大家想了解更多大数据相关内容请移驾我的课堂:
大数据相关课程
剖析及实践企业级大数据
数据架构规划设计
大厂架构师知识梳理:剖析及实践数据建模
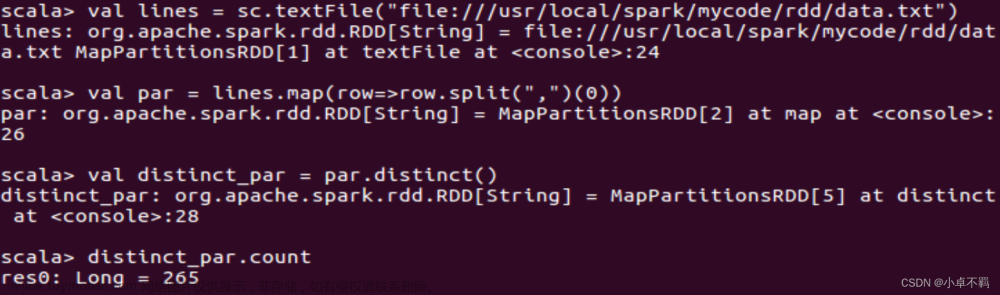
PySpark避坑系列第二篇,该篇章主要介绍spark的编程核心RDD,RDD的概念,基础操作
一、什么是RDD
1.1 概念
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,代表一个不可变、可分区、里面的元素可并行计算的集合。
所有的运算以及操作都建立在 RDD 数据结构的基础之上。
可以认为RDD是分布式的列表List或数组Array,抽象的数据结构
1.2 为什么需要RDD
分布式计算需要:
• 分区控制
• Shuffle控制
• 数据存储\序列化\发送
• 数据计算API
• 等一系列功能文章来源:https://www.toymoban.com/news/detail-786387.html
这些功能, 不能简单的通过Python内置的本地集合对象(如文章来源地址https://www.toymoban.com/news/detail-786387.html
到了这里,关于Spark避坑系列二(Spark Core-RDD编程)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!