作者:
腾讯大数据平台部科学实验中心Tech Lead、专家工程师 马金勇博士
腾讯大数据平台部科学实验中心数据负责人、专家工程师 胡明杰
StarRocks Contributor、腾讯高级工程师 刘志行
在 2022 年,腾讯 A/B Test 团队启动了海外商业化版本 ABetterChoice 的建设。作为一个全新的 SaaS 产品,ABetterChoice 将腾讯内部积累的优秀实验能力进行抽象,并基于海外合规、多云环境适配等复杂要求,进行了大刀阔斧的改造,落地一套能满足海外用户诉求的先进实验产品。ABetterChoice 通过 StarRocks 实现了计算引擎的统一,达成实验计算层的规范化以及计算 SQL 的统一化,提升了上层整体应用服务的可复用性。
目前,ABetterChoice 已接入王者荣耀海外版、PUBG Mobile、Ubisoft 全境封锁等业务。希望能够基于 StarRocks + 数据湖的整套数据生态,在深耕海外市场的同时,也能为社区和业界提供一个产品出海的新范式。
A/B Test 介绍
什么是 A/B Test
A/B 实验源自于生物医学里的双盲测试。在双盲测试中,病人会被随机分成两组,在病人不知情的情况下分别给予安慰剂和药物组进行服用。经过一段时间的观察去比较两组病人的病情变化是否具备统计学差异,进而来判断测试用药是否有效。同样,A/B 实验能够运用在互联网领域,为战略决策、产品迭代、新策略的验证等提供科学有效的决策依据。

A/B Test 应用案例
以游戏生态为例,在不同的游戏玩家圈层中,都有能够提升核心关注指标的抓手,比如:潜在玩家更在意游戏是否有足够的吸引性、新玩家更在意游戏的新手引导和初次体验、老玩家更在意游戏生态的建设等。玩家在不同阶段的特征和诉求,都可以通过实验进行深度挖掘,通过科学的实验流程对游戏产品进行改造与优化,提升游戏的玩家口碑和核心运营指标。

关于腾讯 A/B Test
在 2022 年,腾讯 PCG 大数据平台部科学实验团队,基于公司内沉淀的 A/B Test 平台启动了海外商业化版本 ABetterChoice 的建设,作为一个全新的 SaaS 产品,ABetterChoice 将腾讯内部积累的优秀实验能力进行抽象,并基于海外合规、多云环境适配等复杂要求,进行了大刀阔斧的改造,落地一套能满足海外用户诉求的先进实验产品。
目前 ABetterChoice 已接入的业务有:王者荣耀海外版、PUBG Mobile、Ubisoft全境封锁等。
 ABetterChoice官网:ABetterChoice.ai
ABetterChoice官网:ABetterChoice.ai
改造背景
出海原因
在腾讯司内游戏出海,以及海外二方工作室的快速发展的背景下,腾讯 A/B 实验平台作为一款能够赋能业务增长的数据产品,也开始进行海外版本的改造筹备工作,致力于提供一套对齐海外竞品,并能突出腾讯 A/B 特性的优秀 SaaS 产品。

用户诉求
在海外版本改造的过程中,我们对业务的诉求进行了深入剖析和划分,主要分为以下三类:
腾讯自研出海游戏(Honor of kings、Pubgm),数据组件大部分会与腾讯云生态深度绑定,不希望数据出云。
海外工作室(SplashDamage、Funcom),作为海外独立运作的游戏公司(北美、欧洲),在数据生态方面会与海外公有云进行深度绑定(GCP、AWS),对海外数据合规有着严格的要求(GDPR/CCPA)。
潜在的独立海外用户,数据架构通过海外公有云搭建,但数据仓库和引擎方面的选择更加多元化(Snowflake、Databricks、Bigquery、Redshift等)。
基于不同的业务背景和诉求,我们在改造的过程中也需要进行通盘考虑,提供一套更通用化的数据底座支撑。

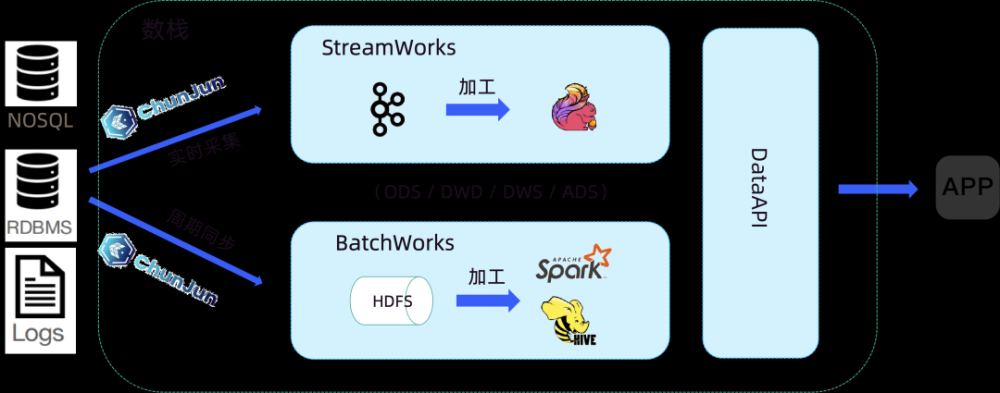
架构现状
腾讯 A/B Test 在支持司内业务出海的过程中,采用典型的 Kappa 架构满足数据流批上报和多维分析的场景,其中用到了 StarRocks 的存算一体模式。随着更多的业务接入和使用,该架构逐渐显露弊端,分别有:
多表 Join 计算场景需要耗费大量计算资源,存算一体架构,计算资源不能够独立扩容。
存算一体模式中,集群 Local storage 采用了 SSD 盘,随着业务数据生命周期延长,存储性价降低,存储量上涨,带来成本压力。
该架构与腾讯司内组件 + 腾讯云深度绑定,不具备支持海外二方工作室的数据能力。
如果平台想要在海外进行独立化部署,数据架构必须朝着更通用化的方向进行改造。

实验架构改造
实验数据入湖
根据业务在不同云上的诉求,我们的架构改造方向也明确为:
数据底座基于主流公有云搭建(腾讯云 + 海外公有云)。 选用湖仓一体、存算分离的计算架构,满足数据合规和多租户的接入场景。 基于这两点要求,我们分别在腾讯云和海外公有云建设了两套数据湖方案:
在腾讯云,我们引入腾讯云大数据组件 TBDS,为司内出海游戏业务提供数据底座支撑。
在海外公有云,我们引入 Databricks,为海外独立游戏工作室、独立公司提供数据入湖的通道,底层数据源不仅支持标准的对象存储(GCS/S3/Blob),也能够支持应用层数据引擎(Bigquery/Redshift/Snowflake 等),能够更大限度的满足海外不同业务的多种数据入湖要求。

湖上建仓
也正因为有两套数据湖,我们才需要一个更加通用的 OLAP 引擎,不仅能够在数据湖上进行建仓实现湖仓一体生态,降低数据存储成本。同时也需要拥有优秀的本地存储+计算能力,来满足实验结果的快速产出。
StarRocks 在 3.1版本后,对 Delta Lake 以及 Iceberg 的支持更为完善,可以在不导入数据湖数据的前提下,对数据湖数据进行高性能查询(Data Cache),实现真正的湖仓融合。在 ABetterChoice 的场景下,只需要 StarRocks 一款计算引擎,就能达成实验计算层的规范化,以及计算 SQL 的统一化,提升上层整体应用服务的可复用性。

数据冷热分离
1、分区降冷
在实验场景中,不同用户对实验数据的存储周期各不相同。正常实验计算周期是 14 天,StarRocks 会将最近 14 天的数据存储到本地 SSD,以提升大部分实验结果的计算性能。但实验场景中同样存在跨多天的计算场景(长期观察实验),会对 1 - 6 个月的数据进行批量累计计算,如果这批数据都存在 SSD 中,势必会造成存储成本的无序增长。
基于对存储性价比的权衡,我们采用了基于数据湖调度的数据降冷机制,对超过 14 天的数据自动降冷至对象存储,在降冷的过程中,会通过数据湖进行表 Meta 信息和状态信息的维护。应用端通过数据湖拉取此类信息进行下发判断:在整个降冷过程(一小时内)完成之前,都不会对数据进行查询下发,来保证结果数据的准确性。

2、冷热混查
在数据完成降冷操作后,如果实验 SQL 的查询周期足够长,包含了冷数据 + 热数据的数据分区,那么整个计算就蜕变成 BE + CN 的混合查询模式。
在实验的计算场景中,我们需要对实验 ID 维度进行 group by,再根据观测指标字段进行聚合操作。根据特定的查询场景,我们对集群的执行计划进行了调整:该类 SQL 在提交到集群后,每个 BE/CN 节点会先对 exp_id 字段进行 group by 分组,先通过 Agg 算子对观测指标进行初步汇总,然后每个 BE/CN 的中间汇总数据再通过 Union 的方式,通过后面的 Agg 算子对进行二次聚合,得到最终实验结果数据。
该方式通过对集群执行计划的改造和调整,减少了大量中间数据 Exchange 传输的过程,提升了实验 SQL 的查询性能表现,将 SQL 的平均执行时间较改造前整体降低了 80%。

多租户隔离
A/B 实验属于典型的多租户场景,由于各业务之间的独特性,在不同的实验使用规模、用户量级、实验放量阶段下,会存在数据量级的显著差异,也因此产生了业务定制化计算资源的诉求。
同样,由于海外 CCPA/GDPR 的数据合规要求,我们需要对用户数据进行单元级别的物理隔离,以及用户级别的虚拟权限管控,保证业务数据在任何层面,都能做到租户层面隔离。因此,我们基于 StarRocks 和公有云组件的能力,设计了一套集查询引擎 + 数据湖 + 对象存储的多租户隔离方案。
查询引擎层:
对常规的业务,计算任务会全部请求到一个公共的 StarRocks 集群,我们通过对查询权重的分配,保证了每个业务的计算都能够得到平等的下发,以提升公共集群的资源利用率。同样,每个业务会独占一个 Database 和 User,并基于各自 User 进行单独库级别赋权,规整业务账号之间的访问范围和权限细分。
对独特诉求的业务,我们会为其独立部署 StarRocks 集群,该集群只会负责该业务的查询,由于独占计算资源,该集群能够提升实验的即席查询效率和预计算产出时延,并能够在业务大促等高峰流量场景中,做到单集群的独立扩容操作。
数据湖层:通过采用 Databricks Unity Catalog 的能力,在每个业务的 Meta data 之间,实现 SHOW/SELECT 权限的屏蔽和管控。
对象存储层:ABetterChoice 会为每个业务创建独立的对象存储桶,并在地域层面实现隔离,通过云平台 IAM 实现用户粒度的权限管控。

总结与展望
当下基于 StarRocks 的海外实验平台 ABetterChoice,已在公有云实现落地,并完成了腾讯司内出海游戏(王者荣耀海外版、Pubgm)以及海外独立游戏工作室(Epic)等业务的接入验证工作。
我们的目标,也希望能够基于 StarRocks + 数据湖的整套数据生态,在深耕海外市场的同时,也能为社区和业界提供一个产品出海的新范式,在未来,我们也会对以下领域进行深耕:
StarRocks 基于 Delta Lake,在实验多维即席查询场景下的计算性能优化。 StarRocks 湖仓一体架构,在海外数据合规方面的定制化改造。 最终形成一套能够立足于海外场景,基于 StarRocks 的湖仓一体生态建设经验。
更多资讯,请关注 StarRocks 公号:StarRockslabs
StarRocks 源码:https://github.com/StarRocks/starrocks (喜欢的话,Star 一个吧!)
欢迎入群交流:https://wx.focussend.com/weComLink/mobileQrCodeLink/33412/9c312文章来源:https://www.toymoban.com/news/detail-785658.html
本文由 mdnice 多平台发布文章来源地址https://www.toymoban.com/news/detail-785658.html
到了这里,关于腾讯实验平台基于 StarRocks 构建湖仓底座的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!