利用yolov5进行目标检测,并将检测到的目标裁剪出来
写在前面:关于yolov5的调试运行在这里不做过多赘述,有关yolov5的调试运行请看:https://www.bilibili.com/video/BV1tf4y1t7ru/spm_id_from=333.999.0.0&vd_source=043dc71f3eaf6a0ccb6dada9dbd8be37
本文章主要讲解的是裁剪。
需求:识别图片中的人物并将其裁剪出来
如果只需识别人物的话,那么只需在yolov5中设定参数即可,例如使用命令行运行时:python --classes 0
即为将参数设置为只识别人。此外需要将检测到的目标裁剪出来还需要目标的中心点坐标以及目标的宽高,因此需要保存目标的信息。实现人物检测并保存检测到的目标信息,运行命令为:python --classes0 --save-txt
在保存目标信息的tx文件中,例如下图:0 0.682078 0.495935 0.613014 0.99187,从左到右以此代表:目标类型(0代表person)、目标中心点坐标的x值(x_center),目标中心点坐标的y值(y_center),目标的宽度(width),目标的高度(height)。

要进行裁剪的条件是需要得到x1,x2,y1,y2。很显然
x1=x_center-width/2
x2=x_center+width/2
y1=y_center-height/2
y2=y_center+height/2
但是由于yolov5的txt文件中存储的x_center,y_center,width,height都是经过归一化处理的所以,上述公式中所计算得到的x1,x2,y1,y2值都是经过归一化处理之后的值,我们要的是原值,所以
x1=(x_center-width/2)*整张图片的宽度(注:是整张图片的宽度不是目标的宽度,这里的宽度就是像素宽度)
x2=(x_center+width/2)*整张图片的宽度
y1=(y_center-height/2)*整张图片的高度(注:是整张图片的高度不是目标的高度,这里的高度就是像素高度)
y2=(y_center+height/2)*整张图片的高度
得到了x1,x2,y1,y2四个值,那在水平方向上裁剪x1---->x2,在垂直方向上裁剪y1---->y2,即可。
代码实现:
import os
import cv2
def main():
#图片路径
img_path = './data/images/hg.jpg'
#txt文件路径
label_path = './runs/detect/exp23/labels/hg.txt'
# 读取图片,结果为三维数组
img = cv2.imread(img_path)
# 图片宽度(像素)
w = img.shape[1]
# 图片高度(像素)
h = img.shape[0]
# 打开文件,编码格式'utf-8','r+'读写
f = open(label_path, 'r+', encoding='utf-8')
# 读取txt文件中的第一行,数据类型str
line = f.readline()
# 根据空格切割字符串,最后得到的是一个list
msg = line.split(" ")
x1 = int((float(msg[1]) - float(msg[3]) / 2) * w) # x_center - width/2
y1 = int((float(msg[2]) - float(msg[4]) / 2) * h) # y_center - height/2
x2 = int((float(msg[1]) + float(msg[3]) / 2) * w) # x_center + width/2
y2 = int((float(msg[2]) + float(msg[4]) / 2) * h) # y_center + height/2
print(x1, ",", y1, ",", x2, ",", y2)
#裁剪
img_roi = img[y1:y2,x1:x2]
save_path='./cutpictures/hg.jpg'
cv2.imwrite(save_path,img_roi)
if __name__ == '__main__':
main()
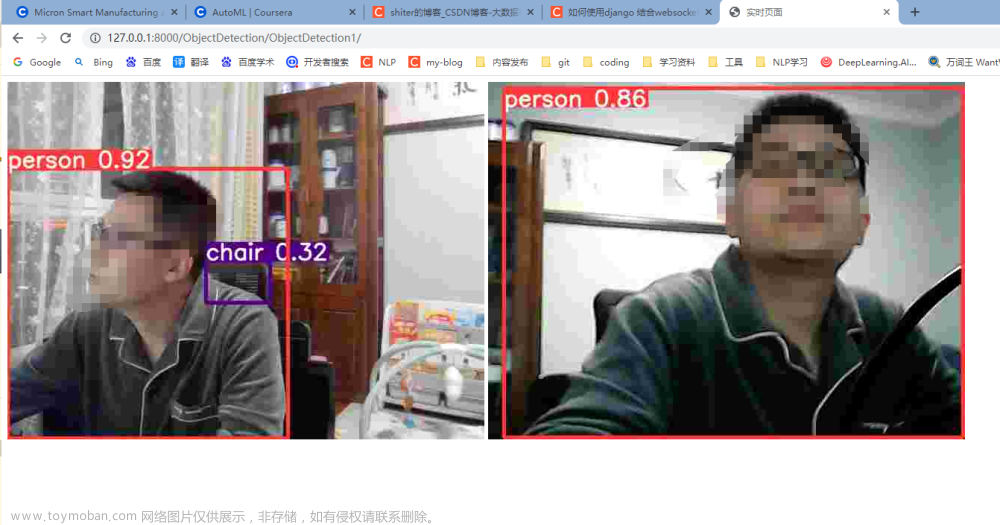
效果展示:
目标检测
裁剪
写在后面:在上面的代码实现中,因为我已经知道了在图片中只有一个person,所以txt文件中只有一行,所以我只用f.readlin()读取了一行,如果有多个目标person,那就用f.readlines()读取多行,再用for循环一行一行去裁剪即可。文章来源:https://www.toymoban.com/news/detail-784501.html
更正:在后续的操作中我想把图片中最远的人裁剪出来,也就是下图的红框,那只需比较y_center,把y_center最大的裁剪出来即可,按照此想法我裁剪出来的却是绿框。
后来验证发现yolov中的坐标系如下:
但是并不影响对上面相关过程的理解。文章来源地址https://www.toymoban.com/news/detail-784501.html
到了这里,关于利用yolov5进行目标检测,并将检测到的目标裁剪出来的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!