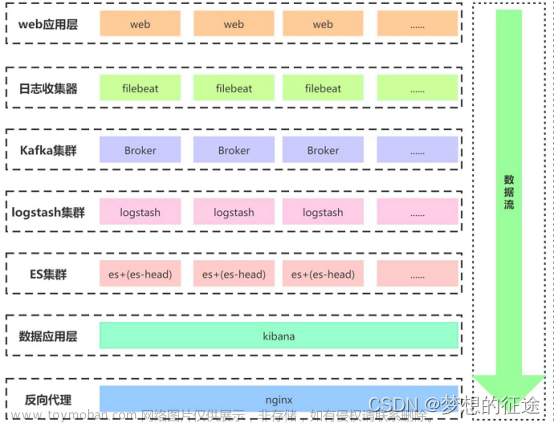
Kafka ui
序
kafka 本身没有自带相关的 ui 界面,但是很多时候没有页面意味着只有使用命令行进行相关操作如创建 topic、更改 topic 信息、重置 offset 等等。但实际使用中这种效果很差劲,我们一般还是会借助其他软件,实现对 kafka 的页面管控。

结合这张图与实际体验,推荐大家使用 ui for apache kafka 进行 kafka 的 ui 界面化管理。
kafka-ui 搭建
其实 kafka-ui 是没有安装过程的,在 github 上已经打包成了 jar 包,当前最新版本为 0.4,下载地址如下:
https://github.com/provectus/kafka-ui/releases
我们下载最新的 jar 后,放到服务器上如图:

创建一个 application.yml 文件:
kafka:
clusters:
- name: kafka3_cluster
bootstrapServers: 192.168.111.128:9092,192.168.111.129:9092,192.168.111.130:9092
metrics:
port: 9094
type: JMX
- name: OTHER_KAFKA_CLUSTER_NAME
bootstrapServers: 10.10.10.10:9092
metrics:
port: 9094
type: JMX
spring:
jmx:
enabled: true
security:
user:
name: maggot
password: maggot
auth:
type: LOGIN_FORM #LOGIN_FORM # DISABLED
server:
port: 10300
logging:
level:
root: INFO
com.provectus: INFO
reactor.netty.http.server.AccessLog: INFO
management:
endpoint:
info:
enabled: true
health:
enabled: true
endpoints:
web:
exposure:
include: "info,health"
clusters
在 kafka 中配置相关的 kafka 集群,每一个 clusters 为一个集群,需要配置:
- name
设置一个集群名
- bootstrapServers
brokers 连接,针对 kraft 架构,就很方便,不用再配置 zookeeper 相关配置。
- metrics
配置该集群的 JMX 相关配置,如果没有可省略。(在启动 kafka 时,启动命令行前面添加 JMX_PORT=9094 )
登陆配置
- auth.type
使用 LOGIN_FORM 开启;或者 DISABLED 关闭认证。如果开启了,需要 spring.security.user 中配置用户名与密码。
- spring.security.user
配置的登陆账号密码。
kafka-ui http 端口
- server.port
kafka-ui http 端口。
todo 进行 SASL_SSL 认证配置
kafka-ui 使用
多集群切换
点击左侧进行多集群切换,绿色为集群健康,黄色为警告,红色为已经挂掉。

集群 Broker 统计信息
所有 broker 总数、controllers 总数、版本号。Partitions 在线数量,URP 数量,在副本数的数量和 OSR 的数量。
下面为每个 broker 的详细数据信息。

Topic 信息
在 Topics 中,可以看到所有的 topic,也可以进行搜索。

在查询到自己想看的 topic 后可以点击 topic name 进行详细的 topic 查看:

可以通过切换 overview、messages、consumers、settings 进行切换。在左边有三个点的按钮都可以操作,
- 其中右上角的对当前 topic 操作,包含:编辑 topic 信息、 清空 topic 数据、重建 topic、删除 topic。

- 针对每个 broker 也可以清空数据:

创建 topic

在 add custom parameter 中添加额外信息。
Consumers

左边也可以进行清空状态操作文章来源:https://www.toymoban.com/news/detail-783322.html
 文章来源地址https://www.toymoban.com/news/detail-783322.html
文章来源地址https://www.toymoban.com/news/detail-783322.html
到了这里,关于Kafka ui 搭建以及使用的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!