大家好,我是程序员晓晓~
本期给大家分享一下如何用python获取微博热搜榜信息,包含爬取时间、序号、关键词、热度等信息,希望对大家有所帮助。
所有内容仅供参考,不做他用。
1. 网页分析
目标网址(微博热搜榜):
https://s.weibo.com/top/summary
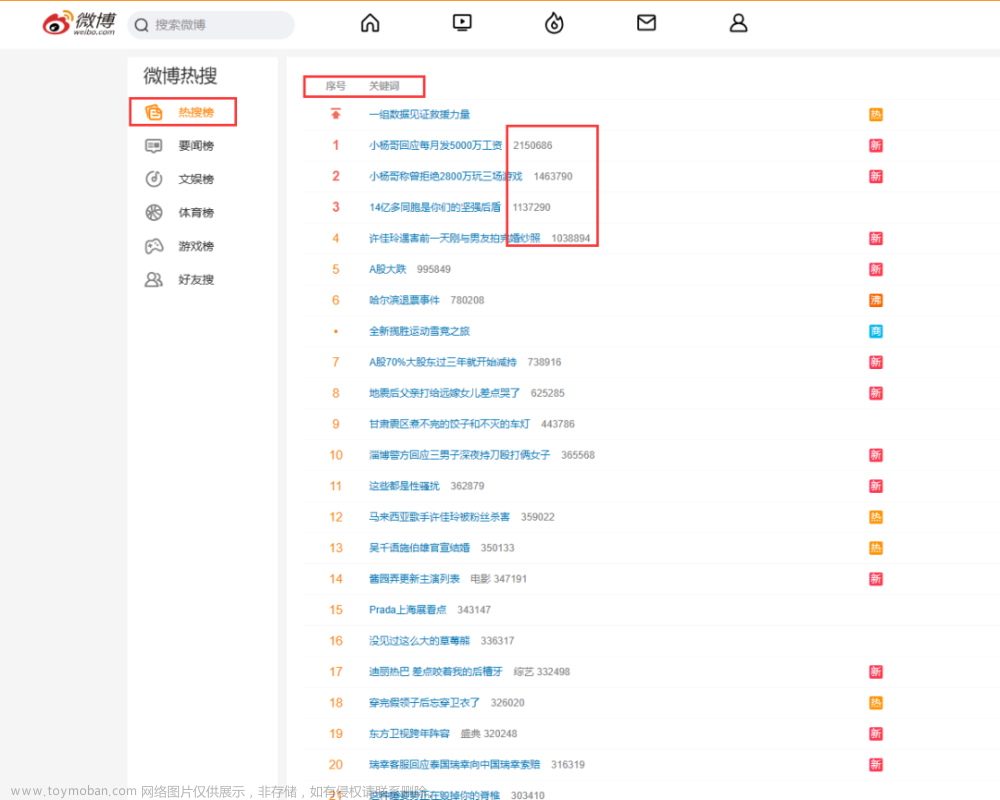
实时热搜榜一共有50条,每个时刻可能都不一样(实时榜单)。
接下来,按 F12 或者右键选择审查元素,以第一个小杨哥发工资回应为例搜索一下:
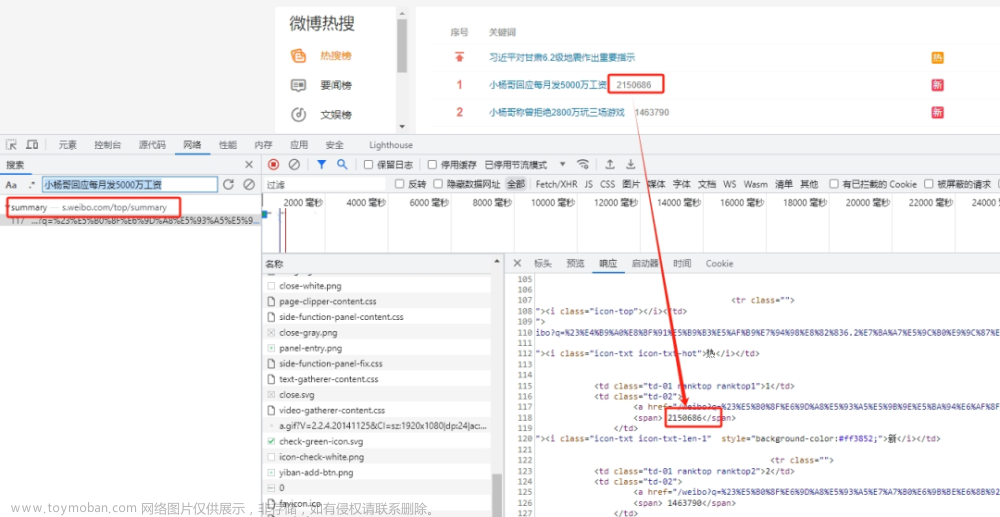
这里我们可以看到相应的热度数据以及具体链接。
继续搜索其他元素:
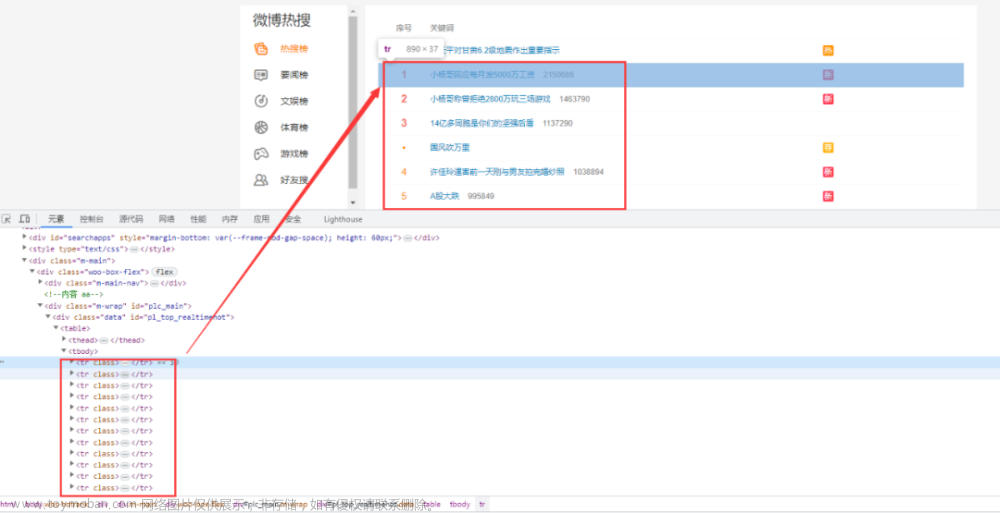
发现实际上这个热搜榜的信息在网页中是以表格(Table)的形式展现的。
2. 爬取数据
2.1 导入模块
import time
import requests
import pandas as pd
2.2 请求网页数据
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36',
}
url = 'https://s.weibo.com/top/summary'
df = getweibodata(url,headers)
2.3 解析数据
time_mow = time.strftime("%Y-%m-%d %H:%M", time.localtime())
df['时间'] = [time_mow] * df.shape[0]
df['排名'] = df['序号'].apply(int)
df['标题'] = df['关键词'].str.split(' ', expand=True)[0]
df['热度'] = df['关键词'].str.split(' ', expand=True)[1]
2.4 保存结果
df = pd.DataFrame(all_data,columns=cols)
df.to_excel('微博热搜榜.xlsx',index=None)

感兴趣的小伙伴,赠送全套Python学习资料,包含面试题、简历资料等具体看下方。
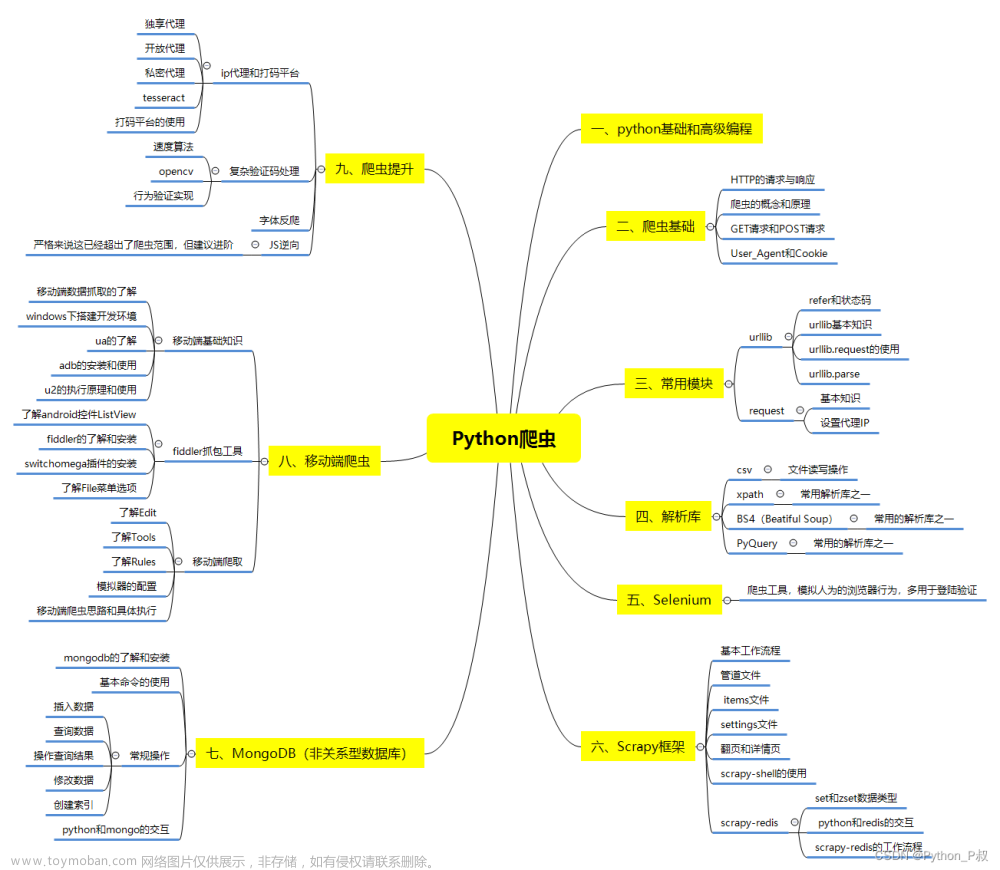
一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。

二、Python必备开发工具
工具都帮大家整理好了,安装就可直接上手!
三、最新Python学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。
四、Python视频合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。
五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
六、面试宝典
 文章来源:https://www.toymoban.com/news/detail-786785.html
文章来源:https://www.toymoban.com/news/detail-786785.html
 文章来源地址https://www.toymoban.com/news/detail-786785.html
文章来源地址https://www.toymoban.com/news/detail-786785.html
简历模板
 若有侵权,请联系删除
若有侵权,请联系删除 到了这里,关于爬虫 | Python爬取微博实时热搜榜信息的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!