1、流水线简介
概念
所谓流水线设计实际上是把规模较大、层次较多的组合逻辑电路分为几个级,在每一级插入寄存器组并暂存中间数据。
K级的流水线就是从组合逻辑的输入到输出恰好有K个寄存器组(分为K 级,每一级都有一个寄存器组),上一级的输出是下一级的输入而又无反馈的电路。
流水线本质上可以理解为一种以面积换性能( Trade Area for Performance )、以空间换时间( Trade Space for Timing )的手段
流水线设计在性能上的提高是以消耗较多的寄存器资源为代价的。 流水线处理是提高组合逻辑设计的处理速度和吞吐量的最常用手段。
MIPS五级流水线简单介绍

在此流水线中一条指令的生命周期分为如下步骤 。
(1)取指 IF(Instruction Fetch )
- 指令取指是指将指令从存储器中读取出来的过程。
(2)译码 ID( Instruction Decode )
- 指令译码是指将从存储器中取出的指令进行翻译的过程。经过 译码之后得到指令需要的操作数寄存器索引,可以使用此索引从通用寄存器组 (Register File, Regfile )中将操作数读出。
(3)执行 EX(Instruction Execute )
- 指令译码之后所需要进行的计算类型都己得知,并且己经从通用寄存器组中读取出 了所需的操作数,那么接下来便进行指令执行。指令执行是指 对指令进行真正运算的过程。 譬如,如果指令是一条加法运算指令,则对操作数进行加法操作;如果是减法运算指令,则进行减法操作。
- 在“执行”阶段的最常见部件为算术逻辑部件运算器( Arithmetic Logical Unit, ALU), 作为实施具体运算的硬件功能单元 。
(4)访存 MEM( Memory Access )
- 存储器访问指令往往是指令集中最重要的指令类型之一, 访存是指存储器访问指令将数据从存储器中读出,或者写入存储器的过程 。
(5)写回 WB( Write-Back )
- 写回是指将指令执行的结果写回通用寄存器组的过程 。 如果是普通运算指令,该结果值来自于“执行”阶段计算的结果:如果是存储器读指令,该结果来自于“访存”阶段从存储器中读取出来的数据。

2、Pipeline的作用
- 提高了性能
- 优化了时序
- 提高吞吐率
Notes:状态机与之相反

3、Pipeline的深度
主任务分割的子任务数量成为流水线深度。
深度越大,每个处理单元越小,每一级流水线内容纳的硬件逻辑便越少,并且每个单元完成子任务的时间越小。
- 在两级寄存器(每一级流水线由寄存器组成)之间的硬件逻辑越少,则意味能够运行到更高的主频。主频越高也意味着流水线的吞吐率越高,从而性能越高,这是流水线加深的正面意义。
- 由于每一级流水线都由寄存器组成,更多的流水线级数要消耗更多的寄存器,以及更多的面积开销。这是流水线加深的负面意义。
- 由于每一级流水线需要进行握手,流水线最后 一级的反压信号可能会一直串扰到最前一级造成严重的时序问题,需要使用 一些比较高级的技巧来解决此类反压时序问题。 这是流水线加深的负面意义。
- 较深的处理器流水线还有一个问题,那就是由于在流水线的取指令阶段无法得知条件跳转的结果是到底跳还是不跳,因此只能进行预测,而到了流水线的末端才能够 通过实际的运算得知该分支是真的该跳还是不该跳。如果发现真实的结果(譬如该 跳〉与之前预测的结果(譬如预测为不跳)不相符,则意味着预测失败,需要将所 有预取的错误指令流全部丢弃掉。重新取正确的指令流,这个过程叫作“流水线冲刷( Pipeline Flush )”。 虽然可以使用分支预测器来保证前期的分支预测尽可能准确, 但是也无法做到万无 一 失。那么,流水线的深度越深,意味着己经预取了更多的错误指令流,需要将其全部抛弃然后重启,不仅白白浪费了功耗,还造成了性能的损失 。 流水线越深,则意味着浪费和损失越严重;流水线越浅,则浪费和损失越少 。 这是流水线加深的另 一个主要的负面意义。
流水线的不同深度皆有其优缺点, 需要根据不同的应用背景进行合理的选择。
4、流水线中的反压
流水线越深,由于每一级流水线需要进行握手,流水线最后一级的反压信号可能会一直串扰到最前一级造成严重的反压 (Back-pressure )时序问题,需要使用一些比较高级的技巧来解决这些时序问题。
- 取消握手:此方法能够杜绝反压的发生,时序表现非常好 。 但是取消握手,即意味 着流水线中的每一级并不会与其下一级进行握手,可能会造成功能错误或者指令丢 失。因此这种方法往往需要配合其他的机制, 譬如重执行( Replay )、预留大缓存等。
- 加入乒乓缓存:加入乒乓缓存( Ping-pong Buffer )是一种用面积换时序的方法,也是在 解决反压的最简单方法 。 通过使用乒乓缓存(有两个表项〉替换掉普通的一级流水线(只 有一个表项〉,可以使得此级流水线向上一级流水线的握手接收信号仅关注乒乓缓存中 是否有一个以上有空的表项即可,而无需将下一级的握手接收信号串扰至上一级 。
- 加入前向旁路缓存:加入前向旁路缓存( Forward Bypass Buffer )也是一种用面积换时序的方法,是在解决反压时的一种非常巧妙的方法 。旁路缓存仅只有一个表项 , 由于增加了这一个额外的缓存表项,可以将后向的握手信号时序路径砍断,但是对前向路径不受影响,因此可以广泛使用于握手接口。
5、流水线中的冲突
处理器的流水线设计中另外 一个问题便是流水线中的冲突( Hazards ),主要分为资源冲突和数据冲突。
(a)资源冲突
资源冲突是指流水线中硬件资源的冲突,最常见的是运算单元的冲突, 譬如除法器需要多个时钟周期才能完成运算。因此在前 一 个除法指令完成运算之前,新的除法指令如果也需 要除法器,则会存在着资源冲突。
(b)数据冲突
数据冲突是指不同的指令之间的操作数存在着数据相关性造成的冲突,常见的数据相关 性如下。
- WAR (Write-After-Read )相关性,又称先读后写相关性:表示“后序执行的指令需要写回的结果寄存器索引”与“前序执行的指令需要读取的源操作数寄存器索引” 相同造成的数据相关性 。 因此从理论上来讲,在流水线中“后序指令”一定不能比和它有 WAR 相关性的“前序指令”先执行,否则“后序指令”先写回了结果至通用寄存器组中,“前序指令”再读取操作数时,就会读到错误的数值。
- WAW (Write-After-Write )相关性,又称先写后写相关性:表示“后序执行的指令需要写回的结果寄存器索引 ”与“前序执行的指令需要写田的结果寄存器索引”相同 造成的数据相关性。因此从理论上来讲,在流水线中“后序指令”一定不能比和它 有 WAW 相关性的“前序指令”先执行,否则“后序指令”先写回了结果至通用寄存器组中,“前序指令”再写回结果至通用寄存器组中就会将其覆盖。
- RAW (Read-After-Write)相关性,又称先写后读相关性:表示“后序执行的指令需 要读取的源操作数寄存器索引 ”与“前序执行的指令需要写回的结果寄存器索引” 相同造成的数据相关性。因此从理论上来讲,在流水线中“后序指令”一定不能比和它有 RAW 相关性的前序指令”先执行,否 则 “后序指令”便会从通用寄存器组中读回错误的源操作数 。
以上的 3 种相关性中,RAW属于真数据相关 。
4、流水线设计实例
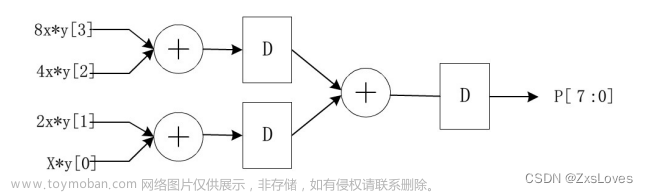
(1)流水线加法器

 文章来源:https://www.toymoban.com/news/detail-787186.html
文章来源:https://www.toymoban.com/news/detail-787186.html
/*----------------------------------------------------------
Filename : adder_pipelined
Author : deilt
Description : two 32bits_adder to 64bits adder
Called by :
Revision History : 10/25/2022
Revison 1.0
Email : cjdeilt@qq.com
Company:Deilt Technology.INC
Copyright(c) 1999, Deilt Technology Inc, All right reserved
--------------------------------------------------------------*/
module adder_pipelined
#(
parameter DATA_WITCH = 64 ,
parameter HALF_DATA_WITCH = 32
)
(
input clk ,
input rstn ,
input [DATA_WITCH-1:0] a ,
input [DATA_WITCH-1:0] b ,
output [DATA_WITCH:0 ] out
);
wire [HALF_DATA_WITCH:0 ] add1 ;
wire [HALF_DATA_WITCH:0 ] add2 ;
reg [HALF_DATA_WITCH:0 ] add1_d1 ;
reg [HALF_DATA_WITCH:0 ] add1_d2 ;
reg [HALF_DATA_WITCH:0 ] add2_d1 ;
reg [HALF_DATA_WITCH-1:0] a_63_32 ;
reg [HALF_DATA_WITCH-1:0] b_63_32 ;
wire add1_carry_d1 ;
assign add1 = a[HALF_DATA_WITCH-1:0] + b[HALF_DATA_WITCH-1:0] ;
assign add1_carry_d1 = add1_d1[HALF_DATA_WITCH] ;
assign add2 = a_63_32 + b_63_32 + add1_carry_d1 ;
assign out = {add2_d1,add1_d2} ;
always @(posedge clk or negedge rstn)begin
if(!rstn)begin
add1_d1 <= 0 ;
add2_d1 <= 0 ;
a_63_32 <= 0 ;
b_63_32 <= 0 ;
add1_d2 <= 0 ;
end
else
add1_d1 <= add1 ;
add1_d2 <= add1_d1;
add2_d1 <= add2 ;
a_63_32 <= a[DATA_WITCH-1:HALF_DATA_WITCH] ;
b_63_32 <= b[DATA_WITCH-1:HALF_DATA_WITCH] ;
end
endmodule
(2)并行加法器

 文章来源地址https://www.toymoban.com/news/detail-787186.html
文章来源地址https://www.toymoban.com/news/detail-787186.html
/*----------------------------------------------------------
Filename : adder_parallel
Author : deilt
Description :
Called by :
Revision History : 10/26/2022
Revison 1.0
Email : cjdeilt@qq.com
Company:Deilt Technology.INC
Copyright(c) 1999, Deilt Technology Inc, All right reserved
--------------------------------------------------------------*/
module adder_parallel
#(
parameter DATA_WITCH = 64
)
(
input clk ,
input rstn ,
input [DATA_WITCH-1:0] a ,
input [DATA_WITCH-1:0] b ,
input alternate ,//low choice adder1,high choice high adder2
output[DATA_WITCH:0] Finalsum
);
reg [DATA_WITCH-1:0] a_d1 ;
reg [DATA_WITCH-1:0] b_d1 ;
reg [DATA_WITCH-1:0] a_alte_d1 ;
reg [DATA_WITCH-1:0] b_alte_d1 ;
wire [DATA_WITCH:0] sum1 ;
wire [DATA_WITCH:0] sum2 ;
reg [DATA_WITCH:0] sum1_d1 ;
reg [DATA_WITCH:0] sum2_d1 ;
//数据输入且alternate为低电平时,选择add1
//数据输入且alternate为高电平时,选择add2
//输出时,alternate为高电平选择sum1,其他选择sum2
always @(posedge clk or negedge rstn)begin
if(!rstn)begin
a_d1 <= 0 ;
b_d1 <= 0 ;
a_alte_d1 <= 0 ;
b_alte_d1 <= 0 ;
end
else if(alternate)begin
a_d1 <= a ;
b_d1 <= b ;
a_alte_d1 <= a_alte_d1 ;
b_alte_d1 <= b_alte_d1 ;
end
else if(!alternate)begin
a_d1 <= a_d1 ;
b_d1 <= b_d1 ;
a_alte_d1 <= a ;
b_alte_d1 <= b ;
end
end
//add1
assign sum1 = a_d1 + b_d1 ;
//add2
assign sum2 = a_alte_d1 + b_alte_d1 ;
//sum delay
always @(posedge clk or negedge rstn)begin
if(!rstn)begin
sum1_d1 <= 0 ;
sum2_d1 <= 0 ;
end
else
sum1_d1 <= sum1 ;
sum2_d1 <= sum2 ;
end
//choice
assign Finalsum = alternate ? sum2_d1 : sum1_d1 ;
endmodule
到了这里,关于verilog实例-流水线(Pipeline)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!