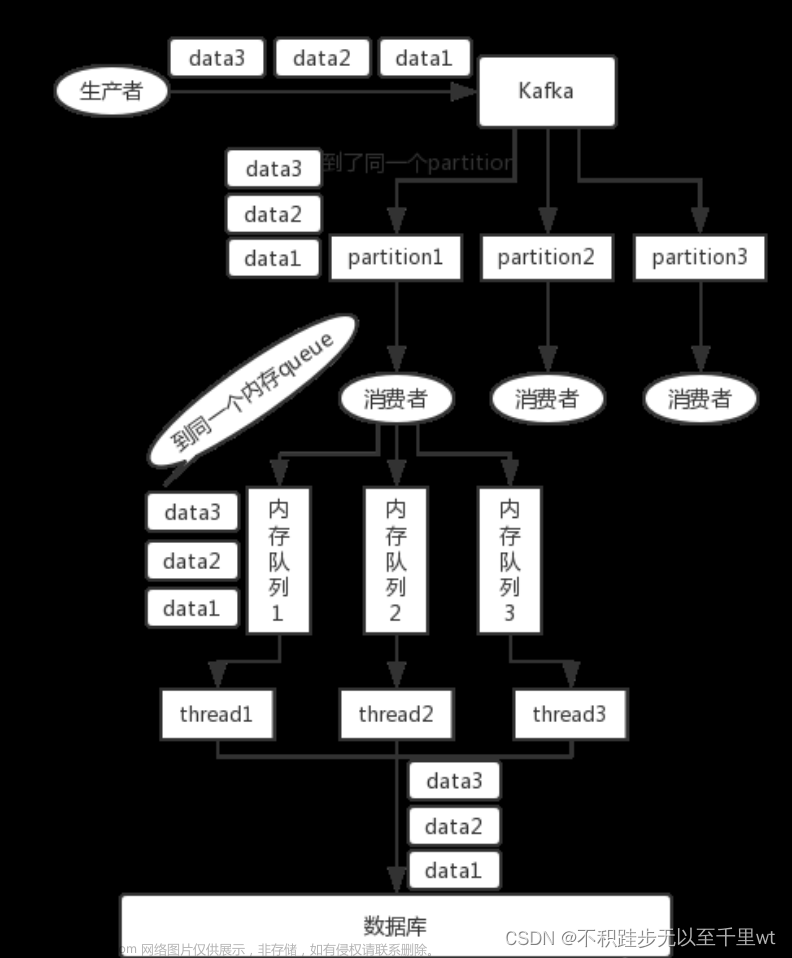
kafka 使用场景
- 监控 Metrics
- 网站活动追踪 Website Activity Tracking
- 日志收集 Log Aggregation
- 流处理 Stream Processing
- 事件溯源 Event Sourcing
- 提交日志 Commit Log
Kafka 基本概念
Broker
和AMQP里协议的概念一样, 就是消息中间件所在的服务器
Topic(主题)
每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic。(物理上不同Topic的消息分开存储,逻辑上一个Topic的消息虽然保存于一个或多个broker上但用户只需指定消息的Topic即可生产或消费数据而不必关心数据存于何处)
Partition(分区)
Partition是物理上的概念,体现在磁盘上面,每个Topic包含一个或多个Partition.
Producer
负责发布消息到Kafka broker
Consumer
消息消费者,向Kafka broker读取消息的客户端。
Consumer Group(消费者群组)
每个Consumer属于一个特定的Consumer Group(可为每个Consumer指定group name,若不指定group name则属于默认的group)。
offset 偏移量
是kafka用来确定消息是否被消费过的标识,在kafka内部体现就是一个递增的数字
kafka消息发送的时候 ,考虑到性能 可以采用打包方式发送, 也就是说 传统的消息是一条一条发送, 现在可以先把需要发送的消息缓存在客户端, 等到达一定数值时, 再一起打包发送, 而且还可以对发送的数据进行压缩处理,减少在数据传输时的开销
Linux 安装&启动 kafka
截止 2022.08.22 最新版是 3.3.1 官网下载 : https://kafka.apache.org/downloads
上传到服务器,解压文件
tar -zxvf kafka_2.13-3.3.1.tgz -C /usr/local/

修改核心配置文件
vim /usr/local/kafka_2.13-3.3.1/config/server.properties
- broker.id
集群环境中每台 kafka 都有唯一的 broker.id, 不能重复
broker.id 和 log日志中 meta.properties 中的 broker.id 一致 - log.dirs (消息存储路径)
log.dirs=/home/servers-kafka/logs/kafka
- zookeeper.connect (zookeeper连接池地址信息)
- host.name (主机名称,为本机IP地址)
- 修改 : listeners=PLATNTEXT://kafka服务器IP:9092
创建数据存放目录
mkdir -p /usr/local/kafka/kafka-logs
mkdir -p /usr/local/kafka/zookeeper-data
mkdir -p /usr/local/kafka/zookeeper-logs
最终配置
broker.id=1
log.dirs=/usr/local/kafka/kafka-logs
zookeeper.connect=139.55.22.212:2181
# 配置文件尾部追加以下内容
delete.topic.enable=true
host.name=139.55.22.21
启动
cd /usr/local/kafka/bin
# zookeeper守护线程启动 zookeeper
./zookeeper-server-start.sh -daemon ../config/zookeeper.properties
# kafka 守护线程启动 kafka
./kafka-server-start.sh -daemon ../config/server.properties
# 停止 kafka
./kafka-server-stop.sh
# 查看日志
cat /usr/local/kafka/logs/server.log
# kafka 根目录创建 Topic
cd /usr/local/kafka
bin/kafka-topics.sh --bootstrap-server localhost:9092 --create --topic campaign-logs --replication-factor 1 --partitions 4
# 查看 topic
# bin/kafka-configs.sh --bootstrap-server IP:端口 --describe --topic 主题名称
bin/kafka-topics.sh --bootstrap-server localhost:9015 --describe --topic campaign-logs
# 生产者发布消息
bin/kafka-console-producer.sh --bootstrap-server localhost:9015 --topic campaign-logs
# 消费者接受消息
bin/kafka-console-consumer.sh --bootstrap-server localhost:9015 --from-beginning --topic campaign-logs
验证 kafk 是否启动成功
jps

ps -ef | grep kafka

进程存在则启动成功
Topic (主题)
创建
topic命令时的警告 创建topic的时候,如果名称中包含. 或者_,kafka会抛出警告。原因是:
- 在Kafka的内部做埋点时会根据 topic 的名称来命名 metrics 的名称,并且会将句点号 . 改成下划线_。假设遇到一个topic 的名称为 topic.1_2,还有一个topic的名称为
topic_1.2,那么最后的metrics的名称都为topic_1_2,所以就会发生名称冲突。
命名规则
topic的命名不推荐(虽然可以这样做)使用双下划线__开头,
因为以双下划线开头的topic一般看作是kafka的内部topic,比如__consumer_offsets和__transaction_state。
topic的名称必须满足如下规则:
- 由大小写字母、数字、. 、- 、_组成
- 不能为空、不能为. 、不能为…
- 长度不能超过249
# kafka 根目录创建
cd /usr/local/kafka
bin/kafka-topics.sh --bootstrap-server localhost:9092 --create --topic campaign-logs --replication-factor 1 --partitions 4
# kafka bin目录创建
cd /usr/local/kafka/bin
./kafka-topics.sh --bootstrap-server localhost:9092 --create --topic campaign-logs --replication-factor 1 --partitions 4
注意事项
创建topic时,设置 replication-factor(topic副本)的数量不能多余启动的broker数量 kafka
版本不同,创建命令不同,可参考官网文档
官方文档:https://kafka.apache.org/documentation/#topicconfigs
查看
# bin/kafka-configs.sh --bootstrap-server IP:端口 --describe --topic 主题名称
bin/kafka-topics.sh --bootstrap-server localhost:9092 --describe --topic campaign-logs

生产者 (producer)
# 控制台启动生产者
bin/kafka-console-producer.sh --bootstrap-server localhost:9092 --topic campaign-logs
消费者 (consumer)
# 控制台启动消费者
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic campaign-logs
# 拓展配置
# 1. 获取全部消息
--from-beginning
异常记录
启动不成功时,查看服务日志:
cat /usr/local/kafka/logs/server.log
启动报错:Socket server failed to bind to ip:端口: Cannot assign requested address.

解决方案
修改 server.properties 调整监听地址配置
# 示例 listeners=PLAINTEXT://127.0.0.1:端口
listeners=PLAINTEXT://127.0.0.1:555
advertised.listeners=PLAINTEXT://127.0.0.1:666
composer 更新失败,依赖冲突

解决方案
conposer >>> require 新增配置, composer update --ignore-platform-reqs 安装组件
# 1. 单独配置后执行命令 composer update --ignore-platform-reqs 更新
"symfony/http-kernel": "v4.1.13",
# 2. 再配置 "laravel/lumen-framework":"5.7.*", 后行命令 composer update --ignore-platform-reqs 更新
"laravel/lumen-framework":"5.7.*",


Not has broker can connection metadataBrokerList 【没有broker可以连接metadataBrokerList】

原因解析
server.properties中有两个listeners。
- listeners:启动kafka服务监听的ip和端口,可以监听内网ip和0.0.0.0(不能为外网ip),默认为java.net.InetAddress.getCanonicalHostName()获取的ip。
- advertised.listeners:生产者和消费者连接的地址,kafka会把该地址注册到zookeeper中,所以只能为除0.0.0.0之外的合法ip或域名,默认和listeners的配置一致。
解决方案
修改server.properties
# ip可以内网、外网ip、127.0.0.1 或域名
advertised.listeners=PLAINTEXT://{ip}:9092
创建 Topic 时抛异常:zookeeper is not a recognized option
执行创建 topic 命令
# kafka 根路径创建
cd /usr/local/kafka
bin/kafka-topics.sh --create --zookeeper localhost:2181 --topic campaign_logs --replication-factor 2 --partitions 4

解决方案
执行 kafka 命令失败可能是kafka 版本问题,3.0版本的命令中无需指定 --zookeeper,创建 topic 命令:
# 通过 kafka-topics.sh 脚本创建一个名为 campaign-logs 并且副本数为2、分区数为4的topic
bin/kafka-topics.sh --bootstrap-server localhost:9092 --create --topic campaign-logs --replication-factor 2 --partitions 4
Replication factor: 2 larger than available brokers: 1.

原因分析
⚠️replication-factor(topic副本)个数不能超过broker(服务器)的个数。 如果 kafka 的
broker只有1个,而replication-factor 设置为2,所以会报错。
解决方案
创建topic时,设置 replication-factor(topic副本)的数量不能多余启动的broker数量。此时正确的创建命令为:
bin/kafka-topics.sh --bootstrap-server localhost:9092 --create --topic campaign-logs --replication-factor 1 --partitions 4
参考链接
Error while executing topic command : Replication factor: 2 larger than available brokers: 1.
Laravel 使用 kafka
composer.json >>> require 新增配置
"require": {
"laravel/lumen-framework": "5.7.*",
"symfony/http-kernel": "^4.1.13",
"nmred/kafka-php": "v0.2.0.8",
},

执行忽略版本匹配更新命令
composer update --ignore-platform-reqs

.env 文件新增kafka 配置
# kafka主题名称
KAFKA_TOPIC=campaign-logs
# kafka 地址 KAFKA_URL=IP:端口
KAFKA_URL=135.25.23.56:9092
kafka 服务类
<?php
/**
* Kafka 服务类
*
* @author Lee
* @date 2023.01.18 17:11
*/
namespace App\Services;
use Kafka\Producer;
use Kafka\ProducerConfig;
class KafkaService
{
public function __construct()
{
date_default_timezone_set('PRC');
}
/**
* 生产者
*
* @date 2023.01.18 17:13
* @param $topic
* @param $value
* @param $url
* @return void
*/
public function Producer($topic, $value , $url)
{
$config = ProducerConfig::getInstance();
$config->setMetadataRefreshIntervalMs(10000);
$config->setMetadataBrokerList($url);
$config->setBrokerVersion('1.0.0');
$config->setRequiredAck(1);
$config->setIsAsyn(false);
$config->setProduceInterval(500);
$producer = new Producer(function () use($value,$topic){
return [
[
'topic' => $topic,
'value' => $value,
'key' => '',
],
];
});
$producer->success(function ($result){
return "success";
});
$producer->error(function ($errorCode){
var_dump($errorCode);
});
$producer->send(true);
}
}
生产消息
/**
* 生产消息
*
* @date 2023.01.18 17:28
* @return void
*/
public static function produceMsg($data)
{
/**
* 配置在env中
*/
$topic = env('KAFKA_TOPIC');
$url = env('KAFKA_URL');
try {
$value = json_encode($data, JSON_FORCE_OBJECT);
KafkaService::producer($topic, $value, $url);
} catch (\Exception $e) {
dump($e);
}
}
计划任务消费消息
执行命令:php artisan consumeMsg文章来源:https://www.toymoban.com/news/detail-784823.html
<?php
/**
* Kafka 消费消息计划任务
*
* @author Lee
* @date 2023.01.20 12:17:36
*/
namespace App\Console\Commands;
use Illuminate\Console\Command;
class ConsumeMsg extends Command
{
/**
* The name and signature of the console command.
*
* @var string
*/
protected $signature = 'consumeMsg';
/**
* The console command description.
*
* @var string
*/
protected $description = 'Command description';
/**
* Create a new command instance.
*
* @return void
*/
public function __construct()
{
parent::__construct();
}
/**
* Execute the console command.
*
* @return mixed
*/
public function handle()
{
$this->log('开始监听消息...');
app('kafkaService')->consumer(
$topics = env('KAFKA_TOPIC'),
$url = env('KAFKA_URL')
);
return $this;
}
private function log($msg = '')
{
if (!$msg) {
return $this;
}
if (php_sapi_name() == 'cli') {
echo $msg, PHP_EOL;
}
file_put_contents("kafka.log", $msg);
return $this;
}
}
config/app.php 中注册 kafka 服务文章来源地址https://www.toymoban.com/news/detail-784823.html
'aliases' => [
'kafkaService' => App\Http\Service\KafkaService::class,
'consumerKafka' => App\Http\Service\ConsumerService::class
]
配置拓展(可选)
server.properties
# broker的全局唯一编号,不能重复
broker.id=1
# 监听链接的端口, producer或consumer将在此端口建立连接
port=9092
# kafka消息存放的路径
log.dirs=/home/servers-kafka/logs/kafka
# 处理网络请求的线程数量
num.network.threads=3
# 处理磁盘IO的线程数量
num.io.threads=8
# 发送套接字的缓冲区大小
socket.send.buffer.bytes=102400
# 接受套接字的缓冲区大小
socket.receive.buffer.bytes=102400
# 请求套接字的缓冲区大小
socket.request.max.bytes=104857600
# topic在当前broker上的分片个数
num.partitions=2
# 恢复和清理data下数据的线程数量
num.recovery.threads.per.data.dir=1
# segment文件保留的最长时间,超时将被删除
log.retention.hours=168
# 滚动生成新的segment文件的最大时间
log.roll.hours=168
# 日志文件中每个segment的大小,默认为1G
log.segment.bytes=1073741824
# 周期性检查文件大小的时间
log.retention.check.interval.ms=300000
# 日志清理是否打开
log.cleaner.enable=true
# broker需要使用zookeeper保存meta数据
zookeeper.connect=hadoop02:2181,hadoop03:2181,hadoop04:2181
# zookeeper 连接超时时间
zookeeper.connection.timeout.ms=6000
# partion buffer中,消息的条数达到阈值,将触发flush到磁盘
log.flush.interval.messages=10000
# 消息buffer的时间,达到阈值,将触发flush到磁盘
log.flush.interval.ms=3000
# 删除topic需要server.properties中设置delete.topic.enable=true否则只是标记删除
delete.topic.enable=true
# host.name为本机IP(重要),
# 如果不改,则客户端会抛出:Producerconnection to localhost:9092 unsuccessful 错误!
host.name=本机IP
producer.properties
# 指定kafka节点列表, 用于获取metadata,不必全部指定
metadata.broker.list=hadoop02:9092,hadoop03:9092
# 指定分区处理类。默认kafka.producer.DefaultPartitioner,表通过key哈希到对应分区
# partitioner.class=kafka.producer.DefaultPartitioner
# 是否压缩,默认0表示不压缩,1表示用gzip压缩,2表示用snappy压缩,压缩后消息中会有头来指明消息压缩类型,故在消费者端消息解压是透明的无需指定
compression.codec=none
# 指定序列化处理类
serializer.class=kafka.serializer.DefaultEncoder
# 如果要压缩消息,这里指定哪些topic要压缩消息,默认empty,表示不压缩。
#compressed.topics=
# 设置发送数据是否需要服务端的反馈,有三个值0,1,-1
# 0: producer不会等待broker发送ack
# 1: 当leader接收到消息之后发送ack
# -1: 当所有的follower都同步消息成功后发送ack.
request.required.acks=0
# 在向producer发送ack之前,broker允许等待的最大时间
# 如果超时,broker将会向producer发送一个error ACK.意味着上一次消息因为某种原因未能成功(比如follower未能同步成功)
request.timeout.ms=10000
# 同步还是异步发送消息,默认“sync”表同步,"async"表异步。
# 异步可以提高发送吞吐量,也意味着消息将会在本地buffer中,并适时批量发送,但是也可能导致丢失未发送过去的消息
producer.type=sync
# 在async模式下,当message被缓存的时间超过此值后,将会批量发送给broker,默认为5000ms
# 此值和batch.num.messages协同工作.
queue.buffering.max.ms = 5000
# 在async模式下,producer端允许buffer的最大消息量
# 无论如何,producer都无法尽快的将消息发送给broker,从而导致消息在producer端大量沉积
# 此时,如果消息的条数达到阀值,将会导致producer端阻塞或者消息被抛弃,默认为10000
queue.buffering.max.messages=20000
# 如果是异步,指定每次批量发送数据量,默认为200
batch.num.messages=500
# 当消息在producer端沉积的条数达到"queue.buffering.max.meesages"后
# 阻塞一定时间后,队列仍然没有enqueue(producer仍然没有发送出任何消息)
# 此时producer可以继续阻塞或者将消息抛弃,此timeout值用于控制"阻塞"的时间
# -1: 无阻塞超时限制,消息不会被抛弃
# 0:立即清空队列,消息被抛弃
queue.enqueue.timeout.ms=-1
# 当producer接收到error ACK,或者没有接收到ACK时,允许消息重发的次数
# 因为broker并没有完整的机制来避免消息重复,所以当网络异常时(比如ACK丢失)
# 有可能导致broker接收到重复的消息,默认值为3.
message.send.max.retries=3
# producer刷新topicmetada的时间间隔,producer需要知道partitionleader的位置,以及当前topic的情况
# 因此producer需要一个机制来获取最新的metadata,当producer遇到特定错误时,将会立即刷新
#(比如topic失效,partition丢失,leader失效等),此外也可以通过此参数来配置额外的刷新机制,默认值600000
topic.metadata.refresh.interval.ms=60000
consumer.properties
# zookeeper连接服务器地址
zookeeper.connect=hadoop02:2181,hadoop03:2181,hadoop04:2181
# zookeeper的session过期时间,默认5000ms,用于检测消费者是否挂掉
zookeeper.session.timeout.ms=5000
#当消费者挂掉,其他消费者要等该指定时间才能检查到并且触发重新负载均衡
zookeeper.connection.timeout.ms=10000
# 指定多久消费者更新offset到zookeeper中。注意offset更新时基于time而不是每次获得的消息。一旦在更新zookeeper发生异常并重启,将可能拿到已拿到过的消息
zookeeper.sync.time.ms=2000
#指定消费组
group.id=xxx
# 当consumer消费一定量的消息之后,将会自动向zookeeper提交offset信息
# 注意offset信息并不是每消费一次消息就向zk提交一次,而是现在本地保存(内存),并定期提交,默认为true
auto.commit.enable=true
# 自动更新时间。默认60 * 1000
auto.commit.interval.ms=1000
# 当前consumer的标识,可以设定,也可以有系统生成,主要用来跟踪消息消费情况,便于观察
conusmer.id=xxx
# 消费者客户端编号,用于区分不同客户端,默认客户端程序自动产生
client.id=xxxx
# 最大取多少块缓存到消费者(默认10)
queued.max.message.chunks=50
# 当有新的consumer加入到group时,将会reblance,此后将会有partitions的消费端迁移到新 的consumer上,
# 如果一个consumer获得了某个partition的消费权限,那么它将会向zk注册"Partition Owner registry"节点信息,
# 但是有可能此时旧的consumer尚没有释放此节点, 此值用于控制,注册节点的重试次数.
rebalance.max.retries=5
# 获取消息的最大尺寸,broker不会像consumer输出大于此值的消息chunk 每次feth将得到多条消息,此值为总大小,提升此值,将会消耗更多的consumer端内存
fetch.min.bytes=6553600
# 当消息的尺寸不足时,server阻塞的时间,如果超时,消息将立即发送给consumer
fetch.wait.max.ms=5000
socket.receive.buffer.bytes=655360
# 如果zookeeper没有offset值或offset值超出范围。那么就给个初始的offset。有smallest、largest、anything可选,分别表示给当前最小的offset、当前最大的offset、抛异常。默认largest
auto.offset.reset=smallest
# 指定序列化处理类
derializer.class=kafka.serializer.DefaultDecoder
参考文献
- 这是最详细的Kafka应用教程
- 一文读懂|Kafka 开发基础
- 四种消息中间件分析介绍(ActiveMQ、RabbitMQ、RocketMQ、Kafka
- kafka无法启动,Cannot assign requested address.
- 字节面试官: 让你设计一个MQ每秒要抗几十万并发,怎么做?
- Laravel 中 Kafka 的使用详解
- Laravel 实现 Kafka 消息推送与接收处理
- 基于 Laravel 构建的速度最快的微框架(micro-framework)
- 详解Laravel中Kafka的使用实例是什么样的
- Lumen 中文文档
- 30个Kafka常见错误小集合
到了这里,关于Linux部署Kafka及常见问题记录的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!