m
在本教程中,我们将学习如何使用python中的mediapipe库进行实时3D骨架检测。
首先,我们得用pip下载下来我们需要用到的模组:
pip install mediapipe
这个工具不仅得到了谷歌的支持,而且Mediapipe中的模型也被积极地用于谷歌产品中。因此,这个模组,超级牛皮。
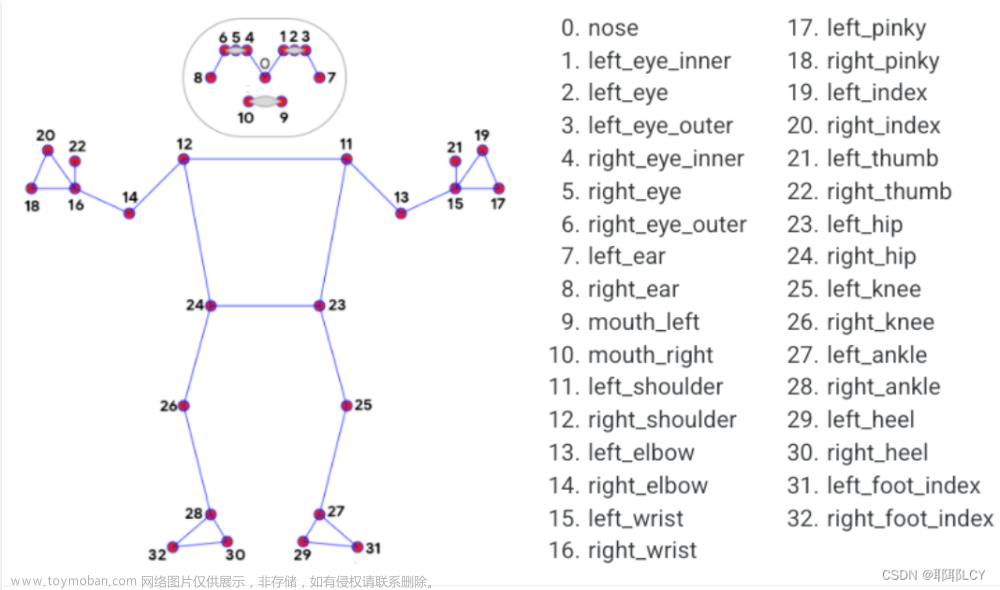
现在,MediaPipe的姿势检测是高保真(高质量)和低延迟(超快)的最先进的解决方案,用于在低端设备(即手机,笔记本电脑等)的实时视频源中检测一个人的33个3D地标。
pip install opencv-pythonOpencv-python简称cv2, 是一个超级牛皮的模组(比mediapipe还牛皮),他可以打开你的摄像头,并且还能回去每一帧的图像并显示出来(详情请见opencv的教程),关键是,cv2还有C++和Java版的。
pip install numpyNumpy, 为矩阵计算而生,是一个专门计算矩阵的模组,cv2会用到它。
pip install vpython大家应该不是那么的熟悉这个模组,用来在3D中布点的。但是因为简洁且迅速的更新速度,让我选择了这个模组(主要是因为害怕会掉帧)
P.S python需要定在python 3.0 以上
接下来,就是骨架预测的操作。
首先,导入所有我们需要的模组:
import cv2
import mediapipe as mp
from vpython import *然后来了解一下mediapipe里骨架预测模块的初始化:
import cv2
import mediapipe as mp
from vpython import *
mp_pose = mp.solutions.pose #从mediapipe里面获取pose
pose = mp_pose.Pose(static_image_mode=False, min_detection_confidence=0.5, model_complexity=1) #初始化Static_image_mode -这是一个布尔值,如果设置为False,检测器只在需要时调用,在第一帧或当跟踪器丢失跟踪时。如果设置为True,则对每个输入图像调用人员检测器。当你处理一堆不相关的图像而不是视频时,你应该把这个设为True。默认值为False。
Min_detection_confidence—考虑骨架检测模型的预测正确性所需的最小检测置信范围(0.0,1.0)。默认值为0.5。这意味着如果一个检测器的预测置信度大于或等于50%,则被认为是阳性的。
Min_tracking_confidence -这是骨架关节点跟踪模型为了有效跟踪地标的姿态,需要考虑的最小跟踪置信度([0.0,1.0])。如果置信度小于设定值,则在下一帧/图像中再次调用检测器,因此增加其值会增加稳定性,但也会造成延迟。默认值为0.5。
Model_complexity—骨架检测模型的复杂性。由于有三种不同的模型可供选择,可能的值为0、1或2。值越高,结果越准确,但代价是延迟越长。缺省值为1。
Smooth_landmarks -这是一个布尔值,如果设置为True,将过滤不同帧的骨架关节点以减少噪音。只有当static_image_mode也设置为False时,这才有效。默认值为True。
mp_drawing = mp.solutions.drawing_utilsmp_drawing 是为了可视化关节点于它们之间的关系初始化的
然后,咱们来搞一下摄像头的初始化:
cam = cv2.VideoCapture(0) #开启摄像头
while True:
_, frame = cam.read() #获取每一帧
cv2.imshow('real time', frame) #显示每一帧
if cv2.waitKey(1) == ord(q): #检查是否按下q键
break
cam.release() #关掉摄像头
cv2.destroyAllWindows() #关掉窗口
到现在为止,你的代码应该是这样的:
import cv2
import mediapipe as mp
from vpython import *
mp_pose = mp.solutions.pose #从mediapipe里面获取pose
pose = mp_pose.Pose(static_image_mode=False, min_detection_confidence=0.5, model_complexity=1) #初始化
mp_drawing = mp.solutions.drawing_utils
cam = cv2.VideoCapture(0) #开启摄像头
while True:
_, frame = cam.read() #获取每一帧
cv2.imshow('real time', frame) #显示每一帧
if cv2.waitKey(1) == ord(q): #检查是否按下q键
break
cam.release() #关掉摄像头
cv2.destroyAllWindows() #关掉窗口
现在,我们将使用函数 mp.solutions.pose.Pose().process() 将图像传递到姿势检测机器学习管道。但是管道需要RGB颜色格式的输入图像,因此首先我们必须使用函数cv2.cvtColor()将示例图像从BGR转换为RGB格式,因为OpenCV以BGR格式(而不是RGB)读取图像:
results = pose.process(cv2.cvtColor(f, cv2.COLOR_BGR2RGB))执行姿势检测后,我们将获得三十三个地标的列表,这些地标代表图像中突出人物的身体关节位置。每个地标都有:
-
x– 它是按图像宽度归一化为 [0.0, 1.0] 的地标 x 坐标。 -
y:它是按图像高度归一化为 [0.0, 1.0] 的地标 y 坐标。 -
z:它是归一化为与 x 大致相同的比例的地标z 坐标。它表示以臀部中点为原点的地标深度,因此 z 的值越小,地标离相机越近。 -
可见性:它是一个范围为 [0.0, 1.0] 的值,表示地标在图像中可见(未遮挡)的可能性。在决定是否要显示特定关节时,这是一个有用的变量,因为它可能在图像中被遮挡或部分可见。
但是,我们现在只需要x,y和z。
接下来,我们需要显示它们的位置,并画上线:
mp_drawing.draw_landmarks(image=f, landmark_list=results.pose_landmarks, connections=mp_pose.POSE_CONNECTIONS)运行一下,你的代码应该是这样的:
import cv2
import mediapipe as mp
from vpython import *
mp_pose = mp.solutions.pose #从mediapipe里面获取pose
pose = mp_pose.Pose(static_image_mode=False, min_detection_confidence=0.5, model_complexity=1) #初始化
mp_drawing = mp.solutions.drawing_utils
cam = cv2.VideoCapture(0) #开启摄像头
while True:
_, frame = cam.read() #获取每一帧
results = pose.process(cv2.cvtColor(f, cv2.COLOR_BGR2RGB)) #检查每一帧中的骨架关节点
mp_drawing.draw_landmarks(image=f, landmark_list=results.pose_landmarks, connections=mp_pose.POSE_CONNECTIONS) #画上关节点
cv2.imshow('real time', frame) #显示每一帧
if cv2.waitKey(1) == ord(q): #检查是否按下q键
break
cam.release() #关掉摄像头
cv2.destroyAllWindows() #关掉窗口
现在,一大半已经搞完了,现在只需要搞定在3D中的显示。
points = []
c = []
for x in range(33):
points.append(sphere(radius=5, pos=vector(0, -50, 0)))
c.append(curve(retain=2, radius=4))sphere 是用来布点的。
curve 是用来连接各个点的。
import cv2
import mediapipe as mp
from vpython import *
mp_pose = mp.solutions.pose #从mediapipe里面获取pose
pose = mp_pose.Pose(static_image_mode=False, min_detection_confidence=0.5, model_complexity=1) #初始化
points = []
c = []
for x in range(33):
points.append(sphere(radius=5, pos=vector(0, -50, 0)))
c.append(curve(retain=2, radius=4))
mp_drawing = mp.solutions.drawing_utils
cam = cv2.VideoCapture(0) #开启摄像头
while True:
_, frame = cam.read() #获取每一帧
results = pose.process(cv2.cvtColor(f, cv2.COLOR_BGR2RGB)) #检查每一帧中的骨架关节点
mp_drawing.draw_landmarks(image=f, landmark_list=results.pose_landmarks, connections=mp_pose.POSE_CONNECTIONS) #画上关节点
cv2.imshow('real time', frame) #显示每一帧
if cv2.waitKey(1) == ord(q): #检查是否按下q键
break
cam.release() #关掉摄像头
cv2.destroyAllWindows() #关掉窗口
P.S 后面的操作开始变得骚了,因此我每次操作都会放上一个完整的代码。
我们现在需要让我们的点根据骨骼关节点的x,y,z数值改变:
import cv2
import mediapipe as mp
from vpython import *
mp_pose = mp.solutions.pose #从mediapipe里面获取pose
pose = mp_pose.Pose(static_image_mode=False, min_detection_confidence=0.5, model_complexity=1) #初始化
points = []
c = []
for x in range(33):
points.append(sphere(radius=5, pos=vector(0, -50, 0)))
c.append(curve(retain=2, radius=4))
mp_drawing = mp.solutions.drawing_utils
cam = cv2.VideoCapture(0) #开启摄像头
while True:
_, frame = cam.read() #获取每一帧
results = pose.process(cv2.cvtColor(f, cv2.COLOR_BGR2RGB)) #检查每一帧中的骨架关节点
if results.pose_world_landmarks:
for i in range(11, 33):
if i != 18 and i!=20 and i!= 22 and i != 17 and i!=19 and i!=21:
points[i].pos.x = results.pose_world_landmarks.landmark[mp_pose.PoseLandmark(i).value].x * -cap.get(3)
points[i].pos.y = results.pose_world_landmarks.landmark[mp_pose.PoseLandmark(i).value].y * -cap.get(4)
points[i].pos.z = results.pose_world_landmarks.landmark[mp_pose.PoseLandmark(i).value].z * -cap.get(3)
mp_drawing.draw_landmarks(image=f, landmark_list=results.pose_landmarks, connections=mp_pose.POSE_CONNECTIONS) #画上关节点
cv2.imshow('real time', frame) #显示每一帧
if cv2.waitKey(1) == ord(q): #检查是否按下q键
break
cam.release() #关掉摄像头
cv2.destroyAllWindows() #关掉窗口
再画上连接线:文章来源:https://www.toymoban.com/news/detail-785333.html
import cv2
import mediapipe as mp
from vpython import *
mp_pose = mp.solutions.pose #从mediapipe里面获取pose
pose = mp_pose.Pose(static_image_mode=False, min_detection_confidence=0.5, model_complexity=1) #初始化
points = []
ids = [[12, 14, 16], [11, 13, 15], [12, 24, 26, 28, 30, 32, 28],
[11, 23, 25, 27, 29, 31, 27], [12, 11], [24, 23]]
c = []
for x in range(33):
points.append(sphere(radius=5, pos=vector(0, -50, 0)))
c.append(curve(retain=2, radius=4))
mp_drawing = mp.solutions.drawing_utils
cam = cv2.VideoCapture(0) #开启摄像头
while True:
_, frame = cam.read() #获取每一帧
results = pose.process(cv2.cvtColor(f, cv2.COLOR_BGR2RGB)) #检查每一帧中的骨架关节点
if results.pose_world_landmarks:
for i in range(11, 33):
if i != 18 and i!=20 and i!= 22 and i != 17 and i!=19 and i!=21:
points[i].pos.x = results.pose_world_landmarks.landmark[mp_pose.PoseLandmark(i).value].x * -cap.get(3)
points[i].pos.y = results.pose_world_landmarks.landmark[mp_pose.PoseLandmark(i).value].y * -cap.get(4)
points[i].pos.z = results.pose_world_landmarks.landmark[mp_pose.PoseLandmark(i).value].z * -cap.get(3)
for n in range(2):
for i in range(2):
c[i + 2 * n].append(vector(points[ids[n][i]].pos.x, points[ids[n][i]].pos.y, points[ids[n][i]].pos.z),
vector(points[ids[n][i + 1]].pos.x, points[ids[n][i + 1]].pos.y,
points[ids[n][i + 1]].pos.z), retaine=2)
for n in range(2, 4):
for i in range(6):
c[i+6*n].append(vector(points[ids[n][i]].pos.x, points[ids[n][i]].pos.y, points[ids[n][i]].pos.z),
vector(points[ids[n][i +1]].pos.x, points[ids[n][i + 1]].pos.y, points[ids[n][i+1]].pos.z), retaine = 2)
for n in range(4, 6):
for i in range(1):
c[i+2*n].append(vector(points[ids[n][i]].pos.x, points[ids[n][i]].pos.y, points[ids[n][i]].pos.z),
vector(points[ids[n][i +1]].pos.x, points[ids[n][i + 1]].pos.y, points[ids[n][i+1]].pos.z), retaine = 2)
mp_drawing.draw_landmarks(image=f, landmark_list=results.pose_landmarks, connections=mp_pose.POSE_CONNECTIONS) #画上关节点
cv2.imshow('real time', frame) #显示每一帧
if cv2.waitKey(1) == ord(q): #检查是否按下q键
break
cam.release() #关掉摄像头
cv2.destroyAllWindows() #关掉窗口
好啦!作品已完成,经过整理后就变成这样了:
文章来源地址https://www.toymoban.com/news/detail-785333.html
import cv2
import mediapipe as mp
from vpython import *
#mediapipe 模型变量初始化
def mediapipe_varibles_init():
mp_pose = mp.solutions.pose
pose = mp_pose.Pose(static_image_mode=False, min_detection_confidence=0.5, model_complexity=1)
mp_drawing = mp.solutions.drawing_utils
return pose,mp_pose, mp_drawing
#vpython(三维画图)模型变量初始化
def vpython_variables_init():
points = []
boxs = []
ids = [[12, 14, 16], [11, 13, 15], [12, 24, 26, 28, 30, 32, 28],
[11, 23, 25, 27, 29, 31, 27], [12, 11], [24, 23]]
c = []
for x in range(33):
points.append(sphere(radius=5, pos=vector(0, -50, 0)))
c.append(curve(retain=2, radius=4))
return points, boxs, ids, c
#在3D里画出骨架的函数
def draw_3d_pose():
results = pose.process(cv2.cvtColor(f, cv2.COLOR_BGR2RGB))
if results.pose_world_landmarks:
for i in range(11, 33):
if i != 18 and i!=20 and i!= 22 and i != 17 and i!=19 and i!=21:
points[i].pos.x = results.pose_world_landmarks.landmark[mp_pose.PoseLandmark(i).value].x * -cap.get(3)
points[i].pos.y = results.pose_world_landmarks.landmark[mp_pose.PoseLandmark(i).value].y * -cap.get(4)
points[i].pos.z = results.pose_world_landmarks.landmark[mp_pose.PoseLandmark(i).value].z * -cap.get(3)
for n in range(2):
for i in range(2):
c[i + 2 * n].append(vector(points[ids[n][i]].pos.x, points[ids[n][i]].pos.y, points[ids[n][i]].pos.z),
vector(points[ids[n][i + 1]].pos.x, points[ids[n][i + 1]].pos.y,
points[ids[n][i + 1]].pos.z), retaine=2)
for n in range(2, 4):
for i in range(6):
c[i+6*n].append(vector(points[ids[n][i]].pos.x, points[ids[n][i]].pos.y, points[ids[n][i]].pos.z),
vector(points[ids[n][i +1]].pos.x, points[ids[n][i + 1]].pos.y, points[ids[n][i+1]].pos.z), retaine = 2)
for n in range(4, 6):
for i in range(1):
c[i+2*n].append(vector(points[ids[n][i]].pos.x, points[ids[n][i]].pos.y, points[ids[n][i]].pos.z),
vector(points[ids[n][i +1]].pos.x, points[ids[n][i + 1]].pos.y, points[ids[n][i+1]].pos.z), retaine = 2)
mp_drawing.draw_landmarks(image=f, landmark_list=results.pose_landmarks, connections=mp_pose.POSE_CONNECTIONS)
#窗口关闭函数
def clos_def():
cap.release()
cv2.destroyAllWindows()
#获取变量
points, boxs, ids, c = vpython_variables_init()
pose, mp_pose, mp_drawing = mediapipe_varibles_init()
#打开摄像头,0是第一个摄像头,如果想换一个摄像头请改变这个数字
cap = cv2.VideoCapture(0)
while True:
#获取每一帧的图像
_, f = cap.read()
#vpython里的一个函数,用来调整3D中的FPS
rate(150)
#调用在3D里画出骨架的函数
draw_3d_pose()
#在每一帧里画骨架
#显示每一帧
cv2.imshow('real_time', f)
#检测是否要关闭窗口
if cv2.waitKey(1) & 0xFF == ord('q'):
break
#调用窗口关闭函数
clos_def()到了这里,关于3D人体骨架检测(mediapipe)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!