【框架地址】
https://github.com/charlesw/tesseract
【算法介绍】
Tesseract OCR是一个开源的光学字符识别引擎,它可以将图像中的文字转换成可编辑和可搜索的文本格式。Tesseract由惠普实验室于1985年开始开发,并在2005年被Google收购后成为了开源项目。自那时起,它一直在不断的更新和改进,成为了世界上最流行的OCR引擎之一。
核心技术
Tesseract利用了机器学习的方法,特别是在其后期版本中引入了基于长短时记忆(LSTM)网络的深度学习模型,这显著提高了其对文字的识别能力。Tesseract的OCR过程大致可以分为几个阶段:预处理、文字检测、文字分割、文字识别和后处理。
特点
多语言支持
Tesseract支持100多种语言的文字识别,包括多种字母和符号系统。用户可以根据需要下载和使用特定语言的训练数据。
灵活的预处理
虽然Tesseract本身提供了一些基本的图像预处理功能,但它也允许用户使用其他图像处理工具进行高级预处理,从而提高识别准确率。
可定制性
Tesseract允许用户通过训练自己的模型来优化识别结果,这对于专门的应用或不常见的字体类型尤其有用。
开源和免费
作为一个开源项目,Tesseract不仅免费使用,而且还鼓励开发者参与贡献,这使得它得到了广泛的社区支持和持续的改进。
应用场景
Tesseract OCR可以应用于多种文本识别场景,如:
- 文档数字化:将纸质文档转化为电子文档,便于存储、检索和编辑。
- 自动化数据录入:在行业如银行、保险等领域自动化处理表格、发票等文档。
- 车牌识别:在交通管理和自动化停车系统中用于车牌号的识别。
- 辅助阅读:帮助视力障碍人士读取各种印刷材料。
技术优势
成熟稳定
作为一个长期存在且经过广泛测试的项目,Tesseract的稳定性和可靠性得到了公认。
社区活跃
Tesseract有一个非常活跃的开源社区,不断提供bug修复、功能更新和支持。
可扩展性
Tesseract的设计使其可以轻松集成到其他应用程序中,并且可以通过插件或脚本扩展功能。
尽管Tesseract在某些复杂场景下的识别准确率可能不及专业的商业OCR软件,但其开源免费的特性以及不断进步的技术,使其在许多情况下仍然是首选的OCR工具。
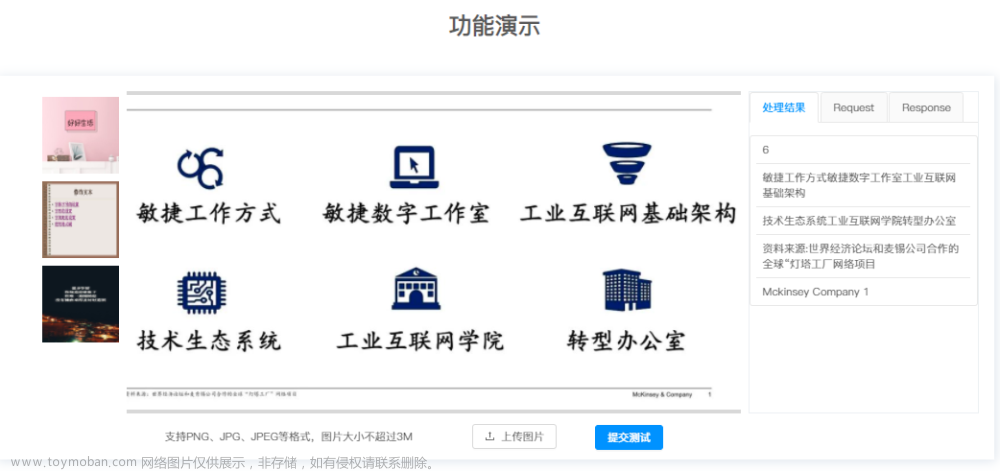
【效果展示】
![[C#]调用tesseact-ocr的traineddata模型进行ocr文字识别,C#,ocr](https://imgs.yssmx.com/Uploads/2024/01/783178-1.jpeg)
【官方实现部分代码】
Basic Text from Image from filepath
from Tesseract.ConsoleDemo/Program.cs
using (var engine = new TesseractEngine(@"./tessdata", "eng", EngineMode.Default))
{
using (var img = Pix.LoadFromFile(testImagePath))
{
using (var page = engine.Process(img))
{
var text = page.GetText();
Console.WriteLine("Mean confidence: {0}", page.GetMeanConfidence());
Console.WriteLine("Text (GetText): \r\n{0}", text);
Console.WriteLine("Text (iterator):");
}
}
}
Basic Text from Image bytes
FileStream fs = new FileStream(filename, FileMode.Open, file_access);
var ms = new MemoryStream();
fs.CopyTo(ms);
fs.Close();
bytes[] fileBytes = ms.ToArray();
ms.Close();
using (var engine = new TesseractEngine(@"./tessdata", "eng", EngineMode.Default))
{
using (var img = Pix.LoadFromMemory(fileBytes))
{
using (var page = engine.Process(img))
{
var txt = page.GetText();
}
}
}
Image to txt searchable pdf using paths
using (IResultRenderer renderer = Tesseract.PdfResultRenderer.CreatePdfRenderer(@"test.pdf", @"./tessdata", false))
{
// PDF Title
using (renderer.BeginDocument("Serachablepdftest"))
{
string configurationFilePath = @"C:\tessdata";
using (TesseractEngine engine = new TesseractEngine(configurationFilePath, "eng", EngineMode.TesseractAndLstm))
{
using (var img = Pix.LoadFromFile(@"C:\file-page1.jpg"))
{
using (var page = engine.Process(img, "Serachablepdftest"))
{
renderer.AddPage(page);
}
}
}
}
}
Image to pdf returning file bytes
var tmpPdfLocation = "./tessdata/pdf";
var sep = Path.PathSeparator;
var tmpFile = tmpPdfLocation + sep + Path.GetTempFileName();
bytes[] fileBytes = null;
using (IResultRenderer renderer = Tesseract.PdfResultRenderer.CreatePdfRenderer(tmpFile, @"./tessdata", false))
{
// PDF Title
using (renderer.BeginDocument("Serachablepdftest"))
{
// string configurationFilePath = @"C:\tessdata";
using (TesseractEngine engine2 = new TesseractEngine(configurationFilePath, "eng", EngineMode.TesseractAndLstm))
{
using (var img = Pix.LoadFromFile(@"C:\file-page1.jpg"))
{
using (var page = engine.Process(img, "Searchablepdftest"))
{
renderer.AddPage(page);
}
}
}
}
}
// on dispose file should be created
var stream = new FileStream(tmpFile, FileMode.Open, FileAccess.Read);
MemoryStream ms = new MemoryStream();
stream.CopyTo(ms);
fileBytes = ms.ToArray();
stream.Dispose();
ms.Close();
// delete tmp file
File.Delete(tmpFile);
【视频演示】
https://www.bilibili.com/video/BV1uT4y1n7SK/
【源码下载】
https://download.csdn.net/download/FL1623863129/88728947
【测试环境】
vs2019文章来源:https://www.toymoban.com/news/detail-783178.html
netframework4.7.2文章来源地址https://www.toymoban.com/news/detail-783178.html
到了这里,关于[C#]调用tesseact-ocr的traineddata模型进行ocr文字识别的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!