前言:
在当今信息时代,数据库扮演着关键的角色,用于存储和管理各种类型的数据。向量数据库是一种专门设计用于高维数据存储和快速检索的数据库系统。在不断创新和变革后,腾讯云不久前发布了AI原生(AI Native)向量数据库。

向量数据库发展背景和现状
向量数据库作为一种创新的解决方案应运而生。它专门为高维数据的存储和检索而设计,通过利用向量化存储和高效的向量索引技术,克服了传统数据库系统在处理高维数据时的局限性。向量数据库能够更高效地进行相似性搜索和近邻搜索,提供更快的查询响应时间。它采用特定的索引结构和数据组织方式,有效地解决了高维数据存储和检索的效率问题,并且能够更好地处理高维稀疏数据。
在大规模数据和复杂任务的背景下, 传统的数据库系统可能无法满足高效处理和管理数据的需求。这时候,引入向量数据库成为一种重要的解决方案。向量数据库专门针对高维数据存储和快速检索进行优化,具备处理复杂数据和大规模数据集的能力。

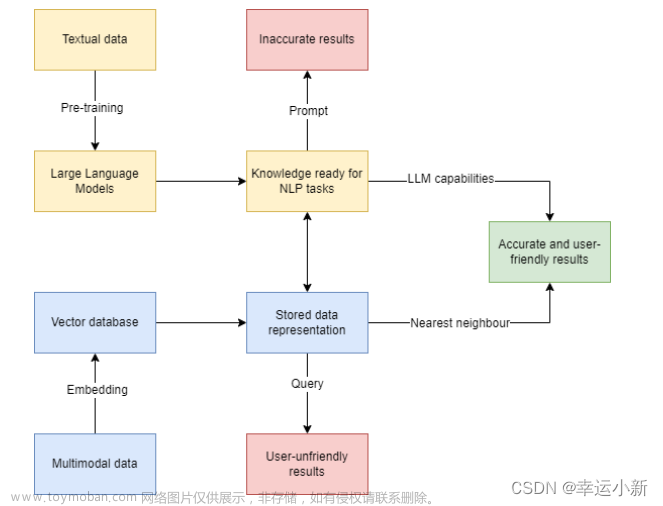
在此基础上,腾讯云发布一款全托管的自研企业级分布式数据库服务,专用于存储、检索、分析多维向量数据。该数据库支持多种索引类型和相似度计算方法,单索引支持10亿级向量规模,可支持百万级 QPS 及毫秒级查询延迟。腾讯云向量数据库不仅能为大模型提供外部知识库,提高大模型回答的准确性,还可广泛应用于推荐系统、NLP 服务、计算机视觉、智能客服等 AI 领域。
AI加持下,向量数据库是否应该重新定义?
将AI接入向量数据库的好处是多方面的。
首先,向量数据库提供高效的向量索引和相似性搜索技术,能够快速找到与给定向量相似的数据项。这对于AI中的相似度匹配、推荐系统、聚类分析等任务非常重要。

通过将AI模型训练的向量嵌入数据存储在向量数据库中,可以实现快速的相似度搜索和近邻查询,提高查询效率。向量数据库支持多模态数据的存储和检索,能够容纳不同类型的数据,如文本、图像、音频等。这对于多模态AI应用非常重要,例如视觉与语义检索、多模态生成等。

向量数据库还具备高度可扩展性和强大的并发查询能力,能够处理大规模数据和高并发访问的需求。这为训练大型AI模型和处理海量数据提供了基础设施支持。
取其精华,优势思考
作为一种专门存储和检索向量数据的服务提供给用户, 腾讯云数据库在高性能、高可用、大规模、低成本、简单易用、稳定可靠等方面体现出显著优势。

- 高性能 : 向量数据库单索引支持10亿级向量数据规模,可支持百万级 QPS 及毫秒级查询延迟。
- 高可用: 向量数据库提供多副本高可用特性,其多可用区和三节点的架构可用性可达99.99%,显著提高系统的可靠性和容错性,确保数据库在面临节点故障和负载变化等挑战时仍能正常运行。
- 大规模:向量数据库架构支持水平扩展,单实例可支持百万级 QPS,轻松满足 AI 场景下的向量存储与检索需求。
- 低成本:只需在管理控制台按照指引,简单操作几个步骤,即可快速创建向量数据库实例,全流程平台托管,无需进行任何安装、部署和运维操作,有效减少机器成本、运维成本和人力成本开销。
- 简单易用:支持丰富的向量检索能力,用户通过 HTTP API 接口即可快速操作数据库,开发效率高。同时控制台提供了完善的数据管理和监控能力,操作简单便捷。
- 稳定可靠: 向量数据库源自腾讯集团自研的向量检索引擎 OLAMA,近40个业务线上稳定运行,日均处理的搜索请求高达千亿次,服务连续性、稳定性有保障。
如何快速申请体验
腾讯云向量数据库如何快速体验?
腾讯云向量数据库目前是公测阶段。公测用户免费领用实例,每个地域最多申请2个,免费试用时长3个月。若1个月内未使用实例,平台将自动回收。
| 序号 | 步骤描述 | 具体操作 |
|---|---|---|
| 1 | 申请腾讯云账号并认证 | 注册腾讯云账号 |
| 2 | 测试申请 | 提交产品内测申请,填写用户信息。 |
| 3 | 了解向量数据库所支持的规格与类型 | 预估数据规模,选择合适的类型与规格。具体信息 |
| 4 | 确定向量数据库所部署的地域 | 选择当前支持的地域信息 |
| 5 | 规划数据库实例的私有网络与安全组 | 创建私有网络与 创建安全组,并同时设置安全组入站规则。 |
| 6 | 购买实例 | 新建数据库实例。直接选择上一步已准备的私有网络与安全组。 |
| 7 | 申请与腾讯云向量数据库在同一地域同一个 VPC 内的 Linux 云服务器 CVM | 拥有自己的云服务器 |
| 8 | 连接并操作向量数据库 | 连接并写入数据库 |
| 9 | 管理向量数据库实例 | 通过控制台直接管理实例,查看实例状态或销毁实例 |
| 10 | 智能运维 | 在控制台查看监控数据库实例的各项指标。 |
性能测试实例
通过拥抱开源工具 ann-benchmark 的方式进行向量数据库的性能测试,也方便客户公平的与其他产品进行性能比拼验证。 本文介绍了腾讯云向量数据库基于ann-benchmark 工具适配后的使用方式及相关增强功能的使用介绍;另外,优化后的测试工具也支持了多种灵活的性能 benchamrk 测试配置方案及支持 k-nn 召回率探索模式等,降低了性能测试准入门槛
前期准备
-
一台云服务器

-
一个向量数据库申请,
本次测试使用的是存储型小规格实例(1核8GB)
-
开源测试工具ann-benchmark : 可以自行搜索下载
-
上传测试工具及数据集到测试客户端 云服务器上
注:ann-benchamrk 官方数据集测试工具可自动从外网官方站点下载。 -
安装测试工具依赖
软件依赖: python 版本大于 3.6.8, 使用建议的操作系统版本上的 python3 即可
a. 安装操作系统依赖包
yum install python3-pillow-devel.x86_64
b. 解决测试工具并安装 python 运行依赖
cd ann-benchmarks
pip3 install -r requirements.txt
实例测试
1. 测试 128 维数据在 HNSW 索引下的单核查询性能
-
从数据库中获取连接地址和密钥:

-
选择测试数据集
从测试数据集说明中,找到 ann-benchamrk 已存在的名为 sift-128-euclidean 的数据集正
好是 128 维度,可使用该数据集做测试。 该数据集命令以 euclidean 结尾,表示使用
L2 相似算法 - 设置配置文件
a. 拷贝默认配置文件到自己的配置文件路径
cp ann_benchmarks/algorithms/vector_db/config.yml mytest.yml
b. 按需设置自己的配置参数
vi mytest.yml
只需要配置自己的数据库ip地址 HttpBase 和密钥 ApiKey 即可
float:
any:
- base_args: [ '@metric' ] #不需要修改
constructor: VectorDb #不需要修改
disabled: false #不需要修改
docker_tag: ann-benchmarks-vector_db #不需要修改
module: ann_benchmarks.algorithms.vector_db #不需要修改
name: vector_db #不需要修改
run_groups:
vector_db:
arg_groups:
- [ 16 ] #M , 创建 Collection 时指定的 M 参数,是一个
List , 会为每个值创建一个对应的 collection。 (top)
- DbName: db-test #测试使用的 DB 名字,collection 名字采用
自动生成方式。 命名方式为 "数据集名字_M 值"
HttpBase: 改为数据库的ip地址 #Vector DB 连接的地
址,包含协议、IP、和端口信息
NeedAuth: true # 是否需要启用认证,当前仅支持 Header 的
方式认证
User: root # 访问实例使用的用户名
ApiKey:改为自己的秘钥 #从腾讯云控制台上获取的实例访
问 API-KEY
DropDb: true # 工具是否在每次插入数据前,先删了已经存在的
DB
CreateDb: true # 工具是否需要创建新的数据库
ReCreateCollection: false # 是否每次运行前都重建
collection
DropCollectionOnDone: false # 是否在运行结束删除数据,
主要解决多表并发时内存不足场景,默认可使用 false
IndexType: FLAT # 创建 Collection 时的 index 类型, 当前
支持 FLAT, HNSW
MetricType: L2 # 创建 Collection 时的 Metric Type,同官
方 API 支持列表
ColReplicaNum: 2 # 创建 Collection 时指定多少个副本
ColShardNum: 10 # 创建 Collection 时,指定多少个 shard
EfConstruction: 500 # 创建 Collection 时,指定的邻居数
ExitOnError: true # 工具是否在 API 返回非 200 的时候退出,
如不关注错误,可忽略。
- 命令行运行测试
通过以下命令运行测试,工具会自动从外网下载 ann-benchmark 官方数据集并写入腾讯
云向量数据库。
下为对齐官方的标准的单核性能测试运行方式:
python3 run.py --dataset sift-128-euclidean --local --force --parallelism 1 --algorithm vector_db --definitions=mytest.yml --
runs 1
- 查询结果
python3 data_export.py --output=mytest.csv

- 向量数据库监控图

2.探索指定召回率时,需要设置的查询 ef 条件
-
找开探索模式,重新打开刚才的配置文件
修改配置文件中的 KNNSeekMode 为 true, 该模式测试工具会反复运行不同 ef 值的查
询,直到获得最匹配的召回率为止
-
配置探索参数
KNNSeekStartEF: 指定从哪个 ef 参考值开始查询
KNNSeekStep: 指定探索模式中,每次 ef 值变化几个单位; 如 1 则为:
KNNSeekStartEF+=1 或相减。(每次递增或递减的步长)
KNNSeekExpect: 期望找到的召回率,如 0.95 -
运行工具:
命令:
python3 data_export.py --output=mytest.csvpython3 run.py --dataset sift-128-euclidean --local --force --parallelism 1 --algorithm vector_db --definitions=mytest.yml --runs 1 --only_query
- 结果显示如下(图片中 KNNSeekExpect=0.95):
即在 ef=111 时,可获得最接近 0.95 的召回率
3.Search 检索性能测试
- 找到期望测试的 ef 或者设置 ef
通过‘(二)探索为获得指定召回率,需要设置的查询条件’ 找到期望召回率的 ef;或
者按需设置自己的 ef 值 - 压测查询配置
在配置文件中,如下使用 8 核压测查询 ef=111 的情况。 注意需要设置 KNNSeekMode
为 false
压测命令,压测时需要打开–batch 参数,同时设置–runs 为较大值以便长时间运行,如果数据库cpu资源没有打满,可使用多进程同时进行压测文章来源:https://www.toymoban.com/news/detail-784325.html
python3 run.py --dataset sift-128-euclidean --local --force --parallelism 1 -algorithm vector_db --definitions=mytest.yml --runs 999 --only_query --batch
- 查看压测结果
腾讯云向量数据库控制台提供了实例的 CPU,内存、QPS,时延等关键性能指标监
控。可从方便的控制台获取
总结
Tencent Cloud VectorDB的出现,无疑为这些企业提供了一种新的选择。从性能、可靠性和成本效益来看,Tencent Cloud VectorDB有明显优势。一起快来试试吧!!文章来源地址https://www.toymoban.com/news/detail-784325.html
到了这里,关于大模型时代下向量数据库的创新与变革的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!