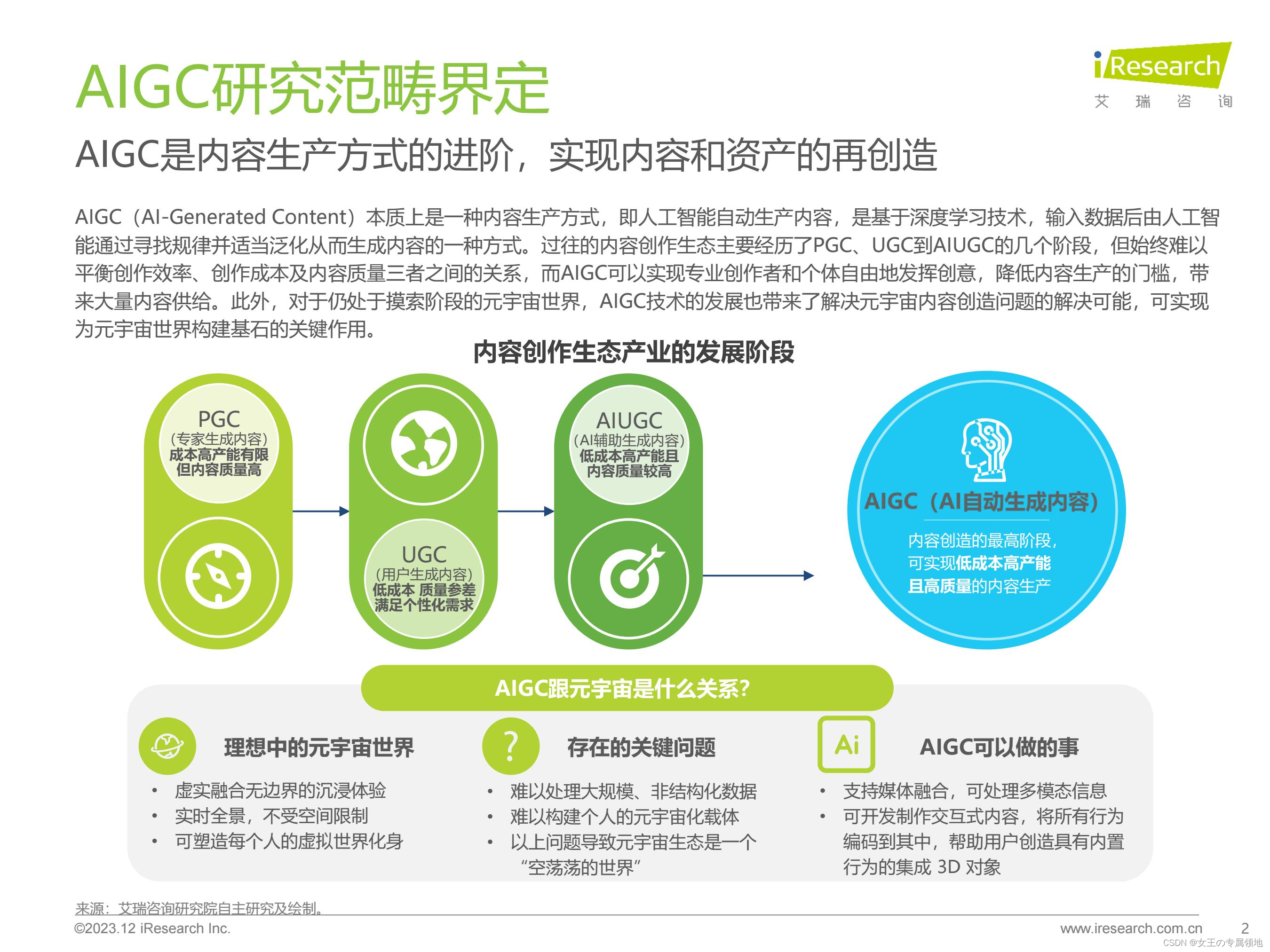
原文:原创 | 一文读懂ChatGPT中的强化学习
ChatGPT基于OpenAI的GPT-3.5创造,是InstructGPT的衍生产品,它引入了一种新的方法,将人类反馈纳入训练过程中,使模型的输出与用户的意图更好地结合。在OpenAI的2022年论文《通过人类反馈训练语言模型以遵循指令》中对来自人类反馈的强化学习(RLHF)进行了深入描述。
创建者将监督学习和强化学习相结合来微调ChatGPT,强化学习组件是ChatGPT的独到之处。研究人员使用了“根据人类反馈强化学习(Reinforcement Learning from Human Feedback ,RLHF)”的特殊技术,在训练环路中使用人类反馈来尽量减少有害的、不真实的和/或有偏差的输出。
该方法包括以下三个步骤:
第一步:带监督的微调,预训练语言模型对由标注人员管理的相对较少的演示数据进行微调,以学习监督策略(SFT模型),根据选定的提示列表生成输出,这表示基线模型;
第二步:“模仿人类偏好” :要求标注人员对相对较多的SFT模型输出进行投票,创建一个由对比数据组成的新数据集。在该数据集上训练一个新的奖励模型(RM);
第三步:近端策略优化(PPO):对奖励模型进一步微调以改进SFT模型。这一步的结果就是所谓的策略模型。
步骤1只进行一次,而步骤2和步骤3可以连续迭代:在当前的最佳策略模型上收集更多的比较数据,训练出一个新的奖励模型,然后在此基础上再训练出一个新的策略。
带监督的微调(SFT)模型
首先是收集演示数据,以训练一个带监督的策略模型,称之为SFT模型。
数据收集:选择一份提示列表,要求一组人工标注人员写下预期的输出响应。ChatGPT使用了两种不同的提示来源:一些是直接从标注人员或开发人员那里获取到的的,一些是从OpenAI的API请求中取样的(即来自GPT-3客户)。整个过程速度缓慢并且代价昂贵,输出结果是一个相对较小的、高质量的管理数据集(大概大约有12-15k个数据点),将利用该数据集微调预先训练的语言模型。
模型选取:开发人员选择了在GPT-3.5系列中选择一个预训练模型,而不是对原来的GPT-3模型进行微调。可使用最新的基线模型——text-davinci-003,这也是一个GPT-3模型,对主要的编程代码进行微调。
由于这一步的数据量有限,在此过程之后获得的SFT模型很可能输出用户不太关注的文本,而且往往会出现错位的问题。这里的问题是,监督学习这一步存在很高的可扩展性成本。
为了克服上述问题,利用人工标记创建一个更大的数据集,这个速度缓慢而代价昂贵的过程,采用一个新的策略,为人工标记的SFT模型输出创建一个奖励模型——在下面的内容中进行更详细的解释。
奖励模型
在步骤1 中训练 SFT 模型后,该模型会对用户提示生成更一致的响应。接下来是训练奖励模型,其中模型输入是一系列提示和响应,输出是一个缩放值,称为奖励。需要奖励模型以利用强化学习,在强化学习中模型学习产生输出以最大化其奖励。
直接从数据中学习出一个目标函数(奖励模型)。这个函数的目的是给SFT模型的输出给出一个分值,这一分值与人类对输出的可取程度成比例。在实践中,这将反映出选定的标记人员群体的具体偏好和他们同意遵循的准则。最后,这一过程将从数据中提取出一个模仿人类偏好的自动回答系统。其工作原理如下:
-
选择一个提示列表,SFT模型为每个提示生成多个SFT 模型输出(在4个到9个之间);
-
标注人员将输出从好到坏进行排序,结果是生成一个新的标记数据集,其中的排名是标记。这个数据集的大小大约是SFT模型数据集的10倍;
-
利用这些新数据训练一个奖励模型(RM)。该模型将某些SFT模型输出作为输入,并根据人类偏好对它们进行排序。
对于标注者来说,对输出进行排序比从头开始生成它们要容易得多,因此这个过程的缩放效率会更高。在实践中,从30-40k个提示符(prompts)中生成一个数据集,要求将这些输出从最好到最差进行排名,创建输出排名组合。在排名阶段,将不同标注的输出呈现给不同的提示符。
利用近端策略优化(PPO)算法微调SFT模型
接下来,利用强化学习微调SFT策略,让它优化奖励模型。模型会收到随机提示并返回响应。响应是使用模型在步骤2 中学习的“策略”生成的。策略表示机器已经学会使用以实现其目标的策略;在这种情况下,最大化其奖励。基于在步骤 2 中开发的奖励模型,然后为提示和响应对确定缩放器奖励值。然后奖励反馈到模型中以改进策略。所使用的算法为近端策略优化(PPO)算法,而微调后的模型称为PPO模型。
2017年,舒尔曼等人。引入了近端策略优化 (PPO),该方法用于在生成每个响应时更新模型的策略。PPO 包含来自 SFT 模型的每个代币 Kullback–Leibler (KL) 惩罚。KL 散度衡量两个分布函数的相似性并对极端距离进行惩罚。在这种情况下,使用 KL 惩罚会减少响应与步骤 1 中训练的 SFT 模型输出之间的距离,以避免过度优化奖励模型和与人类意图数据集的偏差太大。PPO算法的具体实现已经在前文4.4 节中进行了描述,这种方法的要点:
-
PPO是一种用于训练强化学习中智能体的算法,为策略算法,正如DQN(深度q网络)等算法一样,它直接从当前策略中学习和更新策略,而非从过去的经验中学习算法。PPO根据智能体所采取的行动和它所获得的奖励,不断地调整当前的政策;
-
PPO使用置信区间优化方法对策略进行训练,它将策略的变化限制在与先前策略的一定距离内,以确保稳定性。这与其他策略梯度方法相反,其他策略梯度方法有时会对策略进行大量更新,从而使学习不稳定;
-
PPO使用价值函数来估计给定状态或动作的预期回报。利用价值函数计算优势函数,它表示期望回报和当前回报之间的差值,使用优势函数通过比较当前策略所采取的动作与先前策略的本应采取的动作来更新策略,PPO能够根据动作的估计值对策略进行更明智的更新。
在该步骤中,由SFT模型初始化PPO模型,由奖励模型初始化价值函数。该环境是一个强盗环境(bandit environment),它显示一个随机的提示符,并期望对该提示符作出响应。给出提示和反响应之后,会生成奖励(由奖励模型决定)。在每个标注的SFT模型中添加各个标记的KL惩罚,以优化奖励模型。文章来源:https://www.toymoban.com/news/detail-787461.html
结论
ChatGPT引入了强化学习近端策略优化(PPO)算法微调SFT模型,将人类反馈纳入模型训练过程中,从而大幅度提高了模型训练的准确度。文章来源地址https://www.toymoban.com/news/detail-787461.html
到了这里,关于| 一文读懂ChatGPT中的强化学习的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!