神经网络语言模型(Neural Network Language Model,NNLM)是一种用神经网络建模语言的方法。NNLM 通过学习文本序列中的词汇之间的概率关系,能够捕捉到语言的结构和语境,从而能够生成自然语言文本或进行其他与语言相关的任务。
想象一下,你正在阅读一本小说。每当你读到一个单词时,你的大脑都在努力理解上下文,以便预测下一个单词是什么。NNLM的工作方式类似于这个过程。它通过学习大量的文本数据,尝试理解每个单词与其上下文之间的关系。这就像是让计算机通过阅读海量文本来学会语言,使其能够预测或生成连贯的文本。
假设有一个NNLM被训练成阅读小说,并学到了以下规律:在描述风景时,单词"阳光"和"微风"通常会在一起出现。当NNLM看到"阳光"这个词时,它会有很大的信心下一个单词可能是"微风"。这种学习使得NNLM能够更好地理解语言的语境和含义。
下面是对神经网络语言模型的详细解释:
-
输入表示: NNLM 的输入是一个固定长度的前文单词序列,用于预测下一个单词。每个单词通常由其词嵌入(word embedding)表示,这是一个固定维度的实数向量,它将单词映射到连续的向量空间中。
-
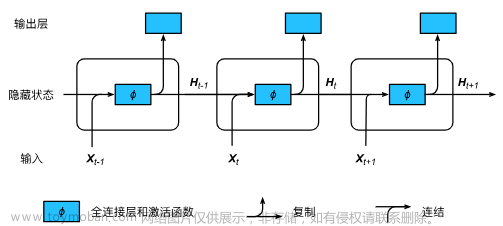
结构: NNLM 通常包含一个嵌入层(embedding layer),一个或多个隐藏层(hidden layers),以及一个输出层。嵌入层用于将输入的单词转换为连续向量表示,隐藏层用于学习输入序列的语言结构,而输出层则输出下一个单词的概率分布。
-
训练目标: NNLM 的训练目标是最大化给定训练数据中序列的联合概率。具体而言,NNLM 试图最大化给定前文单词的条件下,下一个单词出现的概率。这可以通过最小化负对数似然(negative log-likelihood)来实现。
-
上下文窗口: 为了捕捉上下文信息,NNLM 通常采用一个上下文窗口(context window),它定义了在预测下一个单词时考虑的前几个单词。这样的设计有助于模型更好地理解输入序列的语言结构。
-
非线性激活函数: 在隐藏层中通常使用非线性激活函数,如 tanh 或者 sigmoid,以增加模型的表示能力。
NNLM 的优势:
-
上下文信息: NNLM 能够捕捉长距离的上下文信息,因为它在训练时考虑了前文的多个单词。
-
连续表示: 通过使用词嵌入,NNLM 可以将单词映射到连续的向量空间中,更好地处理词汇之间的语义关系。
-
灵活性: NNLM 的结构可以根据任务的不同进行调整,使其适应多种语言建模任务。
应用示例:
-
语言建模: NNLM 可以用于语言建模,即预测一个句子中下一个单词的可能性。
-
自动文本生成: 基于学到的语言模型,NNLM 可以用于生成自然语言文本,如文章、故事等。
-
信息检索: NNLM 的语言表示能力可以用于改进信息检索系统,提高检索结果的相关性。
-
对话系统: 在对话系统中,NNLM 可以用于理解用户输入、生成系统回复。
-
下面是一个最简单的NNLM模型代码
import torch
import torch.nn as nn
import torch.optim as optim
class NNLM(nn.Module):
def __init__(self, vocab_size, embedding_dim, context_size):
super(NNLM, self).__init__()
self.embeddings = nn.Embedding(vocab_size, embedding_dim)
self.linear1 = nn.Linear(context_size * embedding_dim, 128)
self.linear2 = nn.Linear(128, vocab_size)
self.activation = nn.ReLU()
self.softmax = nn.LogSoftmax(dim=1)
def forward(self, inputs):
embeds = self.embeddings(inputs).view((1, -1))
out = self.activation(self.linear1(embeds))
out = self.linear2(out)
out = self.softmax(out)
return out
# 示例数据
context = [2, 45, 12, 67, 32] # 假设这是一个包含5个单词的上下文
# 创建模型
vocab_size = 10000 # 假设词汇表大小为10000
embedding_dim = 50
context_size = len(context)
model = NNLM(vocab_size, embedding_dim, context_size)
# 定义损失函数和优化器
criterion = nn.NLLLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)
# 转换为PyTorch张量
inputs = torch.tensor(context, dtype=torch.long)
# 训练模型
for epoch in range(100):
model.zero_grad()
output = model(inputs)
loss = criterion(output, torch.tensor([3])) # 假设目标单词的索引是3
loss.backward()
optimizer.step()
将上述NNLM代码改成每个 epoch 中使用不同的上下文,在每个 epoch 中预测下一个单词而不是使用固定的目标索引文章来源:https://www.toymoban.com/news/detail-786060.html
import torch
import torch.nn as nn
import torch.optim as optim
import random
class NNLM(nn.Module):
def __init__(self, vocab_size, embedding_dim, context_size):
super(NNLM, self).__init__()
self.embeddings = nn.Embedding(vocab_size, embedding_dim)
self.linear1 = nn.Linear(context_size * embedding_dim, 128)
self.linear2 = nn.Linear(128, vocab_size)
self.activation = nn.ReLU()
self.softmax = nn.LogSoftmax(dim=1)
def forward(self, inputs):
embeds = self.embeddings(inputs).view((1, -1))
out = self.activation(self.linear1(embeds))
out = self.linear2(out)
out = self.softmax(out)
return out
# 示例数据
vocab_size = 10000 # 假设词汇表大小为10000
embedding_dim = 50
context_size = 5 # 上下文大小为5
model = NNLM(vocab_size, embedding_dim, context_size)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss() # 使用交叉熵损失函数,适用于分类任务
optimizer = optim.SGD(model.parameters(), lr=0.01)
# 训练模型
num_epochs = 100
for epoch in range(num_epochs):
# 随机选择一个新的上下文
context = [random.randint(0, vocab_size - 1) for _ in range(context_size)]
# 转换为PyTorch张量
inputs = torch.tensor(context, dtype=torch.long)
model.zero_grad()
output = model(inputs)
# 随机选择一个下一个单词的索引作为目标
target_index = random.randint(0, vocab_size - 1)
# 构造目标张量
target = torch.tensor([target_index], dtype=torch.long)
loss = criterion(output, target)
loss.backward()
optimizer.step()
这里使用了 nn.CrossEntropyLoss() 作为损失函数,它适用于分类任务。目标标签是一个表示下一个单词的索引。在每个 epoch 中,通过 random.randint(0, vocab_size - 1) 随机选择一个新的目标索引,从而模拟训练过程中不同目标的情况。请注意,上述代码仅仅是演示如何将目标从固定的索引更改为随机选择的下一个单词索引。在实际应用中,你可能需要准备包含真实文本数据的数据集,并确保上下文和目标的构建与你的应用场景相匹配。此外,还需要更复杂的数据准备和处理步骤,以确保模型能够有效地学习语言表示文章来源地址https://www.toymoban.com/news/detail-786060.html
到了这里,关于神经网络语言模型(Neural Network Language Model,NNLM)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!