论文传送门:
[1] GLM: General Language Model Pretraining with Autoregressive Blank Infilling
[2] Glm-130b: An open bilingual pre-trained model
Github链接:
THUDM/ChatGLM-6B
笔记
Abstract
-
GLM-130B和GPT-3 175B(davinci)相比,参数量减少,但性能提升了。 -
INT4 quantization without post training
INT4量化是一种将模型的权重和激活从使用较高位宽(如32位或16位浮点数)的表示减少到使用4位整数(INT4)的表示的过程。量化可以显著减少模型的内存需求和计算量,因此可以在资源有限的硬件上运行更大的模型,或者加快模型的推理速度。
不进行后续训练(post-training)的情况下进行INT4量化是一个挑战,因为通常量化会引入噪声和损失精度,影响模型的性能。后续训练(也称为量化感知训练)通常被用来微调量化后的模型,以恢复一些由于量化造成的性能损失。因此,如果没有进行这种微调就能实现几乎没有性能损失的INT4量化,就意味着模型具有非常好的量化鲁棒性。
这样的成果表明,GLM-130B模型可以有效地进行低位宽量化,同时保持其预测性能,这在实际应用中非常重要,因为它使得模型能够在普通消费级硬件上运行,而不是仅限于高性能服务器。这样不仅可以降低使用成本,而且可以使得更广泛的用户群体和开发者能够访问和使用这种大规模的模型。
Introduction
- 和
10B-scale model相比,训练100B-scale model需要解决的挑战:pre-training efficiency,stability,convergence。 - 预训练使用了GPU集群,包含
96个节点,每个节点配置8张 40G NVIDIA DGX-A100 GPU。训练时间为2022/5/6~2022/7/3。 - 架构:使用了[2]中的
General Language Model (GLM) algorithm。 - Pre-LN(预层归一化)
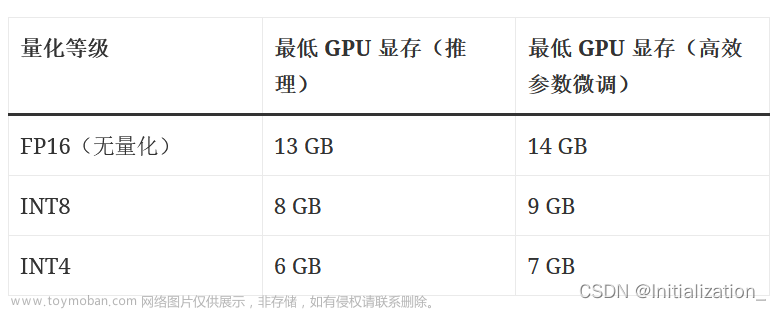
AND训练vs.推理的GPU资源使用情况
- 在Transformer模型中,Pre-LN是指在每个子层(如自注意力层和前馈网络层)的输入之前进行层归一化。这种方式通常可以提高模型的训练稳定性,尤其是在训练非常深的网络时。Pre-LN有助于解决深度Transformer模型中的梯度消失问题,因为它能够使梯度直接流向较深的层。
大模型训练和推理(inference)阶段使用的GPU数量通常有很大的区别,这主要基于以下几个方面:
1. 资源需求:
- 训练:训练阶段需要处理大量的数据并进行重复的前向传播和反向传播计算,这需要大量的计算资源。因此,通常会使用更多的GPU,甚至是成百上千的GPU,以加快训练速度和处理大规模数据集。
- 推理:推理阶段通常只需要进行单次的前向传播,计算量相对较小,因此通常需要较少的GPU。在许多应用中,一个或几个GPU就足够用于推理。
2. 并行策略:
- 数据并行:在训练时,经常使用数据并行策略,将大型数据集分割成小批量,分配到多个GPU上并行处理。
- 模型并行:对于极大的模型,可能需要使用模型并行策略,将模型的不同部分放在不同的GPU上。
- 推理时并行:在推理时,通常不需要模型并行,因为一次只处理一个或几个请求。
3. 效率和成本:
- 训练大模型通常是一项耗时且昂贵的任务,使用更多的GPU可以提高训练效率,但也大大增加了成本。
- 推理需要尽可能高效和经济,特别是在生产环境中,因此通常会尽量减少所需的GPU数量,以降低成本。
4. 可扩展性和灵活性:
- 训练阶段的模型通常被设计为能够在大规模分布式系统上扩展。
- 推理模型通常需要在各种环境中灵活部署,包括边缘设备,因此可能更注重模型的压缩和优化。
总的来说,训练大模型时使用的GPU数量远多于推理阶段,主要是因为训练阶段的资源和计算需求远大于推理。然而,随着量化技术和模型优化的发展,推理阶段所需的资源正在逐渐减少,允许即使是大模型也能在资源受限的环境中运行。

- 为什么选择
130B:单服务器支持。130亿参数的模型规模支持在单个含有A100 (8×40G) GPU的服务器上进行推理计算。
The design choices of GLM-130B
- Inductive bias:归纳偏置
在机器学习中,"inductive bias"指的是一个学习算法在学习过程中对某些模式假设的偏好,这些偏好影响了模型对数据的泛化能力。换句话说,就是当面对有限的数据时,算法如何推广到未见过的数据。它是算法的一种内在属性,决定了算法在学习时对解决问题的途径和方向的偏好。
不同的机器学习模型有不同的归纳偏置。例如:
决策树倾向于寻找数据中的分层逻辑规则。
支持向量机(SVM)通过最大化边界来寻找分类决策边界。
神经网络根据其层次结构寻找可以通过逐层变换来逼近的复杂模式。
在大型语言模型(LLM)如GLM-130B的背景下,模型架构(如Transformer架构)定义了它对语言数据中哪些特征和模式的偏好。例如,Transformer模型通过自注意力机制捕捉长距离依赖,这是它的归纳偏置之一。
然而,由于大型模型的参数量极大,探索不同架构设计的计算成本是非常高的,因此通常需要在设计阶段就做出合理的选择,以确定如何构建模型才能最好地捕捉和泛化数据中的模式。这段文字表明,GLM-130B的设计者意识到了这一点,并且在模型设计中做出了一些独特的选择,以平衡归纳偏置和计算成本。
- GLM-130B没有采用传统的GPT架构,而是使用
bidirectional GLM作为backbone。
The training stability of GLM-130B
- gradient norm的定义

梯度范数的具体变化情况也可能受到多种因素的影响,包括模型的复杂性、数据的多样性、优化算法的选择等。在某些情况下,梯度范数可能会因为模型陷入局部最小值或鞍点而暂时增大。此外,对于一些更复杂的模型或非凸优化问题,梯度范数的变化可能会更加复杂,不一定遵循单调下降的趋势。因此,梯度范数的监控通常被用作训练过程中健康状态的一个指标,帮助研究人员和工程师判断训练是否在进行得当。
框架总结
1. 模型架构
理解模型的基础架构以及与其他模型(如GPT-3等)的差异。
2. 预训练设置
了解模型预训练的具体过程,包括所使用的数据集、预训练目标、以及如何处理模型输入。
3. 训练稳定性
模型训练的稳定性对模型的性能至关重要。需关注文中提到的稳定性问题及解决方案。
4. 并行策略和模型配置
理解如何利用并行计算策略有效地训练这样大规模的模型。
5. 量化和推理优化
模型如何通过量化技术减少资源消耗,并优化推理过程。
6. 结果分析
模型在各种任务上的性能如何,特别是与其他大型模型相比。
7. 相关工作
熟悉本文中提到的相关工作,以便对整个领域有更好的理解。
8. 结论和经验教训
关注作者从训练过程中学到的经验教训。
9. 伦理评估
了解作者如何处理与大型语言模型相关的伦理风险。
10. 可复现性
文中如何确保实验结果的可复现性,以及如何使研究成果对社区开放。文章来源:https://www.toymoban.com/news/detail-784084.html
未完待续…文章来源地址https://www.toymoban.com/news/detail-784084.html
到了这里,关于中英双语大模型ChatGLM论文阅读笔记的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!