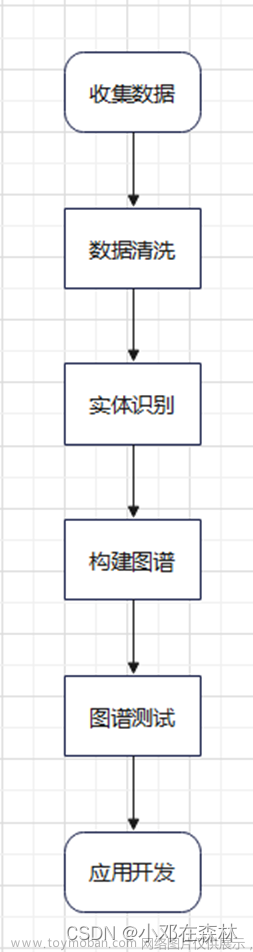
目录
知识图谱的前置介绍
什么是知识图谱
知识图谱概念由来
知识图谱总体架构
常用的获取知识的方法
网络爬虫
wikidata
知识图谱模型设计
设计方法论
UMLS语义网络
知识图谱模型设计之归纳法
模型设计流程
产品生命周期模型
高层抽象可复用
底层明细需适配
开源框架NLP 框架
NER发展历程
NER常用框架
图数据库解决方案
图数据库前端可视化
可用框架和效果
后端代码
前端代码
推荐系统介绍
知识图谱和推荐系统相结合
三种融合方式
三种训练模式
RippleNet工作原理和实现机制
相关资料
知识图谱的前置介绍
什么是知识图谱
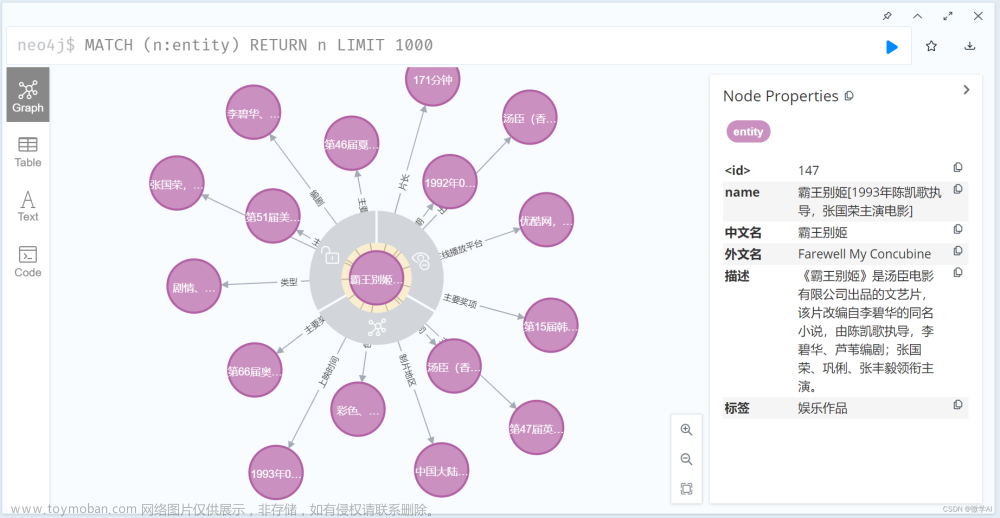
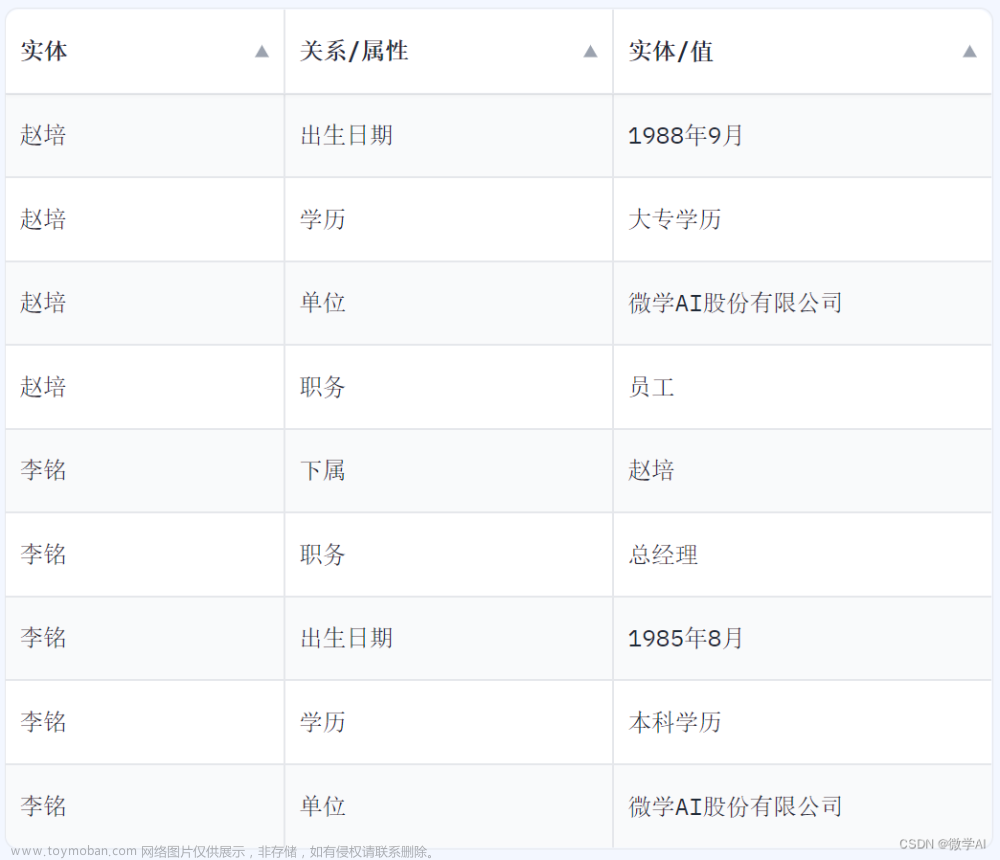
知识图谱本质(Knowledge Graph)上是一种叫做语义网络(semantic network ) 的知识库,即具有有向图结构的一个知识库;图的结点代表实体(entity)或者概念(concept),而图的边代表实体/概念之间的各种语义关系,比如说两个实体之间的相似关系;知识图谱旨在描述真实世界中存在的各种实体或概念及其关系,一般用三元组表示;
知识图谱概念由来
知识图谱(Knowledge Graph )的概念由谷歌 2012 年正式提出,旨在实现更智能的搜索引擎,并且于 2013 年以后开始在学术界和业界普及,并在智能问答、情报分析、反欺诈等应用中发挥重要作用。
知识图谱总体架构

常用的获取知识的方法
网络爬虫

Schema.org 是一个协作、社区活动,由搜索引擎巨头 Google、Microsoft、Yahoo 和 Yandex 发起,旨在创建、维护和推广一套共同的、通用的数据标记模式(schemas),这些模式可以被搜索引擎和其他web爬虫理解。该项目的目的是为了改善互联网中信息的结构化表示,以便搜索引擎能够更好地理解网页内容,并据此提供更丰富和更精确的搜索结果。
Schema.org 提供的这些模式涵盖了各种实体类型,如人、地点、事件、产品和许多其他内容类型,以及这些实体之间的关系。这些模式通常以JSON-LD、Microdata或RDFa的形式嵌入到网页HTML中,提供了一种方式来注释网页元素,使其含义对机器更加清晰。
<article itemscope itemtype="http://schema.org/Article">
<header>
<h1 itemprop="headline">如何使用Schema.org</h1>
<p>作者:<span itemprop="author">张三</span></p>
<time itemprop="datePublished" datetime="2021-04-01">2021年4月1日</time>
</header>
<section itemprop="articleBody">
<p>这篇文章介绍了Schema.org的基本用法...</p>
</section>
</article>
wikidata
wikidata一个免费的、开放的、可编辑的知识库,它可以为维基百科和其他维基媒体基金会的项目,以及任何人使用的外部应用程序,提供结构化的数据。Wikidata 旨在成为一个中央存储库,为所有维基百科语言版本和其他维基媒体基金会的知识项目提供公共数据。
在Wikidata上,数据以项(items)和声明(statements)的形式组织。每个项都代表一个概念或实体(如人、地点、概念、事件等),并且有一个独一无二的标识符(称为QID)。声明则用于描述一个项的性质,包括与其他项的关系、属性特征等。
知识图谱模型设计
设计方法论

UMLS语义网络
UMLS(统一医学语言系统,Unified Medical Language System)是美国国家医学图书馆(National Library of Medicine)建立的医学领域的一种广为接受的知识表示(knowledge representation)标准。UMLS旨在通过标准化大量医学和健康术语,以达成映射多种医学词汇体系的目标,使得不同的医学系统能够通信,并且能够更清晰地理解了各种种类的健康和生物医学代码和术语。
UMLS主要由以下三部分组成:
-
Meta-thesaurus(元词表):这部分是 UMLS 的核心,包含来自不同来源的医学术语、疾病描述、药物信息等,并关联着多个不同医学词汇体系中的术语。元词表提供统一标识符(UMLS Concept Unique Identifiers, CUIs)来整合各种术语和概念,并显示它们之间的关系。
-
Semantic Network(语义网络):它为术语和概念建立了一个大范围的分类框架,语义网络包含了广泛的、经过分层的、医学概念类别和类别间关系的定义。每个概念都被分配到一个或多个语义类型,像药物、疾病或医疗设备等,而语义类型之间也定义了多种可能的语义关系,比如"治疗"或"致病"。
- SPECIALIST Lexicon and Lexical Tools(专家词汇及查词工具):这是一个包含很多与医学相关期名词与单词的大型英语词汇库。结合一组用来解析和构造自然语言的软件工具。专家词库针对生物医疗领域进行了优化,支持文字处理和自然语言理解任务比如段落、句法分析和词形变换。
UMLS 实际上可以视作一种健康医疗领域的知识图谱,汽车行业的知识图谱可以参考对标UMLS,因为它组织了大量的医疗术语、概念及它们之间的关联。


知识图谱模型设计之归纳法
模型设计流程

产品生命周期模型

高层抽象可复用

底层明细需适配



开源框架NLP 框架
NER发展历程

自然语言处理(NLP)中命名实体识别(NER)技术的一个发展历程图。命名实体识别是用来查找输入文本中的指定类别(如人名、地点、组织等)的技术。
NER常用框架
Stanford CoreNLP是一套自然语言处理工具,可以用来进行命名实体识别(NER)。以下是一个使用Java编写的简单示例代码,展示如何使用CoreNLP进行命名实体识别:
import edu.stanford.nlp.pipeline.*;
import edu.stanford.nlp.ling.*;
import edu.stanford.nlp.util.*;
import java.util.*;
public class CoreNLPExample {
public static void main(String[] args) {
// 创建一个StanfordCoreNLP对象,指定要使用的annotators
Properties props = new Properties();
props.setProperty("annotators", "tokenize,ssplit,pos,lemma,ner");
StanfordCoreNLP pipeline = new StanfordCoreNLP(props);
// 要处理的文本
String text = "Barack Obama was born in Hawaii. He is the president of the United States.";
// 创建一个空的Annotation对象
Annotation document = new Annotation(text);
// 运行所有的Annotators在这个文本上
pipeline.annotate(document);
// 从文本中提取所有的句子
List<CoreMap> sentences = document.get(CoreAnnotations.SentencesAnnotation.class);
for(CoreMap sentence: sentences) {
// 遍历所有的句子
for (CoreLabel token: sentence.get(CoreAnnotations.TokensAnnotation.class)) {
// 从token中获取各种属性
String word = token.get(CoreAnnotations.TextAnnotation.class);
String pos = token.get(CoreAnnotations.PartOfSpeechAnnotation.class);
String ne = token.get(CoreAnnotations.NamedEntityTagAnnotation.class);
System.out.println(String.format("Print: word: [%s] pos: [%s] ne: [%s]", word, pos, ne));
}
}
}
}
- 首先创建了一个
StanfordCoreNLP对象,并配置了要使用的一系列annotators。这些annotators包括tokenize(分词),ssplit(句子分割),pos(词性标注),lemma(词形还原),ner(命名实体识别)。- 然后,我们创建了一个
Annotation对象,它将存储我们要处理的文本。我们调用pipeline.annotate(document)来执行注解过程。- 之后,我们获取并遍历文本中的句子和单词标记(tokens),对每个标记,我们提取并打印出词汇、词性和命名实体的标签。
请注意,要运行此代码,您需要在您的项目中包含Stanford CoreNLP库的相关JAR文件。您可以从Stanford CoreNLP的官方网站下载这些库。此外,这段代码使用Java编写,如果你希望使用Python或其他语言进行NER,您可能需要使用相应的库(如StanfordNLP的Python接口或spaCy等)。
图数据库解决方案


图数据库前端可视化
可用框架和效果
Apache ECharts
D3 by Observable | The JavaScript library for bespoke data visualization

后端代码
# 实体查询
def search_entity(request):
ctx = {}
# 根据传入的实体名称搜索出关系
if(request.GET):
entity = request.GET['user_text']
# 连接数据库
db = neo4jconn
entityRelation = db.getEntityRelationbyEntity(entity)
if len(entityRelation) == 0:
# 若数据库中无法找到该实体,则返回数据库中无该实体
ctx= {'title' : '<h2>数据库中暂未添加该实体</h1>'}
return render(request,'entity.html'.encode("utf-8"),{'ctx':json.dumps(ctx,ensure_ascii=False)})
else:
# 返回查询结果
# 将查询结果按照"关系出现次数"的统计结果进行排序
entityRelation = sortDict(entityRelation)
return render(request,'entity.html'.encode("utf-8"),{'entityRelation':json.dumps(entityRelation,ensure_ascii=False)})
# 需要进行类型转换
return render(request,"entity.html",{'ctx':ctx})前端代码
示例中使用echart
#实体查询
def getEntityRelationbyEntity(self,value):
#查询实体:不考虑实体类型,只考虑关系方向
answer = self.graph.run("MATCH (entity1) - [rel] -> (entity2) WHERE entity1.name = \"" + value + "\" RETURN rel,entity2").data()
if(len(answer) == 0):
#查询实体:不考虑关系方向
answer = self.graph.run("MATCH (entity1) - [rel] - (entity2) WHERE entity1.name = \"" + value + " \" RETURN rel,entity2").data()
print(answer)
return answer{% extends "navigate.html" %} {% block mainbody %}
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8"/>
<title></title>
<meta charset="utf-8" />
<script src="/static/js/echarts.common.min.js"></script>
<script type="text/javascript" src="http://echarts.baidu.com/gallery/vendors/echarts/echarts-all-3.js"></script>
</head>
<title>实体查询</title>
<div class="container">
<div class="row">
<!--head start-->
<div class="col-md-12">
<h3 class="page-header"><i class="fa fa-share-alt" aria-hidden="true"></i> 实体查询 </h3>
<ol class="breadcrumb">
<li><i class="fa fa-home"></i><a href="\">Home</a></li>
<li><i class="fa fa-share-alt" aria-hidden="true"></i>实体查询</li>
</ol>
</div>
<div class = "col-md-12">
<div class="panel panel-default ">
<header class = "panel-heading">
查询条件:
</header>
<div class = "panel-body">
<!--搜索框-->
<form method = "get" id = 'searchEntityForm'>
<div >
<div class="input-group">
<input type="text" id = "user_text" name = "user_text" class="form-control" placeholder="输入实体名称" aria-describedby="basic-addon1">
<span class="btn btn-primary input-group-addon" type="button" id="relationSearchButton" style="background-color:#4592fe ; padding:6px 38px" onclick="document.getElementById('searchEntityForm').submit();">查询</span>
</div>
</div>
</form>
</div>
</div>
</div>
<p>
<div class = "col-md-12">
{% if ctx %}
<div class="panel panel-default">
<header class ="panel-heading">
<div class = "panel-body">
<h2>数据库中暂未添加该实体</h2>
</div>
</header>
</div>
{% endif %}
</div>
</p>
<!--实体关系查询-->
{% if entityRelation %}
<!-- Echart Dom对象(实体关系) -->
<div class = "col-md-12">
<div class="panel panel-default ">
<header class="panel-heading">
关系图 :
</header>
<div class = "panel-body ">
<div id="graph" style="width: 90%;height:600px;"></div>
</div>
</div>
</div>
{% endif %}
{% if entityRelation %}
<div class = "col-md-12">
<div class="panel panel-default">
<header class="panel-heading">
关系列表 :
</header>
<div class = "panel-body">
<table class = "table" data-paging = "true" data-sorting="true"></table>
</div>
</div>
</div>
{% endif %}
</div>
</div>
{% if entityRelation %}
<script src="/static/js/jquery.min.js"></script>
<script type="text/javascript">
// 基于查询结果:初始化Data和Links列表,用于Echarts可视化输出
var ctx = [ {{ ctx|safe }} ] ;
//{entity2,rel}
var entityRelation = [ {{ entityRelation|safe }} ] ;
var data = [] ;
var links = [] ;
if(ctx.length == 0){
var node = {} ;
var url = decodeURI(location.search) ;
var str = "";
if(url.indexOf("?") != -1){
str = url.split("=")[1]
}
//实体1:待查询的对象
node['name'] = str;
node['draggable'] = true ;
var id = 0;
node['id'] = id.toString() ;
data.push(node) ;
//实体2:查询并转储到data中,取二者较小的值
var maxDisPlayNode = 25 ;
for( var i = 0 ;i < Math.min(maxDisPlayNode,entityRelation[0].length) ; i++ ){
node = {} ;
node['name'] = entityRelation[0][i]['entity2']['name'] ;
node['draggable'] = true ; //是否允许拖拽
//是否URL:区分类型
if('url' in entityRelation[0][i]['entity2']){
node['category'] = 1 ;
}
else{
node['category'] = 2 ;
}
id = i + 1
node['id'] = id.toString();
var flag = 1 ;
relationTarget = id.toString() ;
for(var j = 0 ; j<data.length ;j++){
if(data[j]['name'] === node['name']){
flag = 0 ;
relationTarget = data[j]['id'] ;
break ;
}
}
relation = {}
relation['source'] = 0 ;
relation['target'] = relationTarget ;
relation['category'] = 0 ;
if(flag === 1){
data.push(node) ;
relation['value'] = entityRelation[0][i]['rel']['type'] ;
relation['symbolSize'] = 10
links.push(relation) ;
}
else{
maxDisPlayNode += 1 ;
for(var j = 0; j<links.length ;j++){
if(links[j]['target'] === relationTarget){
links[j]['value'] = links[j]['value']+" | "+entityRelation[0][i]['rel']['type']
break ;
}
}
}
}
//基于表格的展示++
tableData = []
for (var i = 0 ; i < entityRelation[0].length ; i++){
relationData = {} ;
relationData['entity1'] = str ;
relationData['relation'] = entityRelation[0][i]['rel']['type'] ;
relationData['entity2'] = entityRelation[0][i]['entity2']['name'] ;
tableData.push(relationData) ;
}
jQuery(function(){
$('.table').footable({
"columns": [{"name":"entity1",title:"Entity1"} ,
{"name":"relation",title:"Relation"},
{"name":"entity2",title:"Entity2"}],
"rows": tableData
});
});
//基于表格的展示--
}
// 基于准备好的数据:Data和Links,设置Echarts参数
var myChart = echarts.init(document.getElementById('graph'));
option = {
title: {
text: ''
}, //标题
tooltip: {}, //提示框配置
animationDurationUpdate: 1500,
animationEasingUpdate: 'quinticInOut',
label: {
normal: {
show: true,
textStyle: {
fontSize: 12
},
}
}, //节点上的标签
legend: {
x: "center",
show: false
},
series: [
{
type: 'graph', //系列:
layout: 'force',
symbolSize: 45,
focusNodeAdjacency: true,
roam: true,
edgeSymbol: ['none', 'arrow'],
categories: [{
name: 'Bank',
itemStyle: {
normal: {
color: "#009800",
}
}
}, {
name: 'Serise',
itemStyle: {
normal: {
color: "#4592FF",
}
}
}, {
name: 'Instance',
itemStyle: {
normal: {
color: "#C71585",
}
}
}],
label: {
normal: {
show: true,
textStyle: {
fontSize: 12,
},
}
}, //节点标签样式
force: {
repulsion: 1000
},
edgeSymbolSize: [4, 50],
edgeLabel: {
normal: {
show: true,
textStyle: {
fontSize: 10
},
formatter: "{c}"
}
}, //边标签样式
data: data, //节点
links: links, //节点间的关系
lineStyle: {
normal: {
opacity: 0.9,
width: 1.3,
curveness: 0,
color:"#262626"
}
} // 连接线的风格
}
]
};
myChart.setOption(option);
</script>
{% endif %}
{% endblock %}
推荐系统介绍



更多学习教程可以参考这个项目
知识图谱和推荐系统相结合
知识图谱与推荐系统的融合,可以提升推荐内容的准确性和效果。
三种融合方式
-
基于实体属性的推荐:利用知识图谱中实体的属性信息来推荐内容,例如,根据用户的兴趣属性推荐相关的内容。
-
基于实体关系的推荐:通过分析知识图谱中实体间的关系,如朋友关系、喜好关系等,来推荐用户可能感兴趣的内容。
-
基于知识图谱特征向量的推荐:使用知识图谱中实体的特征向量来生成推荐,这些向量可以捕捉实体的深层次特征,从而提高推荐的个性化程度。
三种训练模式
- 一次训练:在推荐系统中直接使用知识图谱数据进行训练。
- 联合训练:同时训练推荐系统和知识图谱模型,使它们共享知识。
- 交替训练:先训练推荐系统,然后使用其输出来更新知识图谱,再反过来用更新后的知识图谱来训练推荐系统。

RippleNet工作原理和实现机制
RippleNet是一个结合了知识图谱和推荐系统的框架,旨在通过利用知识图谱中的结构化事实来增强推荐系统的效果。在这个框架中,知识图谱的每个实体(如电影、演员、导演)和关系(如"演员参演电影")被用来丰富用户和物品的表示。

下面是RippleNet的工作原理和实现机制的简要说明:

输入:
- 用户u:用户的唯一标识。
- 物品v(例如,推荐系统中的电影或商品):物品的唯一标识。
- 用户点击历史Vu:用户过去的行为记录,如用户点击或购买的物品列表。
知识图谱:
- 知识图谱包含大量的事实,这些事实以三元组(头实体h,关系r,尾实体t)的形式表示
种子:
- 用户历史中的每个物品都被视为传播的种子点。这些种子点在知识图谱中被激活,从而影响与用户历史相关的其他实体。
传播(Propagation):
- RippleNet通过多个跳数(Hop)对知识图谱进行传播,每一跳都会从当前实体扩散到与之关联的实体,这些实体集合称为"波纹集"(Ripple Set)。
- 每个跳数可以看作是一层网络,每一层都会收集与上一层相关的实体和关系。
波纹集的影响:
- 用户的嵌入向量(User Embedding)受到波纹集影响,这些集合包含了用户兴趣的上下文信息。
- 例如,如果用户点击了某部电影,那么与这部电影相关的导演、演员等实体就会影响用户的表示。
加权平均与Softmax:
- 每个波纹集会对应一个潜在的用户兴趣表示,这些表示通过加权平均得到用户的最终嵌入。
- Softmax函数用于将加权后的用户嵌入向量转换为与特定物品相关联的预测概率。
预测:
- 用户嵌入和物品嵌入(Item Embedding)被送入神经网络中进行计算,输出用户点击给定物品的预测概率。
- 最终,预测概率被用于生成推荐列表,优先推荐那些具有较高点击概率的物品。
简而言之,RippleNet利用知识图谱中的关系网络来富化用户和物品的表示,使得推荐结果能够更加准确地反映用户的潜在兴趣。通过跳数(Hop)不断传播,它能够考虑到用户历史行为的多个层面,从而实现更深层次的个性化推荐。
相关资料
知识图谱+推荐系统 RippleNet:论文解读+代码 - 知乎
OpenKG.CN – 开放的中文知识图谱
The Stanford Natural Language Processing Group文章来源:https://www.toymoban.com/news/detail-785018.html
https://nlp.stanford.edu/pubs/2015angeli-openie.pdf文章来源地址https://www.toymoban.com/news/detail-785018.html
到了这里,关于知识图谱之汽车实战案例综述与前瞻分析的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!