Yang, S., Liu, J., Zhang, R., Pan, M., Guo, Z., Li, X., Chen, Z., Gao, P., Guo, Y., & Zhang, S. (2023). LiDAR-LLM: Exploring the Potential of Large Language Models for 3D LiDAR Understanding. In arXiv [cs.CV]. arXiv. http://arxiv.org/abs/2312.14074
最近,大型语言模型(LLMs)和多模态大型语言模型(MLLMs)在指令跟随和2D图像理解方面表现出了潜力。虽然这些模型很强大,但它们尚未被开发成能够理解更具挑战性的3D物理场景,特别是在稀疏的户外LiDAR数据方面。在本文中,我们引入了LiDAR-LLM,该模型以原始LiDAR数据作为输入,并利用LLMs的卓越推理能力来全面理解户外3D场景。我们的LiDAR-LLM的核心见解是将3D户外场景认知重新构想为一个语言建模问题,涵盖了3D字幕生成、3D定位、3D问答等任务。具体而言,由于缺乏3D LiDAR-文本配对数据,我们引入了一个三阶段的训练策略,并生成相关数据集,逐步将3D模态与LLMs的语言嵌入空间对齐。此外,我们设计了一个视图感知变压器(VAT)来连接3D编码器和LLM,有效地弥合了模态差距,并增强了LLM对视觉特征的空间定位理解。我们的实验表明,LiDAR-LLM具有理解关于3D场景的各种指令并进行复杂的空间推理的优越能力。LiDAR-LLM在3D字幕生成任务上取得了40.9的BLEU-1,而在3D定位任务上实现了63.1%的分类准确率和14.3%的BEV mIoU。网页链接:https://sites.google.com/view/lidar-llm文章来源:https://www.toymoban.com/news/detail-785864.html

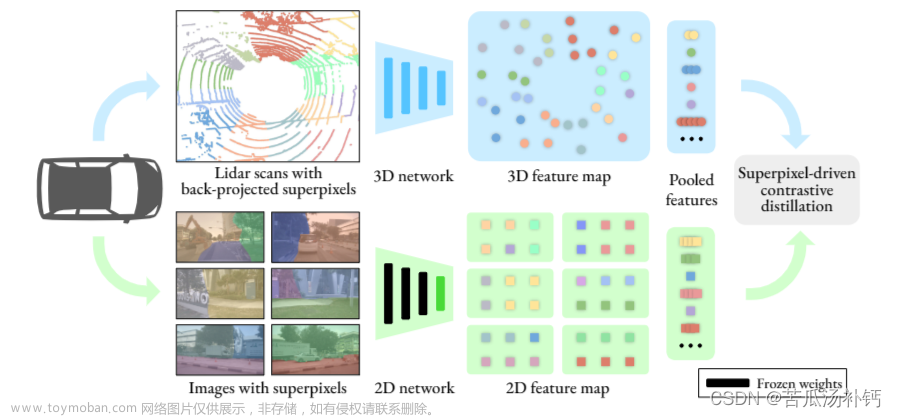
图1. LiDAR-LLM的特性。我们提出的LiDAR-LLM以3D LiDAR数据为输入,并将3D模态与语言嵌入空间对齐,充分利用LLM的卓越推理能力来理解户外3D场景。为了增强LiDAR特征的空间定位表示,我们在LiDAR编码器和LLM之间引入了一个View-Aware Transformer 视图感知变压器。同时,底部展示了从我们生成或使用的LiDAR-文本数据中衍生出的示例,涵盖了一系列与3D相关的任务。
图2 我们LiDAR-LLM框架的概述。初始列展示了我们的3D特征提取器,该提取器处理LiDAR点云输入以得到3D体素特征。随后,特征沿z轴展平,生成鸟瞰图(BEV)特征。视图感知变压器(VAT)接受BEV嵌入和可学习的查询作为输入,输出的查询作为软提示输入到冻结的LLM。在VAT中,我们引入了六个视图位置嵌入到BEV特征中,以及相应的查询,以增强空间定位表示的能力。该框架将LiDAR模态与语言嵌入空间对齐,使我们能够充分利用LLM来全面理解户外3D场景。
图3. 提示性问题和LiDAR-LLM预测的定性示例文章来源地址https://www.toymoban.com/news/detail-785864.html
到了这里,关于[arxiv论文阅读] LiDAR-LLM: Exploring the Potential of Large Language Models for 3D LiDAR Understanding的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!

![[论文阅读]PillarNeXt——基于LiDAR点云的3D目标检测网络设计](https://imgs.yssmx.com/Uploads/2024/02/715798-1.png)


![[论文阅读]MVF——基于 LiDAR 点云的 3D 目标检测的端到端多视图融合](https://imgs.yssmx.com/Uploads/2024/01/817020-1.png)