大模型微调学习之旅的起点
通过学长的推荐了解到了书生·浦语,现阶段大模型呈井喷式的发展,身为人工智能的学生,感觉不应该局限于简单的调用大模型,而是应该根据实际的需求微调出符合自己情况的大模型,所以就加入了书生·浦语大模型的培训营,接下来让我们开始大模型微调学习之旅!!!
目录
大模型微调学习之旅的起点
前言
一、书生·浦语大模型全链路开源体系是什么?
二、数据
三、预训练
四、微调
五、评测
六、部署
七、智能体
总结
前言
当前的大模型进入了”百模大战“时代,截止到2023.10.8全球已经发布的大模型超200个,中美的数量占全球的九成。2023年大模型突然遍地开花,井喷式发展,尤其是后半年,几乎大部分科技公司、学术团体、研究机构、以及学生团队都在发布各自的大模型,大模型不在是”独家”,它的上手难度和成本在逐步的下降。而大模型的更进一步的发展,那就是开源,这样做会吸引大量的科技公司、学术团体、研究机构等去进行二创,一旦规模达到一定程度,那么就会形成生态。而[书生·浦语」大模型,它就是选择了开源这条路,把所有的内容都开源出来。
想学习的请看链接:
- 书生·浦语大模型全链路开源体系B站讲解
- github链接:GitHub - InternLM/tutorial
- InternLM:InternLM · GitHub
- 书生浦语官网:书生
一、书生·浦语大模型全链路开源体系是什么?
下图为书生·浦语大模型全链路开源体系
- 数据:汇聚 5400+ 数据集,涵盖多种模态与任务
- 预训练:并行训练,极致优化,速度达到 3600 tokens/sec/gpu
- 微调:全面的微调能力,支持SFT,RLHF和通用工具调用
- 部署:全链路部署,性能领先,每秒生成 2000+ tokens
- 评测:全方位评测,性能可复现,50 套评测集,30 万道题目

①数据
OpenDataLab 联合大模型语料数据联盟构建了“书生·万卷”数据集,旨在为学术界及产业界提供更符合主流中文价值对齐的高质量大模型多模态预训练语料。书生·万卷1.0 为书生·万卷多模态语料库的首个开源版本,包含文本数据集、图文数据集、视频数据集三部分,数据总量超过2TB。基于大模型数据联盟构建的语料库,上海AI实验室对其中部分数据进行细粒度清洗、去重以及价值对齐,形成了书生·万卷1.0,具备多元融合、精细处理、价值对齐、易用高效等四大特征。
目前,书生·万卷1.0已被应用于书生·多模态、书生·浦语大模型的训练。通过对高质量语料的“消化”,书生系列模型在语义理解、知识问答、视觉理解、视觉问答等各类生成式任务表现出的优异性能。
书生·万卷1.0数据集


②预训练
①什么是大模型的预训练
大模型预训练是指在海量数据上预先训练一个深度神经网络模型,然后再在特定任务上微调该模型,以获得更好的性能。其目的是通过在不同的语境下学习语言的表示,以便在特定任务上更好地理解和处理文本。预训练的模型通常包含在机器学习框架中,并由研究人员或工业界专家进行训练。
预训练官方文档

③微调
①首先我们要明白什么是大模型微调:
1. 大模型微调是指对已经训练好的大型深度学习模型进行微调,以适应新的任务或数据集。微调是使用少量目标领域的样本数据进行训练,以优化模型在特定任务上的性能。微调的目的是使大模型适应特定任务和数据分布,以提高模型的表现。
2. 在实际应用中,往往需要对预训练模型进行微调,以提高模型的准确性和泛化能力。微调的方法有很多种,如fine-tuning、domain adaptation和transfer learning等。在进行微调时,需要注意数据预处理、优化算法等多个领域的知识,并需要对实验结果进行分析和调整。
②为什么使用通常推荐微调而不是全调
- 提高效率:预训练模型已经在大量通用数据上进行了训练,因此其包含了许多通用的特征和知识。通过微调,我们可以利用这些已经学到的知识,而不需要从头开始训练。这可以大大减少训练时间和计算资源。
- 提高模型性能:预训练模型在通用数据上的训练已经使其具有了一定的泛化能力。在此基础上进行微调,可以进一步使模型适应特定任务的数据分布,从而提高模型在新任务上的性能。
- 加速收敛速度:由于预训练模型已经学习到了通用的特征,对其进行微调可以使模型更快地收敛,即更快地找到最优解。
- 更重要的是硬件设施问题,我们大多数的学生或微小型企业是支付不起硬件设施,所以微调便是最好的选择。
③微调包括什么
1. 微调包括增量续训和有监督微调。增量续训主要用于让基座模型学习到一些新知识,如某个垂类领域知识文章、书籍、代码等;有监督微调主要用于让模型学会理解和遵循各种指令,或者注入少量领域知识,如高质量对话、问答数据。
④通常使用的微调算法
1. 通常使用的微调算法包括Prefix Tuning、Prompt Tuning、P-tuning等。这些算法通过调整输入序列的方式,引导模型生成文本或答案,从而提高模型的生成能力和泛化能力。这些算法在零样本和少样本学习任务中表现出良好的性能。上海人工智能实验室为支持各类主流模型微调,也开源了xtuner项目,参考链接:xtuner大模型微调



④评测
大模型评测是评估大模型性能的重要环节,主要包括以下几个方面:
- 准确性评测:通过使用标准数据集来测试模型在各种任务上的准确性,是评估大模型性能最直观的指标。
- 鲁棒性评测:主要是测试模型在各种噪声、异常输入或对抗性攻击下的表现,以评估模型的稳定性和可靠性。
- 训练时间评测:评估模型训练所需的时间,以了解模型的可扩展性和效率。
- 推理时间评测:测试模型进行推理或生成答案所需的时间,以评估模型在实际应用中的响应速度。
- 内存占用评测:评估模型在内存中的大小,以了解模型对硬件资源的需求和限制。
- 可解释性评测:评估模型的可解释性和透明度,以确保模型做出的决策是合理的并且可以信任的。
OpenCompass是一个开源的大模型评测平台,由上海人工智能实验室推出。它支持大语言模型、多模态模型各类模型的一站式评测,通过零样本评测、小样本评测和思维链评测,全方位量化模型各个维度能力。OpenCompass通过完整开源可复现的评测框架,定期公布评测结果榜单,旨在促进大模型研究的交流和进步。
opencompass地址


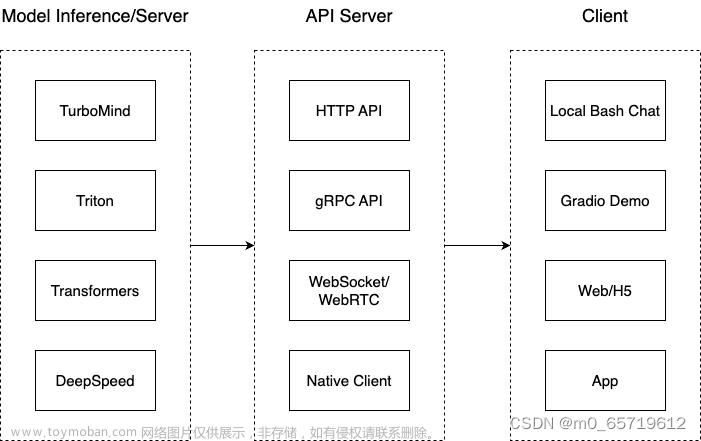
⑤部署
针对大语言模型内存开销巨大、庞大的参数量、采用自回归生成token、需要缓存k/v、动态Shaps、请求数不固定、逐个生成数量不定token、transformer结构特点。如何加速token的生成速度?如何解决动态shape,让推理可以不间断?如何有效管理和利用内存服务?如何提升系统整体吞吐量?如何降低请求的平均响应时间?
上海人工智能实验室结合模型并行技术、低比特量化技术、Atterntion优化技术、计算和访存优化技术、Continuous Batching技术,有效解决上述问题,推出高效推理引擎LMDeploy开源项目。具体的,大模型项目如何高效推理部署。可参考开源项目:
LMDeploy大模型高效推理部署

⑥智能体
①首先介绍一下什么是智能体
1. 什么是Agent?Agent一词起源于拉丁语中的Agere,意思是“to do”。在LLM语境下,Agent可以理解为在某种能自主理解、规划决策、执行复杂任务的智能体。Agent并非ChatGPT升级版,它不仅告诉你“如何做”,更会帮你去做。如果CoPilot是副驾驶,那么Agent就是主驾驶。
一个设置了一些目标或任务,可以迭代运行的大型语言模型
2. Agent(智能体) = 一个设置了一些目标或任务,可以迭代运行的大型语言模型。 这与大型语言模型(LLM)在像ChatGPT这样的工具中“通常”的使用方式不同。 在ChatGPT中,你提出一个问题并获得一个答案作为回应。 而Agent拥有复杂的工作流程,模型本质上可以自我对话,而无需人类驱动每一部分的交互。
大模型应用方面,上海人工智能实验室推出两个开源项目:轻量级智能体Lagent,多模态智能体工具箱AgentLego。
Lagent是一个轻量级的开源框架,允许用户高效地构建基于大型语言模型(LLM)的代理。
AgentLego链接



总结
有了上述对书生·浦语大模型全链路开源体系,接下来就让我们一起开始大模型微调之旅!!!
参考链接:
书生·浦语大模型全链路开源体系-CSDN博客
Agent: 智能体系统的介绍 - 知乎 (zhihu.com)
多模态语料库 “书生·万卷” 1.0 详细解读 | 附下载地址 - 知乎 (zhihu.com) 文章来源:https://www.toymoban.com/news/detail-786972.html
大模型的背景与现状问题 - 知乎 (zhihu.com) 文章来源地址https://www.toymoban.com/news/detail-786972.html
到了这里,关于大模型微调学习之旅① — 书生·浦语大模型全链路开源体系的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!



![[书生·浦语大模型实战营]——XTuner 大模型单卡低成本微调](https://imgs.yssmx.com/Uploads/2024/01/808781-1.png)







