前言: tim是去中心化分布式即时通讯引擎。不依赖于任何中心服务器,采用去中心化分布式架构,解决传统中心化通讯方式的问题,去中心化分布式架构的通讯引擎的各个节点之间相互连接,形成一个庞大的分布式网络。可以轻松地扩展服务规模,支持更多的用户和业务需求,提供更加安全、可靠、高效的通讯服务。
Github系列开源文章 《tim实践系列文章》
分布式数据存储
分布式数据存储是一种将数据分散存储在网络中多个节点上的技术,它通过多台服务器、计算机或者存储设备来共同维护和管理大量的数据集。这种架构能够提高系统的可扩展性、可用性和容错能力,因为不再依赖于单个大型的集中式存储系统。
在分布式数据存储系统中,数据被分成多个部分并分散存储在各个独立的节点上。每个节点都拥有处理和存储数据的能力,可以根据需要动态地加入或离开系统,使得整个存储系统具有弹性伸缩的特点。
TIM默认的数据库TLDB是一个高性能的分布式数据库,提供了数据的分布式存储。tim可以接入其他数据库,如:mysql,Oracle等,这些关系型数据库同样有数据分布式存储的解决方案。
数据库的分布式存储是外部的支持,与tim没有直接的关联性。只是tim支持使用这些数据库。而重要的是,tim本身对数据存储提供了解决方案,即tim对数据存储进行分区分库。
所谓数据分库分区存储是一种数据存储技术,它将数据分成多个部分,然后分别存储在不同的设备或存储系统中。这种存储方式可以提高数据的访问速度、可靠性和管理效率。
TIM的数据分区分库存储主要根据TIM产生的数据的特性,根据tim的分区策略,将所有数据分散存储在多个分区中。每个分区可以独立地进行数据备份、恢复、迁移和管理,从而提高了数据的可靠性和可用性。同时,通过将数据分散到多个分区中,可以实现负载均衡,提高系统的整体性能。所以,tim可以不依赖于数据库自带的分布式特性,而只需要根据tim的数据分区规则进行分区配置,就可以实现数据的分散存储,从而提高tim集群的性能和扩展性。
TIM的数据分区分库带来的好处
- 水平扩展能力:通过将数据分散在不同服务器或集群中,可以轻松应对不断增长的数据量和高并发访问需求,使得系统能够随着硬件资源的增加而线性地提升处理能力和存储容量。
- 性能提升:通过分区,可以将查询负载分散到各个节点上,避免单点过载,提高查询速度。同时,读写操作可以在多个节点上并行执行,显著减少响应时间。
- 可用性和容错性增强:即使部分数据库分区出现故障,其他分区仍能正常提供服务,保证了系统的高可用性。
- 管理与维护便利:对大数据量进行分区后,每个分区都相对较小,便于管理和维护,如数据迁移、备份恢复等操作更容易实施。
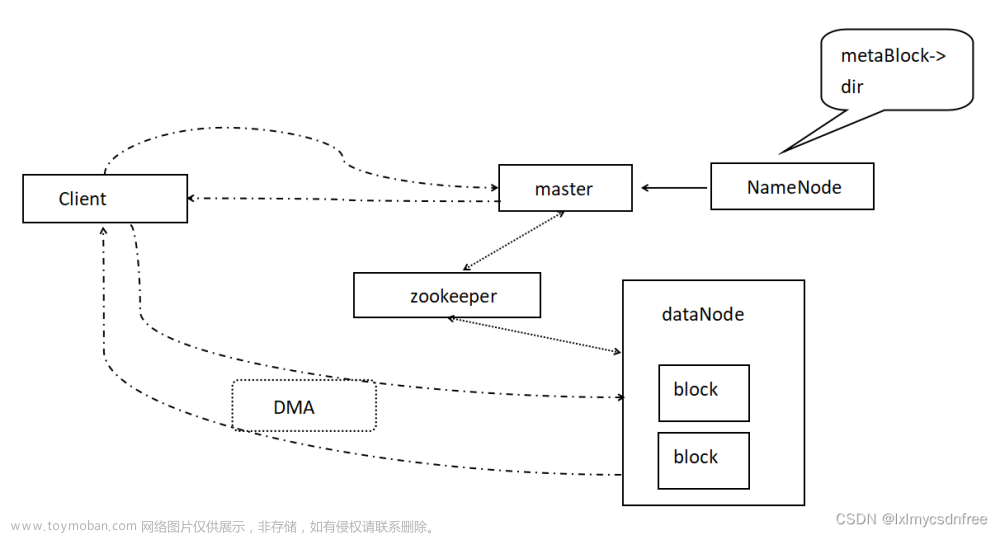
tim节点的数据分布式情况大致如下:

说明:tim将数据分割为1048576个区间. 区间大小可以自由设定,最小为1,最大则是一个tldb节点的情况,表示[0,1048576]。所以,理论上,tim可以支持1048576台tldb数据库节点。实际上,即使一个tim节点无法同时连接1048576台数据库,但是几百上千个数据库节点已经足以解决大部分的业务数据问题。
tim的数据库节点是可以动态扩容的。如

说明:在tim配置上修改数据库配置,可以在下一个时间整点的时候生效。
以下是如何配置tim的分区分库配置:
{
"tldb.extent": [
{
"addr": "127.0.0.1:7001",
"auth": "mycli=123",
"tls": false,
"extent": 300000
},
{
"addr": "127.0.0.1:7002",
"auth": "mycli=123",
"tls": false,
"extent": 700000
},
{
"addr": "127.0.0.1:7003",
"auth": "mycli=123",
"tls": false
}
],
"cluser.listen": ":6001",
"admin.listen": ":8001",
"im.listen": 5080,
"seed": 9589443,
"connectLimit": 1000000,
"memlimit": 3000
}tldb.extent 的作用是tldb数据分区分库存储。tldb.extent为数组,每个元素为一个tldb节点的信息:addr是tldb数据库连接地址,auth是用户名密码,tls表示是否安全协议连接,extent表示分库的范围。
说明:extent表示分区分库的范围,意思是从0至1048576。tim支持把数据存放到范围0-1048576的tldb数据库中,所以理论上,可以有1048576个tldb服务节点。如示例中配置3个tldb节点
- extent=300000
- extent=700000
- 最末节点extent无需配置
表示通过 tim的分区分库策略算法,将数据分为3个区间,分别为[0,300000],[300000,700000],[700000,1048576]。并把数据存放到相应的tldb节点中。
如果扩展数据库,比如:发现第二tldb节点磁盘即将满了可以把700000拆分开,如
- extent=300000
- extent=500000
- extent=700000
- 最末节点extent无需配置
分区分库区间分别为:[0,300000],[300000,500000],[500000,700000],[700000,1048576]
或如配置
- extent=300000
- extent=400000
- extent=550000
- extent=700000
- 最末节点extent无需配置
分区分库区间分别为:[0,300000],[300000,400000],[400000,550000],[550000,700000],[700000,1048576]
注意:动态扩容tim的数据库分区分库区间,增加数据库节点后,tim服务会在下一个整数时间点生效。这是为了减少tim集群数据存储配置不一致的情况。如果可以停止tim服务,统一配置则是最佳情况。如果不想停止tim集群服务,则需校对各个tim服务器的时间,尽量统一时间。修改tim数据库配置后,tim可以相对同时的对新配置生效。文章来源:https://www.toymoban.com/news/detail-785522.html
有任何问题或建议请Email:donnie4w@gmail.com或 https://tlnet.top/contact 发信给我,谢谢!文章来源地址https://www.toymoban.com/news/detail-785522.html
到了这里,关于tim实践系列——分布式数据存储与动态数据库扩容的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!