数据来源分析💥
网站链接: aHR0cHM6Ly93d3cua3Vnb3UuY29tLw==
歌曲下载 signature 💥
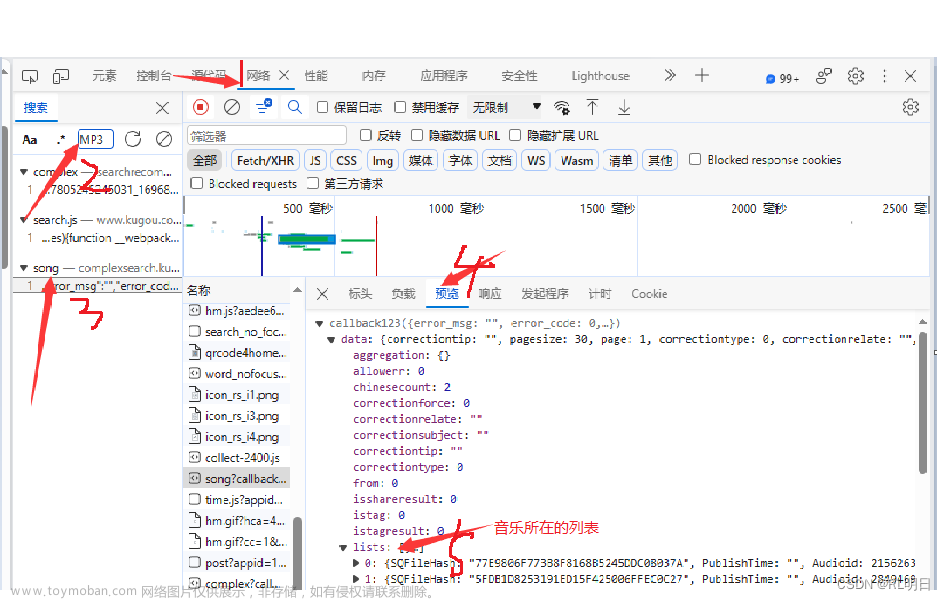
- 正常抓包分析找到音频链接地址

文章来源地址https://www.toymoban.com/news/detail-785845.html
- 通过链接搜索找到对应的数据包位置


- 分析
signature参数加密位置


通过 s 列表 合并成字符串, 传入d函数中进行加密, 返回32位, 还是比较明显的MD5加密,
相当于请求参数除了signature 以外, 在头尾加了一段内容 "NVPh5oo715z5DIWAeQlhMDsWXXQV4hwt"
可以直接通过python代码实现不需要额外扣代码
歌曲下载 signature: Python代码实现💥
import hashlib def download(date_time, music_id): """ :param date_time: 时间戳 1704522723326 :param music_id: 歌曲ID j58xpcd :return: signature 加密参数 """ s = [ "NVPh5oo715z5DIWAeQlhMDsWXXQV4hwt", "appid=1014", f"clienttime={date_time}", # 时间戳 "clientver=20000", "dfid=11S5Hd0E3dhq3jHxZ90dzFYU", f"encode_album_audio_id={music_id}", # 歌曲ID "mid=8b5710fdab09aea0e4649de3e430ad23", "platid=4", "srcappid=2919", "token=", "userid=0", "uuid=8b5710fdab09aea0e4649de3e430ad23", "NVPh5oo715z5DIWAeQlhMDsWXXQV4hwt" ] string = "".join(s) MD5 = hashlib.md5() MD5.update(string.encode('utf-8')) signature = MD5.hexdigest() return signature
歌曲搜索 signature 💥
歌曲搜索主要是获取歌曲的ID, 同样也是MD5加密的方式, 只是传入的参数不一样

歌曲搜索 signature: Python代码实现💥
def search(date_time, keyword): """ :param date_time: 时间戳 1704522723326 :param keyword: 搜索关键词 许嵩 :return: """ s = [ "NVPh5oo715z5DIWAeQlhMDsWXXQV4hwt", "appid=1014", "bitrate=0", "callback=callback123", f"clienttime={date_time}", # 时间戳 "clientver=1000", "dfid=11S5Hd0E3dhq3jHxZ90dzFYU", "filter=10", "inputtype=0", "iscorrection=1", "isfuzzy=0", f"keyword={keyword}", "mid=8b5710fdab09aea0e4649de3e430ad23", "page=1", "pagesize=30", "platform=WebFilter", "privilege_filter=0", "srcappid=2919", "token=", "userid=0", "uuid=8b5710fdab09aea0e4649de3e430ad23", "NVPh5oo715z5DIWAeQlhMDsWXXQV4hwt" ] string = "".join(s) MD5 = hashlib.md5() MD5.update(string.encode('utf-8')) signature = MD5.hexdigest() return signature
然后整合一下代码, 实现一个搜索下载的功能💥
import hashlib import time import requests import re import json import prettytable as pt def md5_hash(date, keyword): text = [ 'NVPh5oo715z5DIWAeQlhMDsWXXQV4hwt', 'appid=1014', 'bitrate=0', 'callback=callback123', f'clienttime={date}', 'clientver=1000', 'dfid=11S5Hd0E3dhq3jHxZ90dzFYU', 'filter=10', 'inputtype=0', 'iscorrection=1', 'isfuzzy=0', f'keyword={keyword}', 'mid=8b5710fdab09aea0e4649de3e430ad23', 'page=1', 'pagesize=30', 'platform=WebFilter', 'privilege_filter=0', 'srcappid=2919', 'token=', 'userid=0', 'uuid=8b5710fdab09aea0e4649de3e430ad23', 'NVPh5oo715z5DIWAeQlhMDsWXXQV4hwt' ] string = ''.join(text) # 创建 MD5 哈希对象 md5 = hashlib.md5() # 更新哈希对象的内容 md5.update(string.encode('utf-8')) # 更新哈希对象的内容 signature = md5.hexdigest() print(signature) return signature def save(music_id): link = 'https://wwwapi.kugou.com/yy/index.php' params = { 'r': 'play/getdata', # 'callback': 'jQuery19105617303032764249_1693890961892', 'dfid': '11S5Hd0E3dhq3jHxZ90dzFYU', 'appid': '1014', 'mid': '8b5710fdab09aea0e4649de3e430ad23', 'platid': '4', 'encode_album_audio_id': music_id, '_': '1693890961893', } link_data = requests.get(url=link, params=params, headers=headers).json() play_url = link_data['data']['play_url'] audio_name = link_data['data']['audio_name'] name = re.sub(r'[\\/:"?*<>|]', '', audio_name) content = requests.get(url=play_url, headers=headers).content with open('music\\' + name + '.mp3', mode='wb') as f: f.write(content) now_time = int(time.time() * 1000) keyword = input('请输入歌手名字 / 歌曲: ') signature = md5_hash(now_time, keyword) url = 'https://complexsearch.kugou.com/v2/search/song' data = { 'callback': 'callback123', 'srcappid': '2919', 'clientver': '1000', 'clienttime': now_time, 'mid': '8b5710fdab09aea0e4649de3e430ad23', 'uuid': '8b5710fdab09aea0e4649de3e430ad23', 'dfid': '11S5Hd0E3dhq3jHxZ90dzFYU', 'keyword': keyword, 'page': '1', 'pagesize': '30', 'bitrate': '0', 'isfuzzy': '0', 'inputtype': '0', 'platform': 'WebFilter', 'userid': '0', 'iscorrection': '1', 'privilege_filter': '0', 'filter': '10', 'token': '', 'appid': '1014', 'signature': signature, } headers = { 'Referer': 'https://www.kugou.com/', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36', } response = requests.get(url=url, params=data, headers=headers) html_data = re.findall('callback123\((.*)\)', response.text)[0].replace(')', '') tb = pt.PrettyTable() tb.field_names = ['序号', '歌手', '歌名', '专辑', 'ID'] lis = [] num = 1 json_data = json.loads(html_data) for index in json_data['data']['lists']: SingerName = index['SingerName'] # 歌手 SongName = index['SongName'] # 歌名 AlbumName = index['AlbumName'] # 专辑 SongID = index['EMixSongID'] # ID dit = { '歌手': SingerName, '歌名': SongName, '专辑': AlbumName, 'ID': SongID, } tb.add_row([num, SingerName, SongName, AlbumName, SongID]) lis.append(dit) num += 1 print(tb) page = input('请输入你要下载的歌曲的序号: <全部下载:0> ') try: if page == '0': for li in lis: save(music_id=li['SongID']) else: save(music_id=lis[int(page)-1]['ID']) except Exception as e: print('输入有问题', e) # 我还录制了视频进行详细讲解,都放在这个扣裙了 708525271

同样也可以结合gui实现一个下载的软件
 文章来源:https://www.toymoban.com/news/detail-785845.html
文章来源:https://www.toymoban.com/news/detail-785845.html
到了这里,关于Python逆向爬虫入门教程: 酷狗音乐加密参数signature逆向解析的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!