Hadoop HA 部署
所需的压缩包百度网盘自取:
实操使需的压缩包: 链接
提取码:q9r6
环境准备:
三台虚拟机,版本最好为centos7.4
| 编号 | 主机名 | 类型 | 用户 | 密码 | ip |
|---|---|---|---|---|---|
| 1 | master1 | 主节点 | root | passwd | 192.168.160.110 |
| 2 | slave1 | 从节点 | root | passwd | 1292168.160.111 |
| 3 | slave2 | 从节点 | root | passwd | 129.168.160.112 |
一、解压 JDK 安装包到“/usr/local/src”路径,并配置环境变量;截取环境变量配置文件截图
1、关闭防火墙 和 关闭防火墙自启
[root@localhost ~]# systemctl stop firewalld
[root@localhost ~]# systemctl disable firewalld
三台机器全部都要关闭防火墙 和 自启
2、卸载自带的jdk
[root@localhost ~]# rpm -qa | grep jdk
java-1.8.0-openjdk-1.8.0.131-11.b12.el7.x86_64
java-1.7.0-openjdk-1.7.0.141-2.6.10.5.el7.x86_64
copy-jdk-configs-2.2-3.el7.noarch
java-1.7.0-openjdk-headless-1.7.0.141-2.6.10.5.el7.x86_64
java-1.8.0-openjdk-headless-1.8.0.131-11.b12.el7.x86_64
[root@localhost ~]# rpm -e --nodeps java-1.7.0-openjdk
[root@localhost ~]# rpm -e --nodeps java-1.7.0-openjdk-headless
[root@localhost ~]# rpm -e --nodeps java-1.8.0-openjdk
[root@localhost ~]# rpm -e --nodeps java-1.8.0-openjdk-headless
3、进入 /h3cu/ 目录
[root@localhost ~]# mkdir /h3cu
[root@localhost ~]# cd /h3cu/
[root@localhost h3cu]# ll
total 412752
-rw-r--r--. 1 root root 210606807 Aug 2 19:15 hadoop-2.7.1.tar.gz
-rw-r--r--. 1 root root 189784266 Aug 2 19:16 jdk-8u152-linux-x64.tar.gz
-rw-r--r--. 1 root root 22261552 Aug 2 19:16 zookeeper-3.4.8.tar.gz
4、解压 jdk 到 /usr/local/src
[root@localhost h3cu]# tar -zxvf jdk-8u152-linux-x64.tar.gz -C /usr/local/src/
5、配置环境变量
[root@localhost ~]# cd /usr/local/src/jdk1.8.0_152/
[root@localhost jdk1.8.0_152]# pwd
/usr/local/src/jdk1.8.0_152
[root@localhost jdk1.8.0_152]# vim /etc/profile
//添加至最后一行
export JAVA_HOME=/usr/local/src/jdk1.8.0_152
export PATH=$PATH:$JAVA_HOME/bin
//查看一下jdk版本是否一致
[root@master1 ~]# java -version
java version "1.8.0_152"
Java(TM) SE Runtime Environment (build 1.8.0_152-b16)
Java HotSpot(TM) 64-Bit Server VM (build 25.152-b16, mixed mode)
二、在指定目录下安装ssh服务,查看ssh进程并截图
1、查看是否已安装ssh服务
[root@localhost ~]# rpm -qa | grep ssh
openssh-clients-7.4p1-11.el7.x86_64
openssh-server-7.4p1-11.el7.x86_64
libssh2-1.4.3-10.el7_2.1.x86_64
openssh-7.4p1-11.el7.x86_64
2、使用yum进行安装ssh服务
[root@localhost ~]# yum -y install openssh openssh-server
3、查看ssh进程
[root@localhost ~]# ps -ef | grep ssh
root 1594 1421 0 18:01 ? 00:00:00 /usr/bin/ssh-agent /bin/sh -c exec -l /bin/bash -c "env GNOME_SHELL_SESSION_MODE=classic gnome-session --session gnome-classic"
root 2120 1 0 18:03 ? 00:00:00 sshd: root@pts/1
root 3602 1 0 20:01 ? 00:00:00 /usr/sbin/sshd -D
root 3612 2124 0 20:03 pts/1 00:00:00 grep --color=auto ssh
三、创建 ssh 密钥,实现主节点与从节点的无密码登录;截取主节点登录其中一个从节点的结果
1、在指定目录下生成密钥对
[root@localhost ~]# ssh-keygen -t rsa
//依次回车,生成密钥对
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
Created directory '/root/.ssh'.
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:IGgI9+bj3shXnXzyKcWF+/FLlCZGaEXtUZ+MY1pU2k8 root@localhost.localdomain
The key's randomart image is:
+---[RSA 2048]----+
|. . .+o.o|
|.o o + =oo|
|. o + . o O.+E|
| . o . . . * ooo|
| o So + = +.|
| . . . = * = |
| . . = o + |
| o o. . o o .|
| +.. . ..|
+----[SHA256]-----+
[root@localhost ~]#
2、分发公匙文件
//每个主机都需要分发公钥,并且需要输入各个主机的密码
[root@localhost ~]# ssh-copy-id 192.168.160.110
[root@localhost ~]# ssh-copy-id 192.168.160.111
[root@localhost ~]# ssh-copy-id 192.168.160.112
3、主节点免密登录从节点
[root@localhost ~]# ssh 192.168.160.111
Last login: Tue Aug 2 18:05:07 2022 from 192.168.160.1
[root@localhost ~]# exit
logout
Connection to 192.168.160.111 closed.
[root@localhost ~]# ssh 192.168.160.112
Last login: Tue Aug 2 18:05:31 2022 from 192.168.160.1
[root@localhost ~]# exit
logout
Connection to 192.168.160.112 closed.
[root@localhost ~]#
四、 根据要求修改每台主机 host 文件,截取“/etc/hosts”文件截图
//三台机器的hosts文件全部都要修改
[root@localhost ~]# vim /etc/hosts
192.168.160.110 master1
192.168.160.111 slave1
192.168.160.112 slave2
[root@localhost ~]# vim /etc/hosts
192.168.160.110 master1
192.168.160.111 slave1
192.168.160.112 slave2
[root@localhost ~]# vim /etc/hosts
192.168.160.110 master1
192.168.160.111 slave1
192.168.160.112 slave2
五、修 改 每 台 主 机 hostname 文 件 配 置 IP 与 主 机 名 映 射 关 系 ; 截 取 “/etc/hostname”文件截图
[root@localhost ~]# hostnamectl set-hostname master1
[root@localhost ~]# bash
[root@master1 ~]#
[root@localhost ~]# hostnamectl set-hostname slave1
[root@localhost ~]# bash
[root@slave1 ~]#
[root@localhost ~]# hostnamectl set-hostname slave2
[root@localhost ~]# bash
[root@slave2 ~]#
六、在主节点和从节点修改 Hadoop 环境变量,并截取修改内容
1、修改Hadoop环境变量
[root@master1 ~]# vim /etc/profile
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
七、需安装 Zookeeper 组件具体要求同 Zookeeper 任务要求,并与 Hadoop HA 环境适配
1、解压zookeeper
[root@master1 ~]# tar -zxvf /h3cu/zookeeper-3.4.8.tar.gz -C /usr/local/src/
2、重命名
[root@master1 ~]# mv /usr/local/src/zookeeper-3.4.8/ /usr/local/src/zookeeper
3、进入zookeeper/conf目录下
[root@master1 ~]# cd /usr/local/src/zookeeper/conf/
4、重命名zoo_sample.cfg为zoo.cfg
[root@master1 conf]# mv zoo_sample.cfg zoo.cfg
5、修改zoo.cfg配置文件
[root@master1 conf]# vim zoo.cfg
//添加或者修改为如下内容
tickTime=2000
syncLimit=5
dataDir=/usr/local/src/zookeeper/data
dataLogDir=/usr/local/src/zookeeper/logs
clientPort=2181
server.1=master1:2888:3888
server.2=slave1:2888:3888
server.3=slave2:2888:3888
6、创建ZooKeeper 的数据存储与日志存储目录
[root@master1 conf]# mkdir /usr/local/src/zookeeper/data
[root@master1 conf]# mkdir /usr/local/src/zookeeper/logs
7、创建myid文件并写入内容:1
[root@master1 conf]# vim /usr/local/src/zookeeper/data/myid
1
8、添加zookeeper环境变量
[root@master1 ~]# vim /etc/profile
export ZK_HOME=/usr/local/src/zookeeper
export PATH=$PATH:ZK_HOME/bin
9、集群分发
[root@master1 ~]# scp -r /etc/profile slave1:/etc/profile
The authenticity of host 'slave1 (192.168.160.111)' can't be established.
ECDSA key fingerprint is SHA256:6AC09we9uFsxT0lTf5v5yRysEgjv3xYMoC49HIpFdm4.
ECDSA key fingerprint is MD5:a6:de:c7:6e:61:48:ae:79:85:53:42:66:36:04:c3:69.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'slave1' (ECDSA) to the list of known hosts.
profile 100% 2033 1.1MB/s 00:00
[root@master1 ~]# scp -r /etc/profile slave2:/etc/profile
The authenticity of host 'slave2 (192.168.160.112)' can't be established.
ECDSA key fingerprint is SHA256:6AC09we9uFsxT0lTf5v5yRysEgjv3xYMoC49HIpFdm4.
ECDSA key fingerprint is MD5:a6:de:c7:6e:61:48:ae:79:85:53:42:66:36:04:c3:69.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'slave2' (ECDSA) to the list of known hosts.
profile 100% 2033 1.0MB/s 00:00
[root@master1 ~]# scp -r /usr/local/src/zookeeper/ slave1:/usr/local/src/
[root@master1 ~]# scp -r /usr/local/src/zookeeper/ slave2:/usr/local/src/
10、修改slave1-1 和 slave1-2的myid文件分别为2 ,3
[root@slave1 ~]# vim /usr/local/src/zookeeper/data/myid
2
[root@slave2 ~]# vim /usr/local/src/zookeeper/data/myid
3
八、修改 namenode、datanode、journalnode 等存放数据的公共目录为 /usr/local/hadoop/tmp
1、解压安装Hadoop
[root@master1 ~]# tar -zxvf /h3cu/hadoop-2.7.1.tar.gz -C /usr/local/
2、重命名Hadoop
[root@master1 ~]# mv /usr/local/hadoop-2.7.1/ /usr/local/hadoop
3、进入hadoop配置文件目录
[root@master1 ~]# cd /usr/local/hadoop/etc/hadoop/
4、配置hadoop-env.sh文件(修改)
[root@master1 hadoop]# vim hadoop-env.sh
export JAVA_HOME=/usr/local/src/jdk1.8.0_152/
5、配置core-site.xml文件
[root@master1 hadoop]# vim core-site.xml
<configuration>
<!-- 指定 hdfs 的 nameservice 为 mycluster -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
</property>
<!-- 指定 zookeeper 地址 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>master1:2181,slave1:2181,slave2:2181</value>
</property>
<!-- hadoop 链接 zookeeper 的超时时长设置 -->
<property>
<name>ha.zookeeper.session-timeout.ms</name>
<value>30000</value>
<description>ms</description>
</property>
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
</configuration>
6、配置hdfs-site.xml文件
[root@master1 hadoop]# vim hdfs-site.xml
<configuration>
<!-- journalnode 集群之间通信的超时时间 -->
<property>
<name>dfs.qjournal.start-segment.timeout.ms</name>
<value>60000</value>
</property>
<!--指定 hdfs 的 nameservice 为 mycluster,需要和 core-site.xml 中的保持一致
dfs.ha.namenodes.[nameservice id]为在 nameservice 中的每一个 NameNode 设置唯一标示
符。配置一个逗号分隔的NameNode ID列表。这将是被DataNode识别为所有的NameNode。
如果使用"mycluster"作为 nameservice ID,并且使用"master"和"slave1"作为 NameNodes 标
示符 -->
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<!-- mycluster 下面有两个 NameNode,分别是 master,slave1 -->
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>master1,slave1</value>
</property>
<!-- master 的 RPC 通信地址 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.master1</name>
<value>master1:9000</value>
</property>
<!-- slave1 的 RPC 通信地址 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.slave1</name>
<value>slave1:9000</value>
</property>
<!-- master 的 http 通信地址 -->
<property>
<name>dfs.namenode.http-address.mycluster.master1</name>
<value>master1:50070</value>
</property>
<!-- slave1 的 http 通信地址 -->
<property>
<name>dfs.namenode.http-address.mycluster.slave1</name>
<value>slave1:50070</value>
</property>
<!-- 指定 NameNode 的 edits 元数据的共享存储位置。也就是 JournalNode 列表
该 url 的配置格式:qjournal://host1:port1;host2:port2;host3:port3/journalId
journalId 推荐使用 nameservice,默认端口号是:8485 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://master1:8485;slave1:8485;slave2:8485/mycluster</value>
</property>
<!-- 配置失败自动切换实现方式 -->
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制方法,多个机制用换行分割,即每个机制暂用一行 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<property>
<name>dfs.support.append</name>
<value>true</value>
</property>
<!-- 使用 sshfence 隔离机制时需要 ssh 免登陆 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!-- 指定副本数 -->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/usr/local/hadoop/tmp/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/usr/local/hadoop/tmp/data</value>
</property>
<!-- 指定 JournalNode 在本地磁盘存放数据的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/usr/local/hadoop/tmp/journal</value>
</property>
<!-- 开启 NameNode 失败自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 启用 webhdfs -->
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<!-- 配置 sshfence 隔离机制超时时间 -->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
<property>
<name>ha.failover-controller.cli-check.rpc-timeout.ms</name>
<value>60000</value>
</property>
</configuration>
7、配置mapred-site.xml文件
A、拷贝mapred-site.xml.template重命名为mapred-site.xml,并编辑文件
[root@master1 hadoop]# cp mapred-site.xml.template mapred-site.xml
[root@master1 hadoop]# vim mapred-site.xml
<configuration>
<!-- 指定 mr 框架为 yarn 方式 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 指定 mapreduce jobhistory 地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>master1:10020</value>
</property>
<!-- 任务历史服务器的 web 地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master1:19888</value>
</property>
</configuration>
8、配置yarn-site.xml文件
[root@master1 hadoop]# vim yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<!-- 开启 RM 高可用 -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 指定 RM 的 cluster id -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yrc</value>
</property>
<!-- 指定 RM 的名字 -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 分别指定 RM 的地址 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>master1</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>slave1</value>
</property>
<!-- 指定 zk 集群地址 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>master1:2181,slave1:2181,slave1:2181</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>86400</value>
</property>
<!-- 启用自动恢复 -->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!-- 制定 resourcemanager 的状态信息存储在 zookeeper 集群上 -->
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
</configuration>
9、创建tmp , logs, tmp/下创建name,data,journal目录
[root@master1 hadoop]# mkdir /usr/local/hadoop/tmp
[root@master1 hadoop]# mkdir /usr/local/hadoop/logs
[root@master1 hadoop]# mkdir /usr/local/hadoop/tmp/journal
[root@master1 hadoop]# mkdir /usr/local/hadoop/tmp/data
[root@master1 hadoop]# mkdir /usr/local/hadoop/tmp/name
10、配置hadoop/etc/hadoop/slaves文件
[root@master1 hadoop]# vim slaves
master1
slave1
slave2
11、分发jdk和hadoop文件
[root@master1 hadoop]# scp -r /usr/local/src/jdk1.8.0_152/ slave1:/usr/local/src/
[root@master1 hadoop]# scp -r /usr/local/src/jdk1.8.0_152/ slave2:/usr/local/src/
[root@master1 hadoop]# scp -r /usr/local/hadoop/ slave1:/usr/local/
[root@master1 hadoop]# scp -r /usr/local/hadoop/ slave2:/usr/local/
12、确保3台机器的环境变量已经生效
[root@master1 hadoop]# source /etc/profile
[root@slave1 ~]# source /etc/profile
[root@slave2 ~]# source /etc/profile
九、根据要求修改 Hadoop 相关文件,并初始化 Hadoop,截图初始化结果
1、启动zookeeper集群并查看状态
进入zookeeper安装目录下
[root@master1 hadoop]# cd /usr/local/src/zookeeper/
[root@master1 zookeeper]# bin/zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /usr/local/src/zookeeper/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[root@master1 zookeeper]# bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /usr/local/src/zookeeper/bin/../conf/zoo.cfg
Mode: follower
[root@slave1 ~]# cd /usr/local/src/zookeeper/
[root@slave1 zookeeper]# bin/zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /usr/local/src/zookeeper/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[root@slave1 zookeeper]# bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /usr/local/src/zookeeper/bin/../conf/zoo.cfg
Mode: leader
[root@slave2 ~]# cd /usr/local/src/zookeeper/
[root@slave2 zookeeper]# bin/zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /usr/local/src/zookeeper/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[root@slave2 zookeeper]# bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /usr/local/src/zookeeper/bin/../conf/zoo.cfg
Mode: follower
2、初始化HA在zookeeper中的状态
[root@master1 zookeeper]# cd /usr/local/hadoop/
[root@master1 hadoop]# bin/hdfs zkfc -formatZK
3、启动全部机器的 journalnode 服务
进入/usr/local/hadoop安装目录下
[root@master1 hadoop]# sbin/hadoop-daemon.sh start journalnode
starting journalnode, logging to /usr/local/hadoop/logs/hadoop-root-journalnode-master1.out
[root@slave1 zookeeper]# cd /usr/local/hadoop/
[root@slave1 hadoop]# sbin/hadoop-daemon.sh start journalnode
starting journalnode, logging to /usr/local/hadoop/logs/hadoop-root-journalnode-slave1.out
[root@slave2 zookeeper]# cd /usr/local/hadoop/
[root@slave2 hadoop]# sbin/hadoop-daemon.sh start journalnode
starting journalnode, logging to /usr/local/hadoop/logs/hadoop-root-journalnode-slave2.out
4、初始化namenode
进入hadoop/bin目录下
[root@master1 bin]# hdfs namenode -format
//最终状态为0才是正确的
22/08/03 19:26:29 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
22/08/03 19:26:29 INFO util.ExitUtil: Exiting with status 0
22/08/03 19:26:29 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at master1/192.168.160.110
************************************************************/
观察是否有报错信息,status是否为0,0即为初始化成功,1则报错,检查配置文件是否有误
十、启动 Hadoop,使用相关命令查看所有节点 Hadoop 进程并截图
启动hadoop所有进程
进入hadoop安装目录下
//可能会出现卡住,输入回车或者yes或者重新启动
[root@master1 bin]# cd ..
[root@master1 hadoop]# sbin/start-all.sh
十一、本题要求配置完成后在 Hadoop 平台上运行查看进程命令,要求运行结果的截屏保存
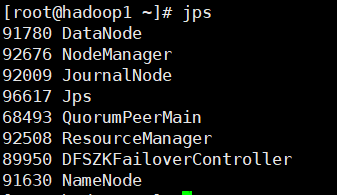
[root@master1 hadoop]# jps
7424 ResourceManager
5973 QuorumPeerMain
8517 Jps
8407 NodeManager
7928 DataNode
6892 JournalNode
8236 DFSZKFailoverController
7823 NameNode
[root@slave1 hadoop]# jps
7073 Jps
6324 JournalNode
5861 QuorumPeerMain
6695 DFSZKFailoverController
6575 DataNode
6767 NodeManager
[root@slave2 hadoop]# jps
6884 NodeManager
6118 QuorumPeerMain
6759 DataNode
7095 Jps
6606 JournalNode
十二、格式化主从节点
1、复制 namenode 元数据到其它节点
[root@slave2 hadoop]# scp -r /usr/local/hadoop/tmp/* slave1:/usr/local/hadoop/tmp/
The authenticity of host 'slave1 (192.168.160.111)' can't be established.
ECDSA key fingerprint is SHA256:6AC09we9uFsxT0lTf5v5yRysEgjv3xYMoC49HIpFdm4.
ECDSA key fingerprint is MD5:a6:de:c7:6e:61:48:ae:79:85:53:42:66:36:04:c3:69.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'slave1,192.168.160.111' (ECDSA) to the list of known hosts.
root@slave1's password:
in_use.lock 100% 11 10.6KB/s 00:00
VERSION 100% 229 321.4KB/s 00:00
VERSION 100% 134 231.6KB/s 00:00
scanner.cursor 100% 166 136.4KB/s 00:00
VERSION 100% 154 213.4KB/s 00:00
last-promised-epoch 100% 2 4.7KB/s 00:00
last-writer-epoch 100% 2 4.7KB/s 00:00
edits_inprogress_0000000000000000001 100% 1024KB 79.3MB/s 00:00
committed-txid 100% 0 0.0KB/s 00:00
in_use.lock 100% 11 10.1KB/s 00:00
[root@slave2 hadoop]# scp -r /usr/local/hadoop/tmp/* slave2:/usr/local/hadoop/tmp/
The authenticity of host 'slave2 (192.168.160.112)' can't be established.
ECDSA key fingerprint is SHA256:6AC09we9uFsxT0lTf5v5yRysEgjv3xYMoC49HIpFdm4.
ECDSA key fingerprint is MD5:a6:de:c7:6e:61:48:ae:79:85:53:42:66:36:04:c3:69.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'slave2,192.168.160.112' (ECDSA) to the list of known hosts.
root@slave2's password:
in_use.lock 100% 11 11.6KB/s 00:00
VERSION 100% 229 530.7KB/s 00:00
VERSION 100% 134 889.6KB/s 00:00
scanner.cursor 100% 166 1.3MB/s 00:00
VERSION 100% 154 1.9MB/s 00:00
last-promised-epoch 100% 2 29.7KB/s 00:00
last-writer-epoch 100% 2 41.8KB/s 00:00
edits_inprogress_0000000000000000001 100% 1024KB 102.5MB/s 00:00
committed-txid 100% 0 0.0KB/s 00:00
in_use.lock 100% 11 73.9KB/s 00:00
注:由于之前namenode,datanode,journalnode的数据全部存放在hadoop/tmp目录下,所以直接复制 tmp 目录至从节点
十三、启动两个 resourcemanager 和 namenode
1、在slave1-1节点启动namenode和resourcemanager进程
进入hadoop安装目录
[root@slave1 hadoop]# sbin/hadoop-daemon.sh start namenode
starting namenode, logging to /usr/local/hadoop/logs/hadoop-root-namenode-slave1.out
[root@slave1 hadoop]# sbin/hadoop-daemon.sh start namenode
starting namenode, logging to /usr/local/hadoop/logs/hadoop-root-namenode-slave1.out
十四、使用查看进程命令查看进程,并截图(要求截取主机名称),访问两个 namenode 和 resourcemanager web 界面.并截图保存(要求截到 url 状态)
[root@slave1 hadoop]# jps
7184 ResourceManager
6324 JournalNode
5861 QuorumPeerMain
6695 DFSZKFailoverController
7612 Jps
7534 NameNode
6575 DataNode
6767 NodeManager
网页访问步骤:
1、配置windows中的hosts文件
A、进入C:\Windows\System32\drivers\etc目录下找到hosts文件
B、使用记事本打开hosts文件的属性,使其可以修改内容,在最后一行加入一下内容
192.168.160.110 master1 master1.centos.com
192.168.160.111 slave1 slave1.centos.com
192.168.160.112 slave2 slave2.centos.com
2、在浏览访问两个 namenode 和 resourcemanager web 界面
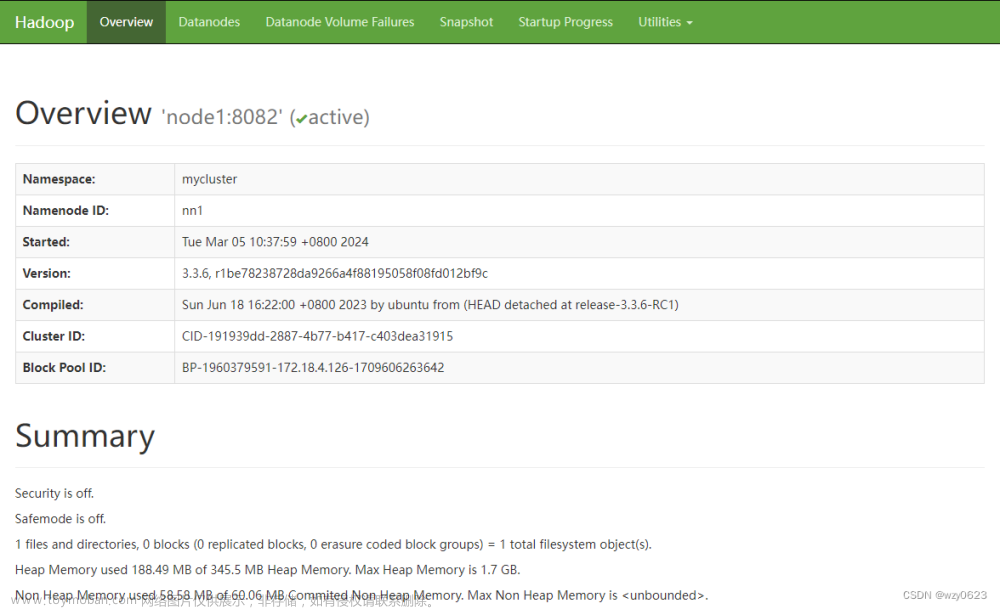
地址栏输入master1:50070 如图所示
地址栏输入slave1:50070 如图所示
resourcemanager web 界面:
点击左方Nodes可以看到当前存在的节点
十五、终止 active 的 namenode 进程,并使用 Jps 查看各个节点进程,(截上主机名称),访问两个 namenode 和 resourcemanager web 界面.并截图保存 (要求截到 url 和状态)
1、终止活跃状态的namenode
[root@master1 name]# jps
7424 ResourceManager
5973 QuorumPeerMain
8407 NodeManager
7928 DataNode
6892 JournalNode
8236 DFSZKFailoverController
8814 Jps
7823 NameNode
[root@master1 name]# kill -9 7823 //(namenode进程号)
[root@master1 name]# jps
7424 ResourceManager
8834 Jps
5973 QuorumPeerMain
8407 NodeManager
7928 DataNode
6892 JournalNode
8236 DFSZKFailoverController
[root@slave1 hadoop]# jps
7184 ResourceManager
6324 JournalNode
5861 QuorumPeerMain
6695 DFSZKFailoverController
7866 Jps
7534 NameNode
6575 DataNode
6767 NodeManager
[root@slave2 hadoop]# jps
6884 NodeManager
6118 QuorumPeerMain
6759 DataNode
7383 Jps
6606 JournalNode
实现上一步骤就会发现,杀死master1的namenode进程,master就不能访问了,slave1会自动转化换active状态

十六、重启刚才终止的 namenode,并查看 jps 进程,截图访问两个 namenode 的 web 界面,并截图保存文章来源:https://www.toymoban.com/news/detail-783425.html
[root@master1 hadoop]# sbin/hadoop-daemon.sh start namenode
starting namenode, logging to /usr/local/hadoop/logs/hadoop-root-namenode-master1.out
[root@master1 hadoop]# jps
7424 ResourceManager
5973 QuorumPeerMain
8934 NameNode
8407 NodeManager
7928 DataNode
6892 JournalNode
8236 DFSZKFailoverController
9007 Jps
再次启动master的namenode节点后,发现状态转变为standby状态,slave1仍然为active状态,两者之间进行了转换
 文章来源地址https://www.toymoban.com/news/detail-783425.html
文章来源地址https://www.toymoban.com/news/detail-783425.html
到了这里,关于Hadoop HA 部署的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!