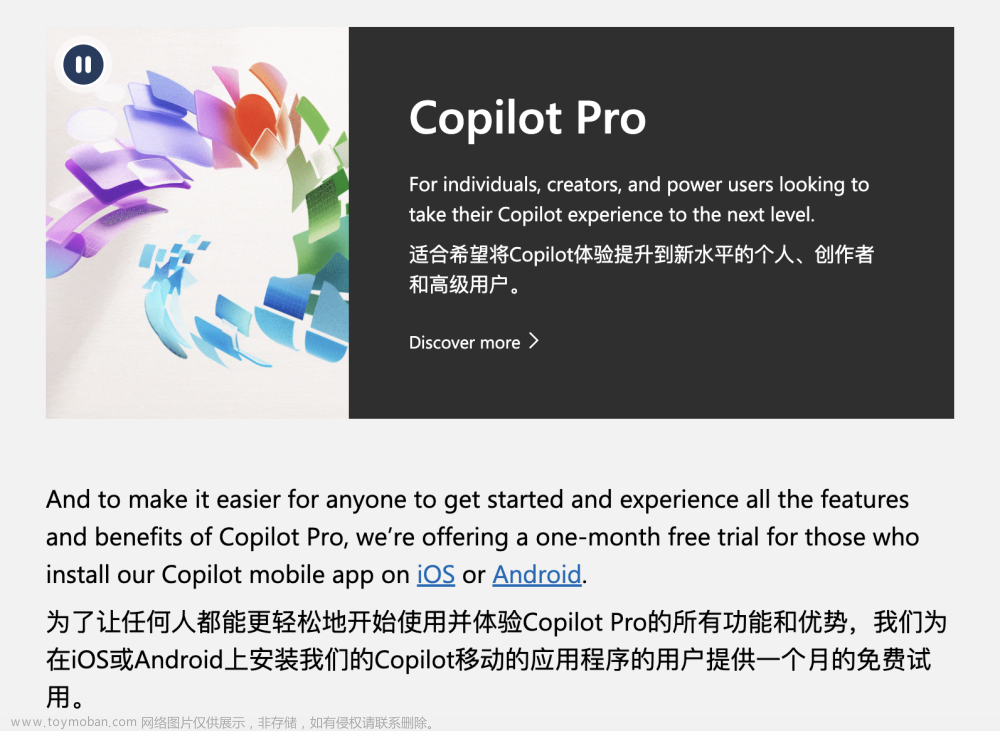
模型参数支持 GPT-4 和 GPT-3.5-turbo ,实测使用其他模型均会以默认的 3.5 处理(对比 OpenAI API 的返回结果,猜测应该是最早的版本 GPT-4-0314 和 GPT-3.5-turbo-0301 )
获取 Copilot Token
首先,你的账号需要开通 Github Copilot 服务
获取 Github Copilot Plugin Token 的方式目前有两种方式:
- 通过安装 Github Copilot CLI 授权获取(推荐)。
- 通过第三方接口授权获取,不推荐,因为不安全。
如何使用
- 安装并启动 copilot-gpt4-service 服务,如本地启动后,API默认地址为:http://127.0.0.1:8080;
- 获取你的 GitHub 账号 Github Copilot Plugin Token(详见下文);
- 安装第三方客户端,如:ChatGPT-Next-Web,在设置中填入 copilot-gpt4-service 的 API 地址和 Github Copilot Plugin Token,即可使用 GPT-4 模型进行对话。
最佳实践方式
经社区验证和讨论,最佳实践方式为:
- 本地部署,仅个人使用(推荐);
- 自用服务器集成 ChatGPT-Next-Web 部署, 服务不公开;
- 服务器部署, 公开但个人使用 (例如多客户端使用场景 Chatbox, OpenCat APP, ChatX APP)。
不建议方式
- 以公共服务的方式提供接口多个 Token 在同一个 IP 地址进行请求, 容易被判定为异常行为
- 同客户端 Web(例如 ChatGPT-Next-Web) 以默认 API 以及 API Key 的方式提供公共服务同一个 Token 请求频率过高, 容易被判定为异常行为
- Serverless 类型的提供商进行部署服务生命周期短, 更换 IP 地址频繁, 容易被判定为异常行为
- 其他滥用行为或牟利等行为。
客户端
使用 copilot-gpt4-service,需要配合第三方客户端,目前已测试支持以下客户端:
- ChatGPT-Next-Web (推荐)
- Chatbox:支持 Windows, Mac, Linux 平台
- OpenCat APP:支持 iOS、Mac 平台
- ChatX APP :支持 iOS、Mac 平台
服务端
copilot-gpt4-service 服务的部署方式目前包含 Docker 部署、源码部署、Kubernetes 部署实现
config.env 默认配置项如下
HOST=localhost # 服务监听地址
PORT=8080 # 服务监听端口
CACHE=true # 是否启用持久化
CACHE_PATH=db/cache.sqlite3 # 持久化缓存的路径(仅当 CACHE=true 时有效)
DEBUG=false # 是否启用调试模式,启用后会输出更多日志
LOGGING=true # 是否启用日志
LOG_LEVEL=info # 日志级别,可选值:panic、fatal、error、warn、info、debug、trace(注意:仅当 LOGGING=true 时有效)
部署:
docker run -d \
--name copilot-gpt4-service \
--restart always \
-p 8080:8080 \
-e HOST=0.0.0.0 \
aaamoon/copilot-gpt4-service:latest文章来源:https://www.toymoban.com/news/detail-785868.html
https://www.jdon.com/71776.html文章来源地址https://www.toymoban.com/news/detail-785868.html
到了这里,关于将Github Copilot转换为免费使用GPT-4的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!