-
ES基本介绍
-
单机ES部署
-
ES(Elasticsearch)集群部署
1.基本介绍
Elasticsearch:存储、搜索和分析
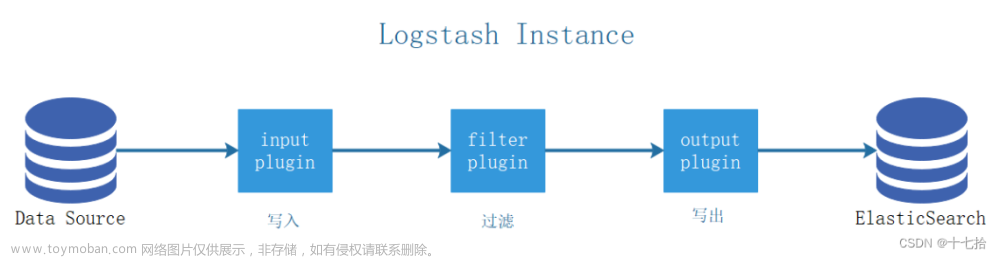
Elasticsearch是Elastic Stack核心的分布式搜索和分析引擎。Logstash和Beats有助于收集,聚合和丰富你的数据并将其存储在Elasticsearch中。使用Kibana,你可以交互式地探索,可视化和共享对数据的见解,并管理和监视堆栈。Elasticsearch是发生索引,搜索和分析数据的地方。
Elasticsearch为所有类型的数据提供近乎实时的搜索和分析。
1.1 ES支持的数据类型
结构化文本
非结构化文本
数字数据
地理空间数据


1.2 文档元数据
_all 字段在7.0版本中已被废除
_version 为了解决在大量并发写入时候文档冲突问题
_score 用于标识在一次查询结果中某条数据和希望查询到的目标的相似度

1.3 索引

1.4 Type
在 7.0 之前,一个 Index 可以设置多个 Types 7.0 开始一个索引只能建立一个 Type:
_doc
1.5 Elasticsearch 和关系型数据库的比较

1.6 增删改查(RD使用)
要增删改查 Elasticsearch 的中数据,需要使用 REST API

2.单机ES部署
2.1 配置ESyum仓库
(一)导入Elasticsearch GPG密钥
# rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
(二)在/etc/yum.repos.d/下创建elasticsearch.repo文件写入
[elasticsearch]
name=Elasticsearch repository for 7.x packages
baseurl=https://artifacts.elastic.co/packages/7.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=0
autorefresh=1
type=rpm-md启用ES并安装下载:
# yum install --enablerepo=elasticsearch elasticsearch
2.2 使用`systemd运行Elasticsearch(ES)
# systemctl daemon-reload
# systemctl enable elasticsearch.serviceElasticsearch可按以下方式启动和停止:
# systemctl start elasticsearch.service
# systemctl stop elasticsearch.service
3.ES(Elasticsearch)集群部署
Elasticsearch 是一个分布式、RESTful 风格的搜索和数据分析引擎,能够解决不断涌现出的各种用例。 作为 Elastic Stack 的核心,它集中存储您的数据,帮助您发现意料之中以及意料之外的情况。
3.1 ES 集群基本概念
集群的特性:
Elasticsearch 集群是一个多节点组成的高可用可扩展的分布式系统
集群中的节点角色 :
Master-eligible Node 和 Master Node
Date Node 和 Coordinating Node
分片 :
主分片和副本
分片分布示例 :
分片的设定 :
主分片是在一开始建立索引时候设置的,后期无法更改生产中要做好数据容量规划。
分片过少 后期如果数量量不断增多,也无法通过增加节点来实现水平扩展 也会导致单个分片存储数据量过多,在以后数据重新分配时耗时。
分片过多 假如长期分片过多,会影响查询结果的相关性打分,从而影响查询结果的准确性 单节点上存放过多的分片会造成资源的浪费,也会影响性能





3.2 ES集群部署
部署的方式为二进制和rpm结合版本
(一)集群环境
集群最少 3 个节点, 集群的每个节点都需要使用非 root 用户(二进制方式)启动。
1 在每个节点上修改安装主目录的属主和属组 :
#二进制
chown -R ela.ela /usr/local/elasticsearch-7.10.02 在每个节点上设置系统内核参数 :
设置内存映射
sysctl -w vm.max_map_count=262144 > /etc/sysctl.conf
sysctl -p还需要设置关于这个进程可以打开的文件描述符数量
3 不同的版本依赖不同版本的 Java :

(二)二进制方式
官方链接:https://www.elastic.co/cn/support/matrix#matrix_jvm
1 下载二进制压缩包:
#二进制
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.10.0-linux-x86_64.tar.gz程序的主目录会是:
/usr/local/elasticsearch-7.10.0这里假设变量
ES_HOME的值是/usr/local/elasticsearch-7.10.0, 此变量将会在下文以及以后的文章中使用。2 目录结构介绍 :
3 在每个节点创建用户 ela :
#二进制
useradd ela4 在每个节点上对 ela 用户授权 :
#二进制
chown -R ela.ela /usr/local/elasticsearch-7.10.05 在每个节点设置如下集群参数 :
默认情况下 Elasticsearch 会使用:
$ES_HOME/config/elasticsearch.yml作为配置文件启动进程。编译配置文件
/usr/local/elasticsearch-7.10.0/config/elasticsearch.yml并添加如下内容:ela1 节点 设置的内容如下:
cluster.name: elk
node.name: ela1 #s
node.data: true
network.host: 0.0.0.0
http.port: 9200discovery.seed_hosts: #官方指定写法如下,3台机器一样
- ela1 #节点1主机名称
- 192.168.122.106:9300 #节点2的ip加端口
- 192.168.122.218 #节点3的ip
cluster.initial_master_nodes: ["ela1", "ela2", "ela3"]ela2 节点设置的内容如下:
cluster.name: elk
node.name: ela2
node.data: true
network.host: 0.0.0.0
http.port: 9200discovery.seed_hosts:
- ela1
- 192.168.122.106:9300
- 192.168.122.218
cluster.initial_master_nodes: ["ela1", "ela2", "ela3"]ela3 节点设置的内容如下:
cluster.name: elk
node.name: ela3
node.data: true
network.host: 0.0.0.0
http.port: 9200discovery.seed_hosts:
- ela1
- 192.168.122.106:9300
- 192.168.122.218
cluster.initial_master_nodes: ["ela1", "ela2", "ela3"]参数说明 :
注意:
cluster.name 集群名称,各节点配成相同的集群名称。
node.name 节点名称,各节点配置不同。
node.data 指示节点是否为数据节点。数据节点包含并管理索引的一部分。
network.host 绑定节点IP。
http.port 监听端口。
path.data 数据存储目录。
path.logs 日志存储目录。
discovery.seed_hosts 指定集群成员,用于主动发现他们,
所有成员都要写进来,包括自己,每个节点中应该写一样的信息。cluster.initial_master_nodes 指定有资格成为 master 的节点
http.cors.enabled 用于允许head插件访问ES。
http.cors.allow-origin 允许的源地址。
当您为提供自定义设置时
network.host,Elasticsearch会假设您正在从开发模式过渡到生产模式,并将许多系统启动检查从警告升级到异常。
cluster.initial_master_nodes中的节点名称需要和node.name的名称一致。

(三)启动集群
在每个节点上启动 elasticsearch 进程
注意:yum方式直接启动服务即可,以下为二进制方式的启动
切换到普通用户 ela,yum安装的直接使用systemctl start elasticsearch启动。
# su - ela
执行如下命令:
# cd /usr/local/elasticsearch-7.10.0
# ./bin/elasticsearch -d -p /tmp/elasticsearch.pid
-d后台运行-p指定一个文件,用于存放进程的 pid默认端口号是 :
注意:如果集群配置错误,想重新初始化集群,只需要删除数据目录,重启服务即可
9200用于外部访问的监听端口,比如查看集群状态,向其传输数据,查询数据等
9300用户集群中节点之间的互相通信,比如主节点的选举,集群节点信息的通告等。
(四)日志
日志消息可以在$ES_HOME/logs/目录中找到YUM安装的日志:cat /var/log/elasticsearch/elasticsearch.log
假如启动失败,从这个日志中查询报错信息
(五)查看集群健康状态
# curl -X GET "localhost:9200/_cat/health?v"三种不同状态的含义 :
黄色 如果您仅运行单个Elasticsearch实例,则集群状态将保持黄色。单 节点群集具有完整的功能,但是无法将数据复制到另一个节点以提供弹性。
绿色 副本分片必须可用,群集状态为绿色。
红色 如果群集状态为红色,则某些数据不可用。

(六)查看集群节点信息
# curl -X GET "localhost:9200/_cat/nodes?v"

3.3 关闭 Elasticsearch 进程
# 二进制方式
# pkill -F /tmp/elasticsearch.pid
3.3 排错
一般报错,常出现之前使用 root 用户启动,之后又使用普通用户启动的情况。 还有集群节点的 IP 地址变化的情况。
# 找到进程
[ela@ela1 elasticsearch-7.10.0]$ jdk/bin/jps
8244 Jps
7526 Elasticsearch# 杀死进程
[ela@ela1 elasticsearch-7.10.0]$ kill -9 7526查看相关日志:
logs/elk.log
根据日志修改相关配置信息
解决完成后执行如下操作
# 删除数据目录中的所有文件
[ela@ela1 elasticsearch-7.10.0]$ rm -rf data/*# 删除日志
[ela@ela1 elasticsearch-7.10.0]$ rm -rf logs/*
# 删除 keystore 文件
[ela@ela1 elasticsearch-7.10.0]$ rm -rf config/elasticsearch.keystore文章来源:https://www.toymoban.com/news/detail-786120.html# 重新启动进程
[ela@ela1 elasticsearch-7.10.0]$ bin/elasticsearch -d -p /tmp/elk.pid文章来源地址https://www.toymoban.com/news/detail-786120.html
到了这里,关于ELK日志分析--ES(Elasticsearch)--(一)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!