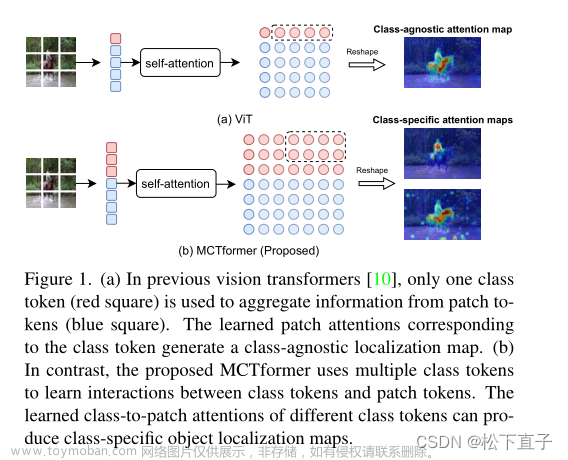
一、如果不出错的话
参考链接:https://github.com/jacobgil/pytorch-grad-cam
1、 先将此github源码clone到本地
2、 参考pytorch-grad-cam/tutorials/Class Activation Maps for Semantic Segmentation.ipynb
3、 把包都导好。
4、注意推理做的归一化与标准化跟自己训练的时候弄成一样的import warnings
warnings.filterwarnings('ignore')
warnings.simplefilter('ignore')
from torchvision.models.segmentation import deeplabv3_resnet50
import torch
import torch.functional as F
import numpy as np
import requests
import torchvision
from PIL import Image
from pytorch_grad_cam.utils.image import show_cam_on_image, preprocess_image
from models.model_stages_double import BiSeNet
from pytorch_grad_cam.grad_cam import GradCAM
# 读入自己的图像
image = np.array(Image.open('/media/wlj/soft_D/WLJ/WJJ/STDC-Seg/camera_4_crop/leftImg8bit/test/nok/NoK_4_leftImg8bit.png'))
rgb_img = np.float32(image) / 255
input_tensor = preprocess_image(rgb_img,
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
# 读入自己的模型并且加载训练好的权重
model = BiSeNet(backbone='STDCNet813',n_classes=6)
model.cuda()
model = model.eval()
save_pth = '/media/wlj/soft_D/WLJ/WJJ/STDC-Seg/checkpoints/camera_4_crop/batch8_11.2_15000it_dublebaseline_left1xSGE2345_right0.5x_DFConv2_SGE3_RGB/model_maxmIOU100.pth'
model.load_state_dict(torch.load(save_pth))
if torch.cuda.is_available():
model = model.cuda()
input_tensor = input_tensor.cuda()
# 推理
output = model(input_tensor)[0]
normalized_masks = torch.softmax(output, dim=1).cpu()
# 自己的数据集的类别
sem_classes = [
'__background__', 'round', 'nok', 'headbroken', 'headdeep', 'shoulderbroken'
]
sem_class_to_idx = {cls: idx for (idx, cls) in enumerate(sem_classes)}
round_category = sem_class_to_idx["nok"]
round_mask = torch.argmax(normalized_masks[0], dim=0).detach().cpu().numpy()
round_mask_uint8 = 255 * np.uint8(round_mask == round_category)
round_mask_float = np.float32(round_mask == round_category)
# 推理结果图与原图拼接
# both_images = np.hstack((image, np.repeat(round_mask_uint8[:, :, None], 3, axis=-1)))
# img = Image.fromarray(both_images)
# img.save("./hhhh.png")
class SemanticSegmentationTarget:
def __init__(self, category, mask):
self.category = category
self.mask = torch.from_numpy(mask)
if torch.cuda.is_available():
self.mask = self.mask.cuda()
def __call__(self, model_output):
return (model_output[self.category, :, :] * self.mask).sum()
# 自己要放CAM的位置
target_layers = [model.conv_out]
targets = [SemanticSegmentationTarget(round_category, round_mask_float)]
with GradCAM(model=model, target_layers=target_layers,
use_cuda=torch.cuda.is_available()) as cam:
grayscale_cam = cam(input_tensor=input_tensor,
targets=targets)[0, :]
cam_image = show_cam_on_image(rgb_img, grayscale_cam, use_rgb=True)
# 保存CAM的结果
img = Image.fromarray(cam_image)
img.show()
img.save('./result.png')二、可能出错
我遇到了 如下错误
解决方法:
将base_cam.py的第81行修改为:

就不报错了!
拿下!
 文章来源:https://www.toymoban.com/news/detail-785872.html
文章来源:https://www.toymoban.com/news/detail-785872.html
文章来源地址https://www.toymoban.com/news/detail-785872.html
到了这里,关于grad-CAM用于自己的语义分割网络【亲测】的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!