Kafka事务
producer可能给多个topic,多个partition发送消息,这些消息组成一个事务,这些消息需要对consumer同时可见或者同时不可见。Kafka事务需要在producer端处理,consumer端不需要做特殊处理,跟普通消息消费一样
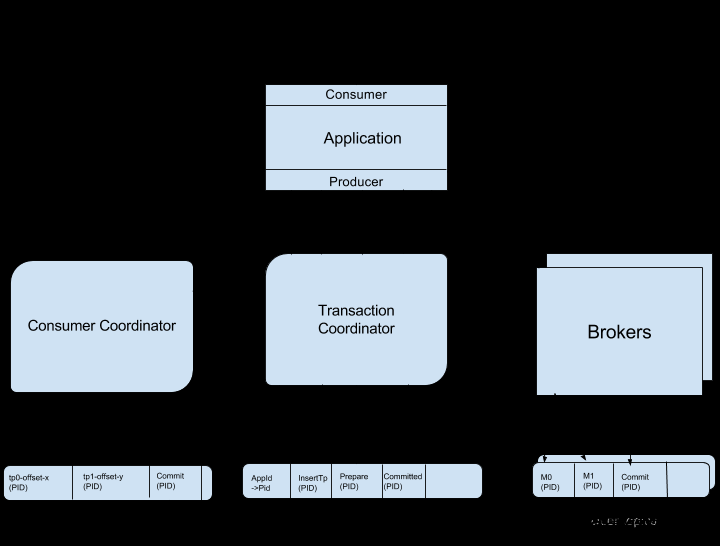
1.事务流程

整个流程步骤:
事务初始化: InitTransactions,事务初始化是一次性的而事务开启、提交/回滚则一致循环运行
开启事务: beginTransaction
发送消息,向n个topic发送多条:producer.send
提交事务: commitTransaction
回滚事务:abortTransaction
2、事务配置
| Producer |
Consumer |
||
|
|
事务ID,类型为String字符串,默认为空,客户端自定义,例如"order_bus" |
|
事务隔离级别,默认为空,开启事务的话,需要将其设置为"read_committed" |
|
|
消息幂等开关,true/false,默认为false,当配置了transactional.id,此项一定要设置为true,否则会抛出客户端配置异常 |
||
|
|
事务超时时间,默认为10秒,最长为15分钟 |
||
当enable.idempotence设置为true时,kafka会检查如下一些级联配置
| 配置项 |
内容要求 |
说明 |
|
|
要求此配置项必须设置为all |
响应必须要设置为all,也就是leader存储消息,并且所有follower也存储了消息后再返回,保证消息的可靠性 |
|
|
> 0 |
因为幂等特性保证了数据不会重复,在需要强可靠性的前提下,需要用户设置的重试次数 > 0 |
|
|
<= 5 |
此项配置是表明在producer还未收到broker应答的最大消息批次数量。该值设置的越大,标识可允许的吞吐越高,同时也越容易造成消息乱序 |
3、事务初始化
参与方:Producer、Broker
事务初始化由producer端触发,执行事务初始化主要做以下两个操作:
a)定位TransactionCoordinator
b)初始化producerId
事务初始化代码:
KafkaProducer<String, String> producer = new KafkaProducer<>(props); producer.initTransactions();
3.1 定位TransactionCoordinator(获取tc)
通过producer发送Coordinator请求(请求中包含自定义transactionid)到broker,broker获取到transactionid做hashcode,hashcode对kafka内部topic _transaction_state默认分区(默认50)取模,获取分区对应的broker作为transactionCoordinator
TransactionCoordinator可以理解为分布式事务中二(三)阶段提交的事务协调者。Kafka事务中TransactionCoordinator本质也是一个broker,只是这个broker起到针对当前事务的协调作用,所有的事务操作都需要直接发送给这个指定的broker
3.2初始化ProducerId(Producer向tc获取)
Producer获取到TransactionCoordinator后,便需要向TransactionCoordinator发送请求获取producerId以及Epoch。可以认为producerId+Epoch是对事务型producer唯一标识。
Producer在事务(初始化阶段)启动之前向TransactionCoordinator申请producerId,TransactionCoordinator服务在分配producerId后会将producerId和Epoch持久到事务topic _transaction_state中,这样就算producer宕机重启后也能处理未完成的事务
后续producer向broker发送请求也需要携带producerid和Epoch,这两个参数含义如下
| 参数 |
类型 |
含义 |
| ProducerId |
Long |
从0开始,对应Producer端配置的TransactionId,他们存在映射关系,可以通过TransactionId来查询ProducerId;映射关系存储在kafka内部topic |
| Epoch |
Short |
从0开始,Producer每次重启,此项值都会+1;当超过short最大值后,ProducerId+1 |
初始化ProducerId后,transactionCoordinator向_transaction_state中写入一条key-value数据(该数据持久化在broker端)此数据key是transactionid,此时事务状态为empty,同时transactionCoordinator向producer返回producerId和Epoch。transactionCoordinator向_transaction_state存储的数据格式如下:
| Key |
Value |
||
| TransactionId |
producerId |
8 |
从0开始,依次递增 |
| epoch |
2 |
从0开始,依次递增 |
|
| transactionTimeoutMs |
4 |
事务超时时间,默认10秒,最大15分钟 |
|
| transactionStatus |
1 |
事务状态( 0-Empty 事务刚开始时init是这个状态 1-Ongoing 2-PrepareCommit 3-PrepareAbort 4-CompleteCommit 5-CompleteAbort 6-Dead 7-PrepareEpochFence ) |
|
| topicTotalNum |
4 |
当前事务关联的所有topic总和 |
|
| topicNameLen |
2 |
topic长度 |
|
| topicName |
X |
topic内容 |
|
| partitionNum |
4 |
partition的个数 |
|
| partitionIds |
X |
例如有n个partition,X = n * 4,每个partition占用4 byte |
|
| transactionLastUpdateTimestampMs |
8 |
最近一次事务操作的更新时间戳 |
|
| transactionStartTimestampMs |
8 |
事务启动的时间戳 |
|
4、事务启动
参与方:Producer
producer.beginTransaction();
5、事务消息发送
参与方:Producer、 broker
producer.send()
5.1 消息发送-Producer
Producer在接收到producerId后就可以正常发送消息,不过在发送消息前,需要将这些消息的分区地址上传到transactionCoordinator。transactionCoordinator会将这些分区地址持久化到事务topic _transaction_state(持久化这些消息分区作用是为了后边6.2节中事务提交阶段知道该事务涉及到的所有分区,为每个分区生成提交请求,存到队列里等待发送).;
之后Producer便可以向对应分区发送消息
5.2 消息发送-TransactionCoordinator
消息发送阶段,TransactionCoordinator主要记录当前事务消息所在分区信息,即更新_transaction_state状态
5.3 消息发送 - broker
消息发送时,broker工作是维护LSO(log stable offset),一个分区可能存储了多个事务消息,也有可能存储多个非事务普通消息,而LSO为第一个正在进行中的事务消息的offset
如下图:

6、事务提交
参与方:Producer、Broker
producer.commitTransaction()
6.1事务提交-Producer
事务提交阶段,producer只是触发提交动作,并携带以下所需参数:
transactionId:事务Id,即客户自定义字符串
producerId:由transaction Coordinator生成,递增
epoch:transaction Coordinator生成,递增
committed:true
6.2 事务提交 - transactionCoordinator
producer提交事务——>TransactionCoordinator收到后,请求将状态修改为PrepareCommit——>TransactionCoordinator向Producer响应——>TransactionCoordinator向各个broker发送control marker消息,broker收到后将消息存储下来,用来比较当前事务已经成功提交——>待各个broker存储control marker后,coordinator将事务状态改为commit,事务结束
7、事务取消
参与方:producer、transactionCoordinator
producer.abortTransaction()
7.1 事务取消-producer
事务取消阶段,producer只是触发取消动作,并携带以下所需参数:
transactionId:事务Id,即客户自定义字符串
producerId:由transaction Coordinator生成,递增
epoch:transaction Coordinator生成,递增
committed:false文章来源:https://www.toymoban.com/news/detail-786384.html
7.2 事务取消-TransactionCoordinator
事务取消除了由Producer触发外,还有可能由Coordinator触发,例如“事务超时”,Coordinator有个定时器,定时扫描那些已经超时的事务文章来源地址https://www.toymoban.com/news/detail-786384.html
8、示例代码
8.1 producer
package com.example.demo.transaction;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import java.util.Properties;
import java.util.concurrent.Future;
public class TransactionProducer {
private static Properties getProps(){
Properties props = new Properties();
props.put("bootstrap.servers", "47.52.199.53:9092");
props.put("retries", 2); // 重试次数
props.put("batch.size", 100); // 批量发送大小
props.put("buffer.memory", 33554432); // 缓存大小,根据本机内存大小配置
props.put("linger.ms", 1000); // 发送频率,满足任务一个条件发送
props.put("client.id", "producer-syn-2"); // 发送端id,便于统计
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("transactional.id","producer-1"); // 每台机器唯一
props.put("enable.idempotence",true); // 设置幂等性
return props;
}
public static void main(String[] args) {
KafkaProducer<String, String> producer = new KafkaProducer<>(getProps());
// 初始化事务
producer.initTransactions();try {
Thread.sleep(2000);
// 开启事务
producer.beginTransaction();
// 发送消息到producer-syn
producer.send(new ProducerRecord<String, String>("producer-syn","test3"));
// 发送消息到producer-asyn
Future<RecordMetadata> metadataFuture = producer.send(new ProducerRecord<String, String>("producer-asyn","test4"));
// 提交事务
producer.commitTransaction();
}catch (Exception e){
e.printStackTrace();
// 终止事务
producer.abortTransaction();
}
}
}8.2 producer+consumer
package com.example.demo.transaction;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import java.util.Properties;
import java.util.concurrent.Future;
public class TransactionProducer {
private static Properties getProps(){
Properties props = new Properties();
props.put("bootstrap.servers", "47.52.199.53:9092");
props.put("retries", 2); // 重试次数
props.put("batch.size", 100); // 批量发送大小
props.put("buffer.memory", 33554432); // 缓存大小,根据本机内存大小配置
props.put("linger.ms", 1000); // 发送频率,满足任务一个条件发送
props.put("client.id", "producer-syn-2"); // 发送端id,便于统计
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("transactional.id","producer-1"); // 每台机器唯一
props.put("enable.idempotence",true); // 设置幂等性
return props;
}
public static void main(String[] args) {
KafkaProducer<String, String> producer = new KafkaProducer<>(getProps());
// 初始化事务
producer.initTransactions();try {
Thread.sleep(2000);
// 开启事务
producer.beginTransaction();
// 发送消息到producer-syn
producer.send(new ProducerRecord<String, String>("producer-syn","test3"));
// 发送消息到producer-asyn
Future<RecordMetadata> metadataFuture = producer.send(new ProducerRecord<String, String>("producer-asyn","test4"));
// 提交事务
producer.commitTransaction();
}catch (Exception e){
e.printStackTrace();
// 终止事务
producer.abortTransaction();
}
}
}到了这里,关于关于Kafka事务处理的详细讲解的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!