深度学习入门小菜鸟,希望像做笔记记录自己学的东西,也希望能帮助到同样入门的人,更希望大佬们帮忙纠错啦~侵权立删。
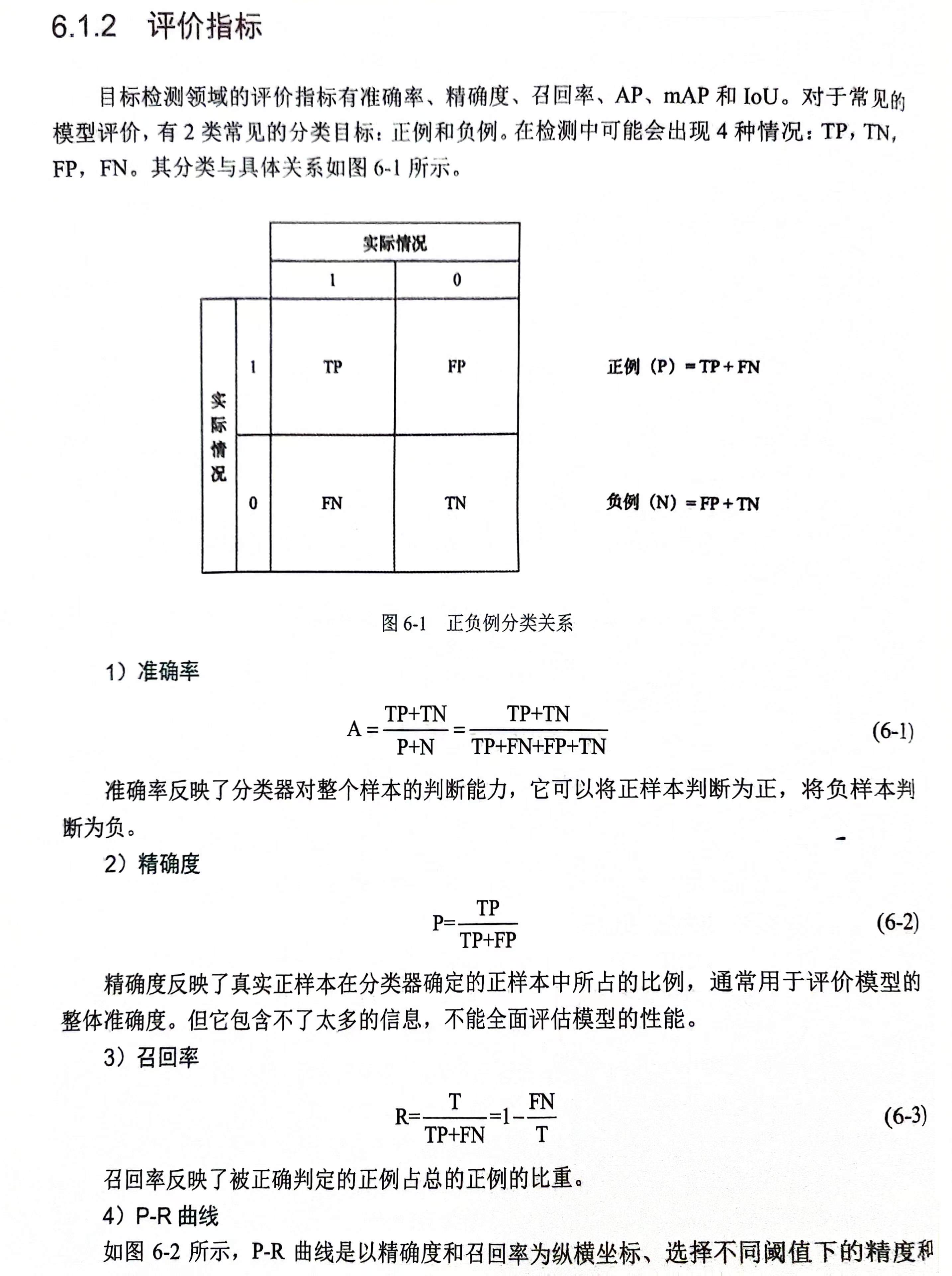
目录
一、FPN提出原因
二、FPN的参考思想
三、特征金字塔
四、FPN具体思路
一、FPN提出原因
卷积网络中,深层网络容易响应语义特征,浅层网络容易响应图像特征。然而,在目标检测中往往因为卷积网络的这个特征带来了不少麻烦:
高层网络虽然能响应语义特征,但是由于Feature Map的尺寸太小,拥有的几何信息并不多,不利于目标的检测;浅层网络虽然包含比较多的几何信息,但是图像的语义特征并不多,不利于图像的分类。这个问题在小目标检测中更为突出。
因此,如果我们能够合并深层和浅层特征的话,同时满足目标检测和图像分类的需要,那我们的问题可能就迎刃而解啦~

二、FPN的参考思想
既然我们的FPN是特征金字塔,当然参考的也与金字塔有关啦。
FPN使用的是图像金字塔的思想。
传统的图像金字塔采用输入多尺度图像的方式构建多尺度的特征。简单来说,就是我们输入一张图像后,我们可以通过一些手段获得多张不同尺度的图像,我们将这些不同尺度的图像的4个顶点连接起来,就可以构造出一个类似真实金字塔的一个图像金字塔。整个过程有点像是我们看一个物品由远及近的过程(近大远小原理)。
其中,中间的图像是原始图像,尺寸越来越小的图片是经过下采样处理后的结果,而尺寸越来越大的图片是经过上采样处理后的结果。这样我们可以提取到更多的有用的信息。
三、特征金字塔
运用这种金字塔的思想可以提高算法的性能,但是他需要大量的运算和内存。
因此特征金字塔要在速度和准确率之间进行权衡,通过它获得更加鲁棒的语义信息。
图像中存在不同大小的目标,而不同的目标具有不同的特征,所以我们需要特征金字塔来利用浅层的特征将简单的目标区分开,利用深层的特征将复杂的目标区分开。即利用大的特征图区分简单目标,利用小的特征图区分复杂目标。
四、FPN具体思路
提出的思路如下图所示:

图(a):
先对原始图像构造图像金字塔,然后在图像金字塔的每一层提出不同的特征,然后进行相应的预测。优点:精度不错;缺点:计算量大得恐怖,占用内存大。直接pass!
图(b):
通过对原始图像进行卷积和池化操作来获得不同尺寸的feature map,在图像的特征空间中构造出金字塔。
因为浅层的网络更关注于细节信息,高层的网络更关注于语义信息,更有利于准确检测出目标,因此利用最后一个卷积层上的feature map来进行预测分类。
优点:速度快、内存少。缺点:仅关注深层网络中最后一层的特征,却忽略了其它层的特征。
图(c):
同时利用低层特征和高层特征。就是首先在原始图像上面进行深度卷积,然后分别在不同的特征层上面进行预测。
优点:在不同的层上面输出对应的目标,不需要经过所有的层才输出对应的目标(即对于有些目标来说,不用进行多余的前向操作),速度更快,又提高了算法的检测性能。
缺点:获得的特征不鲁棒,都是一些弱特征(因为很多的特征都是从较浅的层获得的)。
图(d)这才是我们真正的FPN
简单概括来说就是:自下而上,自上而下,横向连接和卷积融合。
整体过程:
(1)自下而上:先把预处理好的图片送进预训练的网络,比如像ResNet这些,这一步就是构建自下而上的网络,就是对应下图中的(1,2,3)这一组金字塔。
(2)自上而下:将层3进行一个复制变成层4,对层4进行上采样操作(就是2 * up),再用1 * 1卷积对层2进行降维处理,然后将两者对应元素相加(这里就是高低层特征的一个汇总),这样我们就得到了层5,层6以此类推,是由层5和层1进行上述操作得来的。这样就构成了自上而下网络,对应下图(4,5,6)金字塔。(其中的层2与上采样后的层4进行相加,就是横向连接的操作)
(3)卷积融合:最后我们对层4,5,6分别来一个3 * 3卷积操作得到最终的预测(对应下图的predict)。

欢迎大家在评论区批评指正~文章来源:https://www.toymoban.com/news/detail-784283.html
 文章来源地址https://www.toymoban.com/news/detail-784283.html
文章来源地址https://www.toymoban.com/news/detail-784283.html
到了这里,关于深度学习中的FPN详解的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!