的同时产生的embedding矩阵(embedding层的参数),这个embedding矩阵就是训练过程中所有输入词汇的向量表示组成的矩阵。
import torch
import json
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter()
embedded=torch.randn(100,50)
meta=list(map(lambda x:x.strip(),fileinput.Fileinput('./data/meta.txt')))
writer.add_embedding(embedded,metadata=meta)
writer.close()文本语料的数据分析
文本数据分析能够有效帮助我们理解数据语料,快速检查出语料可能存在的问题,并指导之后模型训练过程中一些超参数的选择
标签数量分布
各种标签尽量平均,比如二分类要尽量保持一比一。
句子长度分布
通过绘制句子长度分布图, 可以得知我们的语料中大部分句子长度的分布范围,因为模型的输入要求为固定尺寸的张量,合理的长度范围对之后进行句子截断补齐(规范长度)起到关键的指导作用
词频统计与关键词词云
文本特征处理
添加n-gram特征
文本长度规范
数据增强方法
回译数据增强法
回译数据增强目前是文本数据增强方面效果较好的增强方法,一般基于google翻译接口,将文本数据翻译成另外一种语言(一般选择小语种),之后再翻译回原语言, 即可认为得到与与原语料同标签的新语料,新语料加入到原数据集中即可认为是对原数据集数据增强.
操作简便,获得新语料质量高。
回译数据增强存在的问题:
在短文本回译过程中,新语料与原语料可能存在很高的重复率,并不能有效增大样本的特征空间.
高重复率解决办法:文章来源:https://www.toymoban.com/news/detail-783083.html
进行连续的多语言翻译,如:中文﹣>韩文﹣->日语﹣>英文﹣>中文,根据经验,最多只采用3次连续翻译,更多的翻译次数将产生效率低下,语义失真等问题。文章来源地址https://www.toymoban.com/news/detail-783083.html
代码实现(谷歌翻译)
from googletrans import Translator
p_sample1="酒店设施非常不错"
p_sample2="这家价格很便宜"
n_sample1="拖鞋都发霉了,太差了"
n_sample2="电视不好用,没有看到足球"
translator=Translator()
translations=translator.translate([p_sample1,p_sample2,n_sample1,n_sample2],dest='ko')
ko_res=list(map(lambda x:x.text,translations))
print(ko_res)
translations=translator.translate([p_sample1,p_sample2,n_sample1,n_sample2],dest='zh-cn')
cn_res=list(map(lambda x:x.text,translations))
print(cn_res)到了这里,关于【python、nlp】文本预处理的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!