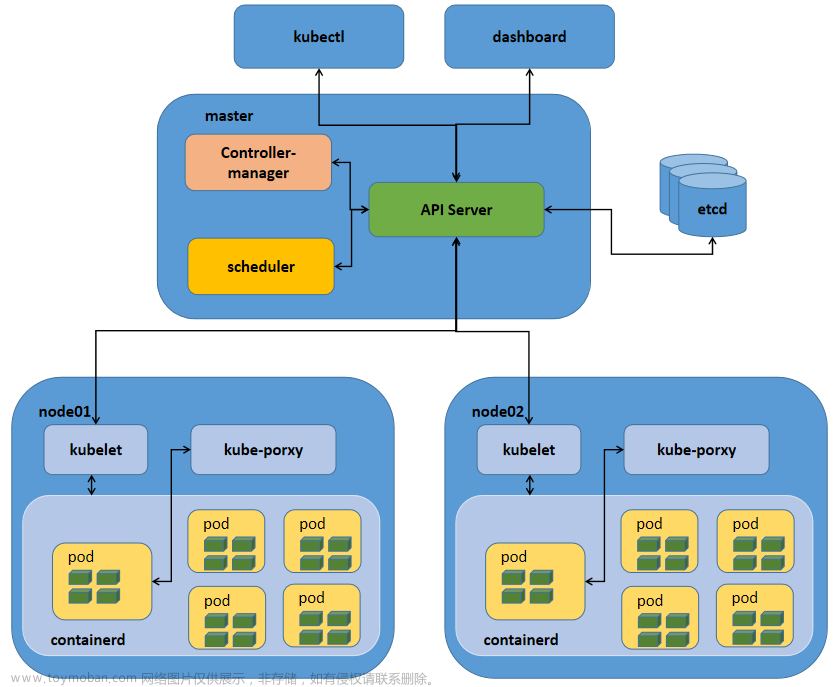
本文档主要根据k8s官网文档和其插件的官网文档,参考部分他人优秀经验,在实际操作中逐渐完成,比较详尽,适合在境内学习者和实践者参考。
实操环境基于VMware Workstation 17 pro,采用ubuntu22.04操作系统(有时也提到rhel系列系统),采用kubeadm1.27.4(部分地方提到了1.28)部署和初始化集群,采用IPVS做为负载均衡和网络转发,采用containerd1.7.3做为容器运行时,选择calico作为k8s的Pod网络组件,采用插件Dashboard做为Web控制台界面,采用Prometheus+Grafana做为监控组件。
文档涉及面广,虽反复斟酌,也难免疏漏甚至错误,欢迎指正。
[基于Ubuntu22.04部署生产级K8S集群v1.27]系列文档(陆续发布中…)
基于Ubuntu22.04部署生产级K8S集群v1.27(规划和核心组件部署篇)
基于Ubuntu22.04部署生产级K8S集群v1.27(包管理器Helm3)
基于Ubuntu22.04部署生产级K8S集群v1.27(网络模型和Calico)
基于Ubuntu22.04部署生产级K8S集群v1.27(集群管理kubectl)
基于Ubuntu22.04部署生产级K8S集群v1.27(日志架构)
基于Ubuntu22.04部署生产级K8S集群v1.27(集群弹性-Master高可用和etcd集群)
基于Ubuntu22.04部署生产级K8S集群v1.27(服务发现CoreDNS)
基于Ubuntu22.04部署生产级K8S集群v1.27(仪表板和Dashboard)
基于Ubuntu22.04部署生产级K8S集群v1.27(持久卷)
基于Ubuntu22.04部署生产级K8S集群v1.27(集群监控Prometheus&Grafana)
Kubernetes生产级集群规划和核心组件部署
一些k8s概念未在本文阐述,官方文档比较详尽,但初学者仍然可能比较迷茫,第三方文档也比较多,主要就靠积累了,将来也准备单独整理一篇通俗易懂的文档。
如果k8s各组件、概念还不清,建议先花上20~40小时以上来熟悉,否则直接部署可能更加云里雾里,徒增烦恼。
本文提到的“生产级”,是相对于开发环境来讲的,可以直接应用于生产环境,考虑到信息安全,规划虽基于生产环境,实操部分则参照模拟环境的部署写作。
参考文档
重点参考官方文档:https://kubernetes.io/zh-cn/docs/home/
也参考了一些其它文档,在本文中均有出处体现。
可以说网上每三方任何文档都无法超越官方文档,本文也只能朝着“尽快规划和部署生产级集群”的目标,大量引用官方文档的内容或地址,做一些更简易直接的说明,官方的部分阐述实在精要,缺之恐误事,就尽量引用,稍加整理,同时提供部署的实践经验。
在哪里使用k8s
你可以下载 Kubernetes,在本地机器、云或你自己的数据中心上部署 Kubernetes 集群。
诸如 kube-apiserver 或 kube-proxy 等某些 Kubernetes 组件可以在集群中以容器镜像部署。
建议尽可能将 Kubernetes 组件作为容器镜像运行,并且让 Kubernetes 管理这些组件。 但是运行容器的相关组件 —— 尤其是 kubelet,不在此列。
如果你不想自己管理 Kubernetes 集群,则可以选择托管服务,包括经过认证的平台。
对于你自己管理的集群,官方支持的用于部署 Kubernetes 的工具是 kubeadm。
安装kubeadm参考:https://kubernetes.io/zh-cn/docs/setup/production-environment/tools/kubeadm/install-kubeadm/
本文部署基于ubuntu22.04,尽可能将 Kubernetes 组件作为容器镜像运行。
生产环境考量
官文:https://kubernetes.io/zh-cn/docs/setup/production-environment/
官文中提到了以下,这里略
可用性
规模
安全性与访问管理
大规模集群的注意事项
官文:https://kubernetes.io/zh-cn/docs/setup/best-practices/cluster-large/
部分关键信息如下:
Kubernetes v1.28 单个集群支持的最大节点数为 5,000。 更具体地说,Kubernetes 旨在适应满足以下所有标准的配置:
每个节点的 Pod 数量不超过 110
节点数不超过 5,000
Pod 总数不超过 150,000
容器总数不超过 300,000
其它:
增加云资源的配额。
应该在每个故障区域至少应运行一个控制平面实例,以提供容错能力。 Kubernetes 节点不会自动将流量引向相同故障区域中的控制平面端点。 但是,你的云供应商可能有自己的机制来执行此操作。
为了提高大规模集群的性能,你可以将事件对象存储在单独的专用 etcd 实例中。
对插件资源设置CPU和内存等限制。插件的默认限制通常基于从中小规模 Kubernetes 集群上运行每个插件的经验收集的数据。 插件在大规模集群上运行时,某些资源消耗常常比其默认限制更多。 如果在不调整这些值的情况下部署了大规模集群,则插件可能会不断被杀死,因为它们不断达到内存限制。 或者,插件可能会运行,但由于 CPU 时间片的限制而导致性能不佳。
集群资源规划和网络规划
参考:https://help.aliyun.com/zh/ack/ack-managed-and-ack-dedicated/user-guide/plan-cidr-blocks-for-an-ack-cluster-1 阿里云ACK Kubernetes集群网络规划
一般性业务小于100个节点
Terway Pod独占模式或IPVlan模式的IP分配示例:
专有网络网段 192.168.0.0/16
虚拟交换机网段 192.168.0.0/19
Pod虚拟交换机网段 192.168.32.0/19 最大可分配Pod地址数 8192
Service CIDR网段 172.21.0.0/20 最大可分配Service地址数:4094
可以看出,Service的地址数一般是小于Pod地址数的,而kubeadm.yaml中serviceSubnet默认prefixlen是/12,1048576个,百万多,对一般性业务来讲,这个数字太大了。
参考https://blog.csdn.net/QW_sunny/article/details/122495071 关于PodSubnet在kubeadm初始化时的配置
podSubnet至少要包含14个IP地址。
实践中,参考官文“大规模集群的注意事项”、“阿里云ACK Kubernetes集群网络规划”,以及默认配置,考虑到pod数量,应当做好规划,大部分场景下,单个集群的node数量可规划在100个左右,pod数量1万个,但为了便于记忆,可以直接规划为65536个,prefixlen为/16。
配置可像下面这样:
networking:
podSubnet: 172.28.0.0/16
serviceSubnet: 172.29.0.0/16
Calico插件在初始化时,注意calico.yaml中的CALICO_IPV4POOL_CIDR配置,应该和kubeadm.yaml中podSubnet配置一样
安装集群核心组件
宿主机系统必要的初始配置
这里讲的宿主机是运行k8s集群的操作系统主机,即可以是vmware虚拟机、物理机或云主机,我们这里是vmware虚拟机ubuntu22.04。
宿主机配置
官文中提到了安装kubeadm最低配置是2核2G。
控制平面2核4G,至少1台,
每台节点2核2G,共2台,
每台宿主机磁盘推荐40G以上。
ubuntu安装过程
省略
安装过程建议不要分配swap,它会造成kubelet不能正常工作,即使分配了,也必须删除或关闭。
做好必要的初始配置和安全基线加固(未来将准备一篇专门的文档来做这部分工作)
更换国内镜像源
vi /etc/apt/sources.list
# See http://help.ubuntu.com/community/UpgradeNotes for how to upgrade to
# newer versions of the distribution.
deb http://mirrors.aliyun.com/ubuntu jammy main restricted
# deb-src http://mirrors.aliyun.com/ubuntu jammy main restricted
## Major bug fix updates produced after the final release of the
## distribution.
deb http://mirrors.aliyun.com/ubuntu jammy-updates main restricted
# deb-src http://mirrors.aliyun.com/ubuntu jammy-updates main restricted
## N.B. software from this repository is ENTIRELY UNSUPPORTED by the Ubuntu
## team. Also, please note that software in universe WILL NOT receive any
## review or updates from the Ubuntu security team.
deb http://mirrors.aliyun.com/ubuntu jammy universe
# deb-src http://mirrors.aliyun.com/ubuntu jammy universe
deb http://mirrors.aliyun.com/ubuntu jammy-updates universe
# deb-src http://mirrors.aliyun.com/ubuntu jammy-updates universe
## N.B. software from this repository is ENTIRELY UNSUPPORTED by the Ubuntu
## team, and may not be under a free licence. Please satisfy yourself as to
## your rights to use the software. Also, please note that software in
## multiverse WILL NOT receive any review or updates from the Ubuntu
## security team.
deb http://mirrors.aliyun.com/ubuntu jammy multiverse
# deb-src http://mirrors.aliyun.com/ubuntu jammy multiverse
deb http://mirrors.aliyun.com/ubuntu jammy-updates multiverse
# deb-src http://mirrors.aliyun.com/ubuntu jammy-updates multiverse
## N.B. software from this repository may not have been tested as
## extensively as that contained in the main release, although it includes
## newer versions of some applications which may provide useful features.
## Also, please note that software in backports WILL NOT receive any review
## or updates from the Ubuntu security team.
deb http://mirrors.aliyun.com/ubuntu jammy-backports main restricted universe multiverse
# deb-src http://mirrors.aliyun.com/ubuntu jammy-backports main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu jammy-security main restricted
# deb-src http://mirrors.aliyun.com/ubuntu jammy-security main restricted
deb http://mirrors.aliyun.com/ubuntu jammy-security universe
# deb-src http://mirrors.aliyun.com/ubuntu jammy-security universe
deb http://mirrors.aliyun.com/ubuntu jammy-security multiverse
# deb-src http://mirrors.aliyun.com/ubuntu jammy-security multiverse
sudo apt update
常用软件包安装
sudo apt-get install vim wget netstat curl inetutils-ping telnet lrzsz
暂时关闭防火墙
sudo ufw status # ufw(如果安装了)查看当前的防火墙状态:inactive状态是防火墙关闭状态 active是开启状态。
sudo ufw enable | disable # 启动、关闭防火墙
禁用SELINUX
sudo setenforce 0
sudo vim /etc/selinux/config
修改如下
SELINUX=disabled
时区设置和时间同步
sudo cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
配置好时间同步,vmware虚拟机建议安装好VMwareTools,可设置好时间和宿主机同步,即使宿主机休眠也不影响虚拟机的时间。
其它场景可配置好NTP时间同步
时间不同步会出error
设备主机名
在/etc/hosts中添加下列解析,例:
192.168.130.88 k8smaster.loadbalancer.local
192.168.130.88 k8smaster01
192.168.130.89 k8snode001
192.168.130.90 k8snode002
部署集群前配置好主机名是必要的,部署好之后再来改就很麻烦了。
修改系统主机名,执行下面的命令,包括会自动修改/etc/hostname中的内容,以控制平面的为例:
hostname=k8smaster01
sudo hostnamectl set-hostname $hostname
sudo hostnamectl set-hostname $hostname --pretty
sudo hostnamectl set-hostname $hostname --static
sudo hostnamectl set-hostname $hostname --transient
简要关系图
k8s集群master和worker节点主机名修改
修改master 节点的主机名
不建议修改 master 节点的主机名,因为 Kubernetes 集群中的许多组件都会使用主机名来进行通信和识别。
如果您修改了 master 节点的主机名,可能会导致某些组件无法正常工作,从而影响整个集群的健康状态。
如果您确实需要修改主机名,建议在修改前备份好相关配置文件,并且在修改后进行全面的测试和验证。
证书签发也跟主机名有关。
在 Kubernetes 集群中,每个节点都需要使用 TLS 证书来进行安全通信。
这些证书通常会包含节点的主机名信息,用于验证通信的身份。
如果您修改了节点的主机名,可能会导致证书无法正常验证,从而影响节点间的安全通信。
因此,在修改节点主机名时,还需要相应地更新证书信息,以确保节点间的安全通信能够正常工作。
openssl x509 -noout -text -in /etc/kubernetes/pki/apiserver.crt
修改节点名称
参考:https://blog.csdn.net/weixin_33858485/article/details/92386452 k8s集群修改节点和master的hostname之后需要如何调整
修改节点名称还要修改calico服务中的主机名
修改主机名总结
从以上分享的经验来看,无论是修改master还是worker节点主机名,都是非常麻烦的,如果是生产环境,不建议修改,如果是初始部署的实验环境,或者不必保留数据的集群,最直接的办法就是,按照“清理节点”的步骤,清理后,再重新初始化节点,重建集群。
综上,鉴于修改主机名的困难,应该在创建集群时,就把主机名规划好,配置好。
安装kubeadm
准备工作
参考:https://kubernetes.io/zh-cn/docs/setup/production-environment/tools/kubeadm/install-kubeadm/
一台兼容的 Linux 主机。Kubernetes 项目为基于 Debian 和 Red Hat 的 Linux 发行版以及一些不提供包管理器的发行版提供通用的指令。
每台机器 2 GB 或更多的 RAM(如果少于这个数字将会影响你应用的运行内存)。
CPU 2 核心及以上。
集群中的所有机器的网络彼此均能相互连接(公网和内网都可以)。
节点之中不可以有重复的主机名、MAC 地址或 product_uuid。
开启机器上的某些端口。
禁用交换分区。为了保证 kubelet 正常工作,你必须禁用交换分区。例如,sudo swapoff -a 将暂时禁用交换分区。要使此更改在重启后保持不变,请确保在如 /etc/fstab、systemd.swap 等配置文件中禁用交换分区,具体取决于你的系统如何配置。
准备工作的具体指令参考
确保每个节点上 MAC 地址和 product_uuid 的唯一性
你可以使用命令 ip link 或 ifconfig -a 来获取网络接口的 MAC 地址
可以使用 sudo cat /sys/class/dmi/id/product_uuid 命令对 product_uuid 校验
一般来讲,硬件设备会拥有唯一的地址,但是有些虚拟机的地址可能会重复。 Kubernetes 使用这些值来唯一确定集群中的节点。 如果这些值在每个节点上不唯一,可能会导致安装失败。
禁用所有swap交换分区
sudo swapoff -a
了解端口和协议
当你在一个有严格网络边界的环境里运行 Kubernetes,例如拥有物理网络防火墙或者拥有公有云中虚拟网络的自有数据中心, 了解 Kubernetes 组件使用了哪些端口和协议是非常有用的。
官文:https://kubernetes.io/zh-cn/docs/reference/networking/ports-and-protocols/
控制面(Master)
协议 方向 端口范围 目的 使用者
TCP 入站 6443 Kubernetes API server 所有
TCP 入站 2379-2380 etcd server client API kube-apiserver, etcd
TCP 入站 10250 Kubelet API 自身, 控制面
TCP 入站 10259 kube-scheduler 自身
TCP 入站 10257 kube-controller-manager 自身
工作节点(Worker node)
协议 方向 端口范围 目的 使用者
TCP 入站 10250 Kubelet API 自身, 控制面
TCP 入站 30000-32767 NodePort Services(默认端口范围) 所有
可以使用 netcat 之类的工具来检查端口是否启用,例如:
nc 127.0.0.1 6443
配置服务器支持开启ipvs的前提条件
kube-proxy开启ipvs的前提需要加载以下的内核模块:
ip_vs
ip_vs_rr
ip_vs_wrr
ip_vs_sh
nf_conntrack
sudo vi /etc/modules-load.d/ipvs.conf
添加上述模块
sudo modprobe – ip_vs
sudo modprobe – ip_vs_rr
sudo modprobe – ip_vs_wrr
sudo modprobe – ip_vs_sh
sudo modprobe – nf_conntrack
lsmod | grep -e ip_vs -e nf_conntrack
接下来还需要确保各个节点上已经安装了ipset软件包,为了便于查看ipvs的代理规则,最好安装一下管理工具ipvsadm。
如果没有安装好ipvs相关模块,则即使kube-proxy的配置开启了ipvs模式,也会退回到iptables模式。
安装容器运行时
官文:https://kubernetes.io/zh-cn/docs/setup/production-environment/container-runtimes/
https://kubernetes.io/zh-cn/docs/setup/production-environment/tools/kubeadm/install-kubeadm/#installing-runtime
说明:为什么要安装容器运行时?
“容器运行时”(Container Runtime)是负责运行容器的软件,以使 Pod 可以运行在上面。
默认情况下,Kubernetes 使用 容器运行时接口(Container Runtime Interface,CRI) 来与你所选择的容器运行时交互。
如果你不指定运行时,kubeadm 会自动尝试通过扫描已知的端点列表来检测已安装的容器运行时。
如果检测到有多个或者没有容器运行时,kubeadm 将抛出一个错误并要求你指定一个想要使用的运行时。
Docker Engine 没有实现 CRI, 而这是容器运行时在 Kubernetes 中工作所需要的。 为此,必须安装一个额外的服务 cri-dockerd。 cri-dockerd 是一个基于传统的内置 Docker 引擎支持的项目, 它在 1.24 版本从 kubelet 中移除。
v1.24 之前的 Kubernetes 版本直接集成了 Docker Engine 的一个组件,名为 dockershim。 这种特殊的直接整合不再是 Kubernetes 的一部分 (这次删除被作为 v1.20 发行版本的一部分宣布)。
容器运行时有下列:
containerd (推荐)
Dockershim (不推荐,且k8s1.24开始弃用)
CRI-O (推荐)
cri-dockerd (不推荐)
Mirantis
来了解一下:Kubernetes、Docker、Dockershim、Containerd、runC、CRI、OCI的关系
参考:https://zhuanlan.zhihu.com/p/630976577
CRI可以实现kubelet对containerd、CRI-O的统一管理。同时,Kubernetes 1.24将dockershim 组件从 kubelet 中删除后,也建议用户使用更加轻量的容器运行时 containerd 或 CRI-O。
虽然 dockershim 组件在 Kubernetes v1.24 发行版本中已被移除。不过来自第三方的替代品 cri-dockerd 可以适配器允许你通过 容器运行时接口(Container Runtime Interface,CRI) 来使用 Docker Engine(并不建议使用,除非有特殊的需求)。
对于Docker生成的镜像,也并不受任何影响,Docker 对镜像的构建是符合 OCI 标准的 (runC 也是 Docker 独立出去的),镜像适用于所有 CRI 容器运行时。
参考:https://cloud.tencent.com/developer/article/1791730
有评论:从我个人角度考虑的话,我个人的选择是:containerd,他速度快,配置方便,相当可靠和安全,不过 cri-o 已经支持 cgroupsv2 了,所以如果我使用 fedora 或者 centos8 的话我会优先选择 cri-o。
本文档考虑containerd做为CRI。
转发 IPv4 并让 iptables 看到桥接流量
(这是安装和配置容器运行时的先决条件)
cat <<EOF | sudo tee /etc/modules-load.d/k8s.conf
overlay
br_netfilter
EOF
sudo modprobe overlay
sudo modprobe br_netfilter
# 设置所需的 sysctl 参数,参数在重新启动后保持不变
cat <<EOF | sudo tee /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-iptables = 1
net.bridge.bridge-nf-call-ip6tables = 1
net.ipv4.ip_forward = 1
EOF
# 应用 sysctl 参数而不重新启动
sudo sysctl --system
通过运行以下指令确认 br_netfilter 和 overlay 模块被加载:
lsmod | grep br_netfilter
lsmod | grep overlay
通过运行以下指令确认 net.bridge.bridge-nf-call-iptables、net.bridge.bridge-nf-call-ip6tables 和 net.ipv4.ip_forward 系统变量在你的 sysctl 配置中被设置为 1:
cgroup 驱动
(容器运行时的驱动,位于最底层)
在 Linux 上,控制组(CGroup)用于限制分配给进程的资源。
kubelet 和底层容器运行时都需要对接控制组来强制执行 为 Pod 和容器管理资源 并为诸如 CPU、内存这类资源设置请求和限制。若要对接控制组,kubelet 和容器运行时需要使用一个 cgroup 驱动。 关键的一点是 kubelet 和容器运行时需使用相同的 cgroup 驱动并且采用相同的配置。
可用的 cgroup 驱动有两个:
cgroupfs
systemd
当 systemd 是初始化系统时, 不 推荐使用 cgroupfs 驱动,因为 systemd 期望系统上只有一个 cgroup 管理器。
使用 cgroup v2, 则应用 systemd cgroup 驱动取代 cgroupfs
要将 systemd 设置为 cgroup 驱动,需编辑 KubeletConfiguration 的 cgroupDriver 选项,并将其设置为 systemd。例如:
apiVersion: kubelet.config.k8s.io/v1beta1
kind: KubeletConfiguration
…
cgroupDriver: systemd
说明:从 v1.22 开始,在使用 kubeadm 创建集群时,如果用户没有在 KubeletConfiguration 下设置 cgroupDriver 字段,kubeadm 默认使用 systemd。
如果你将 systemd 配置为 kubelet 的 cgroup 驱动,你也必须将 systemd 配置为容器运行时的 cgroup 驱动。
CRI 版本支持
你的容器运行时必须至少支持 v1alpha2 版本的容器运行时接口。
Kubernetes 从 1.26 版本开始仅适用于 v1 版本的容器运行时(CRI)API。早期版本默认为 v1 版本, 但是如果容器运行时不支持 v1 版本的 API, 则 kubelet 会回退到使用(已弃用的)v1alpha2 版本的 API。
安装containerd做为容器运行时
containerd官网地址:https://github.com/containerd/containerd/blob/main/docs/getting-started.md
containerd官网提供了多种安装方式,
选项一,二进制包安装
ubuntu和rhel系可以用二进制包安装,其它系统可用源码包安装,下面是二进制安装:
Step 1: Installing containerd
下载地址:https://github.com/containerd/containerd/releases
wget https://github.com/containerd/containerd/releases/download/v1.7.3/containerd-1.7.3-linux-amd64.tar.gz
sudo tar Cxzvf /usr/local containerd-1.7.3-linux-amd64.tar.gz
If you intend to start containerd via systemd, you should also download the containerd.service unit file from https://raw.githubusercontent.com/containerd/containerd/main/containerd.service into /usr/local/lib/systemd/system/containerd.service, and run the following commands:
wget https://raw.githubusercontent.com/containerd/containerd/main/containerd.service
sudo mv containerd.service /usr/lib/systemd/system/ # ubuntu是这个路径,rhel系是官文中提到的路径
sudo systemctl daemon-reload && sudo systemctl enable --now containerd
systemctl status containerd
Step 2: Installing runc
curl -LO https://github.com/opencontainers/runc/releases/download/v1.1.8/runc.amd64 && sudo install -m 755 runc.amd64 /usr/local/sbin/runc
The binary is built statically and should work on any Linux distribution.
Step 3: Installing CNI plugins
wget https://github.com/containernetworking/plugins/releases/download/v1.3.0/cni-plugins-linux-amd64-v1.3.0.tgz
sudo tar Cxzvf /opt/cni/bin cni-plugins-linux-amd64-v1.3.0.tgz
The binaries are built statically and should work on any Linux distribution.
选项二:deb或dnl安装
The containerd.io packages in DEB and RPM formats are distributed by Docker (not by the containerd project). See the Docker documentation
https://docs.docker.com/engine/install/ubuntu/
https://docs.docker.com/engine/install/centos/
就是deb或rpm包安装docker环境的过程中,就可以顺便装上了containerd.io,很快,例如:
先有一些卸载老包的步骤,然后
sudo apt-get update
sudo apt-get install ca-certificates curl gnupg
sudo install -m 0755 -d /etc/apt/keyrings
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /etc/apt/keyrings/docker.gpg
sudo chmod a+r /etc/apt/keyrings/docker.gpg
echo \
"deb [arch="$(dpkg --print-architecture)" signed-by=/etc/apt/keyrings/docker.gpg] https://download.docker.com/linux/ubuntu \
"$(. /etc/os-release && echo "$VERSION_CODENAME")" stable" | \
sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
sudo apt-get update
sudo apt-get install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
sudo docker run hello-world
经验:如果按二进制包安装了,再通过dnl或yum安装,会有提示,容器运行时保持当前配置(/etc/containerd/config.toml)还是安装配置,为了稳定,一般选择之前的配置,即当前配置。
containerd的配置
修改containerd的配置,其中containerd默认从k8s官网拉取镜像,几乎不会成功,需变更为境内源。
sudo mkdir -p /etc/containerd #创建一个目录用于存放containerd的配置文件
containerd config default | sudo tee /etc/containerd/config.toml #把containerd配置导出到文件
sudo vim /etc/containerd/config.toml #修改配置文件
[plugins.“io.containerd.grpc.v1.cri”]
…
sandbox_image = “registry.aliyuncs.com/google_containers/pause:3.9” #搜索sandbox_image,把原来的registry.k8s.io/pause:3.8改为"registry.aliyuncs.com/google_containers/pause:3.9"
[plugins.“io.containerd.grpc.v1.cri”.containerd.runtimes.runc.options]
…
SystemdCgroup = true #搜索SystemdCgroup,把这个false改为true
[plugins.“io.containerd.grpc.v1.cri”.registry]
config_path = “/etc/containerd/certs.d” #搜索config_path,配置镜像加速地址(这是一个目录下面创建)
镜像加速配置
创建镜像加速的目录
sudo mkdir /etc/containerd/certs.d/docker.io -pv
#配置加速
sudo cat > /etc/containerd/certs.d/docker.io/hosts.toml <<\EOF
server = “https://docker.io”
[host.“https://xxx.mirror.aliyuncs.com”]
capabilities = [“pull”, “resolve”]
EOF
最好检查一下hosts.toml的实际内容,其中xxx.mirror.aliyuncs.com在aliyun.com上面申请。
加载containerd的内核模块
(如果/etc/modules-load.d/k8s.conf中配置了,不必再重复配置)
cat <<EOF | sudo tee /etc/modules-load.d/containerd.conf
overlay
br_netfilter
EOF
sudo modprobe overlay
sudo modprobe br_netfilter
#重启containerd
sudo systemctl restart containerd
systemctl status containerd
测验containerd
拉取镜像,测试containerd是否能创建和启动成功
说明:ctr命令是containerd CLI,类似于docker命令,但又不是docker的命令。containerd和cri-docker是不同的容器运行时。
sudo ctr i pull docker.io/library/nginx:alpine # 能正常拉取镜像说明没啥问题
sudo ctr images ls # 查看镜像
sudo ctr c create --net-host docker.io/library/nginx:alpine nginx # 创建容器
sudo ctr task start -d nginx # 启动容器,正常说明containerd没啥问题
sudo ctr containers ls # 查看容器
sudo ctr tasks kill -s SIGKILL nginx # 终止容器
sudo ctr containers rm nginx # 删除容器
crictl手动操作容器运行时containerd
containerd 也有类似 docker 的 CLI 工具,改为 crictl pull 也可以拉镜像,参数比ctr更多。如果能操作节点,是可以在每个节点上都提前拉取镜像,然后配置 imagePullPolicy为IfNotPresent。
官文:https://kubernetes.io/zh-cn/docs/concepts/containers/images/#using-a-private-registry
如果系统中存在多个容器运行时,需要先配置
vi /etc/crictl.yaml
内容如下
runtime-endpoint: unix:///run/containerd/containerd.sock
image-endpoint: unix:///run/containerd/containerd.sock
timeout: 10
debug: false
使用 containerd 作为 CRI 运行时的必要步骤
如果你从软件包(例如,RPM 或者 .deb)中安装 containerd,你可能会发现其中默认禁止了 CRI 集成插件。
你需要启用 CRI 支持才能在 Kubernetes 集群中使用 containerd。 要确保 cri 没有出现在 /etc/containerd/config.toml 文件中 disabled_plugins 列表内。如果你更改了这个文件,也请记得要重启 containerd。
如果你在初次安装集群后或安装 CNI 后遇到容器崩溃循环,则随软件包提供的 containerd 配置可能包含不兼容的配置参数。考虑按照 getting-started.md 中指定的 containerd config default > /etc/containerd/config.toml 重置 containerd 配置,然后相应地设置上述配置参数。
如果你应用此更改,请确保重新启动 containerd:
sudo systemctl restart containerd
安装kubeadm、kubelet、kubectl
你需要在每台机器上安装以下的软件包:
kubeadm:用来初始化集群的指令。
kubelet:在集群中的每个节点上用来启动 Pod 和容器等。
kubectl:用来与集群通信的命令行工具。
kubeadm 不能帮你安装或者管理 kubelet 或 kubectl, 所以你需要确保它们与通过 kubeadm 安装的控制平面的版本相匹配。 如果不这样做,则存在发生版本偏差的风险,可能会导致一些预料之外的错误和问题。 然而,控制平面与 kubelet 之间可以存在一个次要版本的偏差,但 kubelet 的版本不可以超过 API 服务器的版本。 例如,1.7.0 版本的 kubelet 可以完全兼容 1.8.0 版本的 API 服务器,反之则不可以。
更新 apt 包索引并安装使用 Kubernetes apt 仓库所需要的包:
sudo apt-get update
sudo apt-get install -y apt-transport-https ca-certificates curl
下载 Google Cloud 公开签名秘钥:
curl -fsSL https://dl.k8s.io/apt/doc/apt-key.gpg | sudo gpg --dearmor -o /etc/apt/keyrings/kubernetes-archive-keyring.gpg
或
curl https://mirrors.aliyun.com/kubernetes/apt/doc/apt-key.gpg | sudo apt-key add
添加 Kubernetes apt 仓库:
echo "deb [signed-by=/etc/apt/keyrings/kubernetes-archive-keyring.gpg] https://apt.kubernetes.io/ kubernetes-xenial main" | sudo tee /etc/apt/sources.list.d/kubernetes.list
或
echo "deb [signed-by=/etc/apt/keyrings/kubernetes-archive-keyring.gpg] http://mirrors.ustc.edu.cn/kubernetes/apt kubernetes-xenial main" | sudo tee /etc/apt/sources.list.d/kubernetes.list
或
echo "deb [signed-by=/etc/apt/keyrings/kubernetes-archive-keyring.gpg] http://mirrors.aliyun.com/kubernetes/apt kubernetes-xenial main" | sudo tee /etc/apt/sources.list.d/kubernetes.list
sudo apt-get update
sudo apt-get install -y kubelet kubeadm kubectl
sudo apt-mark hold kubelet kubeadm kubectl # 锁定版本
kubectl
kubectl version --short
输出:
Client Version: v1.27.4
Kustomize Version: v5.0.1
kubeadm token list
sudo systemctl enable kubelet.service # 如果开启了swap就会报错
使用 kubeadm 创建集群
https://kubernetes.io/zh-cn/docs/setup/production-environment/tools/kubeadm/create-cluster-kubeadm/
使用 kubeadm,你能创建一个符合最佳实践的最小化 Kubernetes 集群。 事实上,你可以使用 kubeadm 配置一个通过 Kubernetes 一致性测试的集群。 kubeadm 还支持其他集群生命周期功能, 例如启动引导令牌和集群升级。
你可以在各种机器上安装和使用 kubeadm:笔记本电脑, 一组云服务器
本节目标
- 安装单个控制平面的 Kubernetes 集群
- 在集群上安装 Pod 网络,以便你的 Pod 可以相互连通
主机准备
在所有主机上安装 容器运行时 和 kubeadm
准备所需的容器镜像(可选)
这个步骤是可选的,只适用于你希望 kubeadm init 和 kubeadm join 不去下载存放在 registry.k8s.io 上的默认的容器镜像的情况。
当你在离线的节点上创建一个集群的时候,Kubeadm 有一些命令可以帮助你预拉取所需的镜像。 阅读离线运行 kubeadm 获取更多的详情。
Kubeadm 允许你给所需要的镜像指定一个自定义的镜像仓库。 阅读使用自定义镜像 获取更多的详情。
初始化控制平面节点
控制平面节点是运行控制平面组件的机器, 包括 etcd(集群数据库) 和 API 服务器 (命令行工具 kubectl 与之通信)。
- (推荐)如果计划将单个控制平面 kubeadm 集群升级成高可用, 你应该指定 --control-plane-endpoint 为所有控制平面节点设置共享端点。 端点可以是负载均衡器的 DNS 名称或 IP 地址。(kubeadm 不支持将没有 --control-plane-endpoint 参数的单个控制平面集群转换为高可用性集群。)
- 选择一个 Pod 网络插件,并验证是否需要为 kubeadm init 传递参数。 根据你选择的第三方网络插件,你可能需要设置 --pod-network-cidr 的值。 请参阅安装 Pod 网络附加组件。
- (可选)kubeadm 试图通过使用已知的端点列表来检测容器运行时。 使用不同的容器运行时或在预配置的节点上安装了多个容器运行时,请为 kubeadm init 指定 --cri-socket 参数。 请参阅安装运行时。
- (可选)除非另有说明,否则 kubeadm 使用与默认网关关联的网络接口来设置此控制平面节点 API server 的广播地址。 要使用其他网络接口,请为 kubeadm init 设置 --apiserver-advertise-address= 参数。 要部署使用 IPv6 地址的 Kubernetes 集群, 必须指定一个 IPv6 地址,例如 --apiserver-advertise-address=2001:db8::101。
结合一份配置文件来使用 kubeadm init
官文:https://kubernetes.io/zh-cn/docs/reference/setup-tools/kubeadm/kubeadm-init/#config-file
通过一份配置文件而不是使用命令行参数来配置 kubeadm init 命令是可能的, 但是一些更加高级的功能只能够通过配置文件设定。
先打印集群初始化默认的使用的配置,在此基础上定制新的kubeadm.yaml:
kubeadm config print init-defaults --component-configs KubeletConfiguration > ~/kubeadm.yaml
其中
name 需要变更为master的名称,例如k8smaster01
advertiseAddress需要替换master节点IP
criSocket是cri的套接字,containerd是unix:///var/run/containerd/containerd.sock
imageRepository是镜像源,registry.k8s.io这个源要可换成阿里的:registry.aliyuncs.com/google_containers
cgroupDriver设置kubelet的cgroupDriver为systemd
clusterDNS的IP以0.10结尾为佳,不然初始化过程中也会有提示,指定另一个IP也未尝不可,但未实践过,还是尽量听程序的建议吧。
networking的podSubnet: 172.28.0.0/16,serviceSubnet: 172.29.0.0/16。
controlPlaneEndpoint就是创建多个控制面板所必要的参数,设为k8smaster.loadbalancer.local:6443
设置kube-proxy代理模式为ipvs,追加如下:
---
apiVersion: kubeproxy.config.k8s.io/v1alpha1
kind: KubeProxyConfiguration
mode: ipvs
关于kubeadm配置的更多帮助,见官文:https://kubernetes.io/zh-cn/docs/reference/config-api/kubeadm-config.v1beta3/
k8s1.27.4一次完整的kubeadm.yaml内容:
apiVersion: kubeadm.k8s.io/v1beta3
bootstrapTokens:
- groups:
- system:bootstrappers:kubeadm:default-node-token
token: abcdef.0123456789abcdef
ttl: 24h0m0s
usages:
- signing
- authentication
kind: InitConfiguration
localAPIEndpoint:
advertiseAddress: 192.168.130.88
bindPort: 6443
nodeRegistration:
criSocket: unix:///var/run/containerd/containerd.sock
imagePullPolicy: IfNotPresent
name: k8smaster01
taints: null
---
apiServer:
timeoutForControlPlane: 4m0s
apiVersion: kubeadm.k8s.io/v1beta3
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
controllerManager: {}
dns: {}
etcd:
local:
dataDir: /var/lib/etcd
imageRepository: registry.aliyuncs.com/google_containers
kind: ClusterConfiguration
kubernetesVersion: 1.27.0
networking:
dnsDomain: cluster.local
podSubnet: 172.28.0.0/16
serviceSubnet: 172.29.0.0/16
controlPlaneEndpoint: k8smaster.loadbalancer.local:6443
scheduler: {}
---
apiVersion: kubelet.config.k8s.io/v1beta1
authentication:
anonymous:
enabled: false
webhook:
cacheTTL: 0s
enabled: true
x509:
clientCAFile: /etc/kubernetes/pki/ca.crt
authorization:
mode: Webhook
webhook:
cacheAuthorizedTTL: 0s
cacheUnauthorizedTTL: 0s
cgroupDriver: systemd
clusterDNS:
- 172.29.0.10
clusterDomain: cluster.local
containerRuntimeEndpoint: ""
cpuManagerReconcilePeriod: 0s
evictionPressureTransitionPeriod: 0s
fileCheckFrequency: 0s
healthzBindAddress: 127.0.0.1
healthzPort: 10248
httpCheckFrequency: 0s
imageMinimumGCAge: 0s
kind: KubeletConfiguration
logging:
flushFrequency: 0
options:
json:
infoBufferSize: "0"
verbosity: 0
memorySwap: {}
nodeStatusReportFrequency: 0s
nodeStatusUpdateFrequency: 0s
resolvConf: /run/systemd/resolve/resolv.conf
rotateCertificates: true
runtimeRequestTimeout: 0s
shutdownGracePeriod: 0s
shutdownGracePeriodCriticalPods: 0s
staticPodPath: /etc/kubernetes/manifests
streamingConnectionIdleTimeout: 0s
syncFrequency: 0s
volumeStatsAggPeriod: 0s
---
apiVersion: kubeproxy.config.k8s.io/v1alpha1
kind: KubeProxyConfiguration
mode: ipvs
这里定制了imageRepository为阿里云的registry,避免因gcr被墙,无法直接拉取镜像。criSocket设置了容器运行时为containerd。 同时设置kubelet的cgroupDriver为systemd,设置kube-proxy代理模式为ipvs。
集群初始化完成后,可查看到kube-proxy代理模式
参考:https://blog.csdn.net/wy_hhxx/article/details/119858961
kubectl get pod -n kube-system # 查看kube-proxy的Name
kubectl logs kube-proxy-6vfqw -n kube-system # 根据刚才查到的kube-proxy的Name,查询其日志
在日志中可以看到用的ipvs还是iptables。
在开始初始化集群之前可以使用kubeadm config images pull --config kubeadm.yaml预先在各个服务器节点上拉取所k8s需要的容器镜像。
sudo kubeadm config images pull --config kubeadm.yaml
接下来使用kubeadm初始化集群执行下面的命令:
sudo kubeadm init --config kubeadm.yaml --control-plane-endpoint=“k8smaster.loadbalancer.local:6443” --upload-certs
这里使用了–control-plane-endpoint,是为了将来可以升级为高可用集群,即多个控制平面,如果在配置文件中配置了,这里就不必使用了,如下:
sudo kubeadm init --config kubeadm.yaml --upload-certs
创建高可用集群参考官文:https://kubernetes.io/zh-cn/docs/setup/production-environment/tools/kubeadm/high-availability/
将会整理文档[基于Ubuntu22.04部署生产级K8S集群v1.27(集群弹性-Master高可用和etcd集群)]
根据输出的内容基本上可以看出手动初始化安装一个Kubernetes集群所需要的关键步骤。 其中有以下关键内容:
[certs]生成相关的各种证书
[kubeconfig]生成相关的kubeconfig文件
[kubelet-start] 生成kubelet的配置文件"/var/lib/kubelet/config.yaml"
[control-plane]使用/etc/kubernetes/manifests目录中的yaml文件创建apiserver、controller-manager、scheduler的静态pod
[bootstraptoken]生成token记录下来,后边使用kubeadm join往集群中添加节点时会用到
[addons]安装基本插件:CoreDNS, kube-proxy
成功后有下列提示:
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
You can now join any number of the control-plane node running the following command on each as root:
kubeadm join k8smaster.loadbalancer.local:6443 --token [token] \
--discovery-token-ca-cert-hash sha256:[sha256] \
--control-plane --certificate-key [key]
Please note that the certificate-key gives access to cluster sensitive data, keep it secret!
As a safeguard, uploaded-certs will be deleted in two hours; If necessary, you can use
"kubeadm init phase upload-certs --upload-certs" to reload certs afterward.
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join k8smaster.loadbalancer.local:6443 --token [token] \
--discovery-token-ca-cert-hash sha256:[sha256]
可以看到有加入另一个控制平面的命令,其中token和sha256被我替换掉了,请注意你实际环境中的值。
开始使用集群前的操作
mkdir -p $HOME/.kube #复制上面提示照着做即可
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config #复制上面提示照着做即可
sudo chown $(id -u):$(id -g) $HOME/.kube/config #复制上面提示照着做即可
export KUBECONFIG=/etc/kubernetes/admin.conf
查看一下集群状态,确认个组件都处于healthy状态
kubectl get cs # 默认不要用sudo
报错:
E0812 15:44:43.823568 28146 memcache.go:265] could not get current server API group list: Get “http://localhost:8080/api?timeout=32s”: dial tcp 127.0.0.1:8080: connect: connection refused
处理:在/etc/systemd/system/kubelet.service.d/10-kubeadm.conf中添加:
Environment=“KUBELET_SYSTEM_PODS_ARGS=–pod-manifest-path=/etc/kubernetes/manifests --allow-privileged=true --fail-swap-on=false”
重启kubelet
sudo systemctl restart kubelet
未成功
重启系统,再运行kubectl get cs,成功,该现象可复现,原因暂未知
初始化完成后有下列提示:
接下来可以部署网络插件:
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
/docs/concepts/cluster-administration/addons/
添加节点:
You can now join any number of machines by running the following on each node
as root:
kubeadm join <control-plane-host>:<control-plane-port> --token <token> --discovery-token-ca-cert-hash sha256:<hash>
其中token和sha256被我替换掉了,请注意你实际环境中的值。
添加节点
先总结一下:
2023年的模拟环境中,是在后续插件(包管理器helm3、网络、CoreDNS等)安装完成后,再克隆出的node,然后添加节点,节点是不需要初始化控制平面的(kubeadm init)。
节点有两个部署思路:
- 控制平面节点(master)完成必要安装和配置后,包括网络插件,克隆出节点,确保UUID、MAC、IP、HOSTNAME的不同,在节点上执行kubeadm reset等重置操作,详见卸载集群笔记,再做为节点加入集群;
- 节点单独部署,参照控制平面节点的部署,安装好容器运行时,和kubeadm、kubelet、kubectl(kubeadm也是要安装的,官文中提到过所有主机上安装kubeadm),但节点系统不执行初始化控制平面,再部署好必要插件比如网络和存储插件,最后加入集群,(该方法暂未实践,网络插件和DNS插件均是以POD方式运行的);
2023年实际操作:
克隆出2台k8snode, 添加到Kubernetes集群中,分别做为k8snode002, k8snode003,在上面执行初始化时产生的“kubeadm join”指令(默认24小时内,超时后需要重新生成token)。
加入节点时报错:
error execution phase preflight: [preflight] Some fatal errors occurred:
[ERROR FileAvailable–etc-kubernetes-kubelet.conf]: /etc/kubernetes/kubelet.conf already exists
[ERROR Port-10250]: Port 10250 is in use
[ERROR FileAvailable–etc-kubernetes-pki-ca.crt]: /etc/kubernetes/pki/ca.crt already exists
参考:https://www.cnblogs.com/wangzy-Zj/p/13130877.html
重置后重新加入
sudo kubeadm reset 以及清理网络规则和config配置(参照卸载集群,但不要删除节点)
由此可知,节点是只需要部署好节点的组件即可。
再报错:could not find a JWS signature in the cluster-info ConfigMap for token ID “abcdef”
参考:https://www.cnblogs.com/dream397/p/14922802.html
原因:token 默认有效时间为24小时
处理:重新生成,且可设置ttl=0表示生成的 token 永不失效
kubeadm token create --print-join-command --ttl=0
sudo kubeadm join 192.168.130.88:6443 --token [token] --discovery-token-ca-cert-hash sha256:xxx --v=5
可在master节点上执行命令查看集群中的节点:
kubectl get node
重新配置 kubeadm 集群
官文:https://kubernetes.io/zh-cn/docs/tasks/administer-cluster/kubeadm/kubeadm-reconfigure/
要修改组件配置,你必须手动编辑磁盘上关联的集群对象和文件。
kubeadm 在 ConfigMap 和其他对象中写入了一组集群范围的组件配置选项。 这些对象必须手动编辑,可以使用命令 kubectl edit
kubectl edit 命令将打开一个文本编辑器,你可以在其中直接编辑和保存对象。 你可以使用环境变量 KUBECONFIG 和 KUBE_EDITOR 来指定 kubectl 使用的 kubeconfig 文件和首选文本编辑器的位置。
例如:
KUBECONFIG=/etc/kubernetes/admin.conf KUBE_EDITOR=nano kubectl edit
保存对这些集群对象的任何更改后,节点上运行的组件可能不会自动更新。 以下步骤将指导你如何手动执行该操作。
警告:
ConfigMaps 中的组件配置存储为非结构化数据(YAML 字符串)。 这意味着在更新 ConfigMap 的内容时不会执行验证。 你必须小心遵循特定组件配置的文档化 API 格式, 并避免引入拼写错误和 YAML 缩进错误。
应用集群配置更改
更新 ClusterConfiguration
官文:https://kubernetes.io/zh-cn/docs/tasks/administer-cluster/kubeadm/kubeadm-reconfigure/#%E6%9B%B4%E6%96%B0-clusterconfiguration
在集群创建和升级期间,kubeadm 将其 ClusterConfiguration 写入 kube-system 命名空间中名为 kubeadm-config 的 ConfigMap。
要更改 ClusterConfiguration 中的特定选项,你可以使用以下命令编辑 ConfigMap:
kubectl edit cm -n kube-system kubeadm-config
说明:
ClusterConfiguration 包括各种影响单个组件配置的选项, 例如 kube-apiserver、kube-scheduler、kube-controller-manager、 CoreDNS、etcd 和 kube-proxy。 对配置的更改必须手动反映在节点组件上。
在控制平面节点上反映 ClusterConfiguration 更改
kubeadm 将控制平面组件作为位于 /etc/kubernetes/manifests 目录中的静态 Pod 清单进行管理。 对 apiServer、controllerManager、scheduler 或 etcd键下的 ClusterConfiguration 的任何更改都必须反映在控制平面节点上清单目录中的关联文件中。
在继续进行这些更改之前,请确保你已备份目录 /etc/kubernetes/。
要编写新证书,你可以使用:
kubeadm init phase certs --config
要在 /etc/kubernetes/manifests 中编写新的清单文件,你可以使用:
kubeadm init phase control-plane --config
内容必须与更新后的 ClusterConfiguration 匹配。 值必须是组件的名称。
说明:
更新 /etc/kubernetes/manifests 中的文件将告诉 kubelet 重新启动相应组件的静态 Pod。 尝试一次对一个节点进行这些更改,以在不停机的情况下离开集群。
应用 kubelet 配置更改
kubectl edit cm -n kube-system kubelet-config
反映 kubelet 的更改
登录到 kubeadm 节点
运行 kubeadm upgrade node phase kubelet-config 下载最新的 kubelet-config ConfigMap 内容到本地文件 /var/lib/kubelet/config.conf
编辑文件 /var/lib/kubelet/kubeadm-flags.env 以使用标志来应用额外的配置,pause镜像和–container-runtime-endpoint便在这里面。
使用 systemctl restart kubelet 重启 kubelet 服务
说明:
一次执行一个节点的这些更改,以允许正确地重新安排工作负载。
应用 kube-proxy 配置更改
sudo kubectl edit cm -n kube-system kube-proxy
反映 kube-proxy 的更改
更新 kube-proxy ConfigMap 后,你可以重新启动所有 kube-proxy Pod:
获取 Pod 名称:
kubectl get po -n kube-system | grep kube-proxy
使用以下命令删除 Pod:
kubectl delete po -n kube-system
将创建使用更新的 ConfigMap 的新 Pod。
说明:
由于 kubeadm 将 kube-proxy 部署为 DaemonSet,因此不支持特定于节点的配置。
应用 CoreDNS 配置更改
kubeadm 将 CoreDNS 部署为名为 coredns 的 Deployment,并使用 Service kube-dns, 两者都在 kube-system 命名空间中。
要更新任何 CoreDNS 设置,你可以编辑 Deployment 和 Service:
kubectl edit deployment -n kube-system coredns
kubectl edit service -n kube-system kube-dns
反映 CoreDNS 的更改
应用 CoreDNS 更改后,你可以删除 CoreDNS Pod。
获取 Pod 名称:
kubectl get po -n kube-system | grep coredns
使用以下命令删除 Pod:
kubectl delete po -n kube-system
将创建具有更新的 CoreDNS 配置的新 Pod。
卸载集群
官文:https://kubernetes.io/zh-cn/docs/setup/production-environment/tools/kubeadm/create-cluster-kubeadm/#tear-down
技术同行:初始化失败? 运行:sudo kubeadm reset && rm -rf $HOME/.kube/config && rm -rf $HOME/.kube; 再执行初始化命令。
实践:没有清理iptables 规则或 IPVS 表,可能留下问题。
如果你在集群中使用了一次性服务器进行测试,则可以关闭这些服务器,而无需进一步清理。 你可以使用 kubectl config delete-cluster 删除对集群的本地引用。
但是,如果要更干净地取消配置集群, 则应首先清空节点并确保该节点为空, 然后取消配置该节点。
删除节点
使用适当的凭证与控制平面节点通信,驱逐pod,控制平面节点上运行:
kubectl drain --delete-emptydir-data --force --ignore-daemonsets
在删除节点之前,请重置 kubeadm 安装的状态,在要删除的节点上操作:
sudo kubeadm reset
重置过程不会重置或清除 iptables 规则或 IPVS 表。如果你希望重置 iptables,则必须手动进行(root用户):
sudo iptables -F && sudo iptables -t nat -F && sudo iptables -t mangle -F && sudo iptables -X
sudo iptables -vnL
如果要重置 IPVS 表,则必须运行以下命令:
sudo ipvsadm -C
sudo ipvsadm -ln # 查看结果
清理CNI配置
sudo rm -rf /etc/cni/net.d
现在删除节点,控制平面节点上运行:
kubectl delete node <节点名称>
如果是删除worker节点,此时可重新加入集群了。
清理控制平面
你可以在控制平面主机上使用 kubeadm reset 来触发尽力而为的清理。
sudo kubeadm reset && rm -rf $HOME/.kube/config && rm -rf $HOME/.kube
有关此子命令及其选项的更多信息,请参见 kubeadm reset 参考文档。
清除 iptables 规则或 IPVS 表,同删除节点的操作一样:
sudo iptables -F && sudo iptables -t nat -F && sudo iptables -t mangle -F && sudo iptables -X
sudo iptables -vnL
sudo ipvsadm -C
sudo ipvsadm -ln # 查看结果
如何安全地清空一个节点(扩展)
官文:https://kubernetes.io/zh-cn/docs/tasks/administer-cluster/safely-drain-node/
使用 kubectl drain 从服务中删除一个节点(操作后,一般要多等一会儿)
kubectl drain 的成功返回,表明所有的 Pod(除了上一段中描述的被排除的那些), 已经被安全地逐出(考虑到期望的终止宽限期和你定义的 PodDisruptionBudget)。 然后就可以安全地关闭节点, 比如关闭物理机器的电源,如果它运行在云平台上,则删除它的虚拟机。
说明:
如果存在新的、能够容忍 node.kubernetes.io/unschedulable 污点的 Pod, 那么这些 Pod 可能会被调度到你已经清空的节点上。 除了 DaemonSet 之外,请避免容忍此污点。
如果你或另一个 API 用户(绕过调度器)直接为 Pod 设置了 nodeName字段, 则即使你已将该节点清空并标记为不可调度,Pod 仍将被绑定到这个指定的节点并在该节点上运行。
首先,确定想要清空的节点的名称。可以用以下命令列出集群中的所有节点:
kubectl get nodes
接下来,告诉 Kubernetes 清空节点:
kubectl drain --ignore-daemonsets <节点名称>
如果存在 DaemonSet 管理的 Pod,你将需要为 kubectl 设置 --ignore-daemonsets 以成功地清空节点。 kubectl drain 子命令自身实际上不清空节点上的 DaemonSet Pod 集合: DaemonSet 控制器(作为控制平面的一部分)会立即用新的等效 Pod 替换缺少的 Pod。 DaemonSet 控制器还会创建忽略不可调度污点的 Pod,这种污点允许在你正在清空的节点上启动新的 Pod。
一旦它返回(没有报错), 你就可以下线此节点(或者等价地,如果在云平台上,删除支持该节点的虚拟机)。 如果要在维护操作期间将节点留在集群中,则需要运行:
kubectl uncordon
然后告诉 Kubernetes,它可以继续在此节点上调度新的 Pod。
并行清空多个节点
官文:https://kubernetes.io/zh-cn/docs/tasks/administer-cluster/safely-drain-node/#draining-multiple-nodes-in-parallel
状态的副本数量低于指定预算的清空操作都将被阻止。文章来源:https://www.toymoban.com/news/detail-784461.html
有关 kubeadm init 参数的更多信息
请参见 kubeadm 参考指南。https://kubernetes.io/zh-cn/docs/reference/setup-tools/kubeadm/
Kubeadm 是一个提供了 kubeadm init 和 kubeadm join 的工具, 作为创建 Kubernetes 集群的 “快捷途径” 的最佳实践。
kubeadm 通过执行必要的操作来启动和运行最小可用集群。 按照设计,它只关注启动引导,而非配置机器。同样的, 安装各种 “锦上添花” 的扩展,例如 Kubernetes Dashboard、 监控方案、以及特定云平台的扩展,都不在讨论范围内。
相反,我们希望在 kubeadm 之上构建更高级别以及更加合规的工具, 理想情况下,使用 kubeadm 作为所有部署工作的基准将会更加易于创建一致性集群。
kubeadm init 用于搭建控制平面节点
kubeadm join 用于搭建工作节点并将其加入到集群中
kubeadm upgrade 用于升级 Kubernetes 集群到新版本
kubeadm config 如果你使用了 v1.7.x 或更低版本的 kubeadm 版本初始化你的集群,则使用 kubeadm upgrade 来配置你的集群
kubeadm token 用于管理 kubeadm join 使用的令牌
kubeadm reset 用于恢复通过 kubeadm init 或者 kubeadm join 命令对节点进行的任何变更
kubeadm certs 用于管理 Kubernetes 证书
kubeadm kubeconfig 用于管理 kubeconfig 文件
kubeadm version 用于打印 kubeadm 的版本信息
kubeadm alpha 用于预览一组可用于收集社区反馈的特性文章来源地址https://www.toymoban.com/news/detail-784461.html
到了这里,关于基于Ubuntu22.04部署生产级K8S集群v1.27(规划和核心组件部署篇)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!