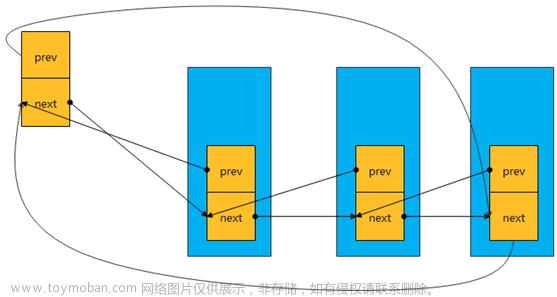
1、list_for_each_entry_safe

这段代码是一个宏定义,用于遍历一个链表中所有的元素,并且在遍历过程中可以安全地删除元素。具体来说,这个宏定义的功能是:
-
遍历链表中所有的元素,从头节点开始,直到尾节点结束。
-
对于每个元素,使用给定的结构体成员变量名找到它所属的结构体对象,并且将该对象的指针赋值给给定的变量名。
-
在遍历过程中,可以安全地删除当前元素,因为它在删除前会先保存下一个元素的指针,保证不会影响遍历的正确性。
下面是这个宏定义的详细解释:
- 参数解释:
- pos:用于保存当前遍历到的元素的指针。
- tmp:用于保存下一个元素的指针,以便在删除当前元素后继续遍历。
- head:链表的头节点。
- member:链表节点所在的结构体成员变量名。
- 宏定义解释:
首先,使用 __container_of 宏定义将头节点的下一个节点转换为链表节点的指针,再使用 __container_of 宏定义将该节点的成员变量 member 转换为其所属的结构体对象,并且将该对象的指针赋值给 pos 变量。
接着,使用 __container_of 宏定义将 pos 的成员变量 member.next 转换为下一个节点的指针,并且将该节点的指针赋值给 tmp 变量。
然后,使用 & 操作符判断当前节点是否为链表的尾节点。如果不是尾节点,就执行循环体中的代码,否则跳出循环。
在循环体中,首先将 tmp 的成员变量 member.next 转换为下一个节点的指针,并且将该节点的指针赋值给 tmp 变量,以便在删除当前节点后继续遍历。
然后,执行用户自定义的代码,该代码可以访问当前节点所属的结构体对象,并且可以安全地删除当前节点。
举例说明:
假设有一个链表,链表节点的结构体定义如下:
struct my_node {
int data;
struct list_head list;
};
其中,list 是链表节点的成员变量名。如果要遍历该链表并且可以安全地删除节点,可以使用 list_for_each_entry_safe 宏定义,代码如下:
struct list_head head;
struct my_node *pos, *tmp;
// 遍历链表中的所有元素,并且可以安全地删除元素
list_for_each_entry_safe(pos, tmp, &head, list) {
// 访问当前节点所属的结构体对象
printf(“data = %d\n”, pos->data);
// 安全地删除当前节点
list_del(&pos->list);
free(pos);
}
在上面的代码中,list_del 函数用于删除当前节点,并且在删除前会先保存下一个节点的指针,以保证遍历的正确性。
2、container_of

这是一个非常常见的宏定义,用于从某个结构体成员变量的指针中获取整个结构体的指针。这个宏在内核编程中非常常用,因为内核中经常需要通过成员变量的指针来访问整个结构体的其他成员变量。
宏定义的格式如下:
#define container_of(ptr, type, member) \
(type *)((char *)(ptr) - (char *) &((type *)0)->member)
宏定义了三个参数:
-
ptr:指向某个结构体成员变量的指针; -
type:结构体的类型; -
member:结构体中的成员变量名。
宏的实现原理是利用了C语言中的指针算术运算和结构体的内存布局。在结构体中,每个成员变量的地址相对于结构体的起始地址都是固定的。因此,我们可以通过计算某个成员变量相对于结构体起始地址的偏移量,来计算出整个结构体的地址。
宏定义的实现步骤如下:
- 将0强制转换为
type类型的指针; - 取出
member成员变量的地址; - 用指向该成员变量的指针减去该员变量在结构体中的偏移量,得到整个结构体的起始地址;
- 将该地址强制转换为
type类型的指针,并返回。
例如,假设有一个结构体struct my_struct,其中包含一个成员变量int my_field。如果我们有一个指向my_field的指针int *ptr,我们可以使用container_of宏来计算整个结构体的地址:
struct my_struct *s = container_of(ptr, struct my_struct, my_field);
这样,指针s就指向了包含my_field成员变量的整个结构体。从而我们可以通过s来访问整个结构体的其他成员变量。
举例:
为了更好地理解这个宏的实现原理,我们可以通过一个例子来说明。假设有如下的结构体定义:
struct my_struct {
int a;
int b;
int c;
};
现在我们定义一个指向b成员变量的指针int *ptr,我们想要通过ptr来获取整个结构体的指针。我们可以使用container_of宏来计算整个结构体的地址:
假设我们定义了一个指向b成员变量的指针int *ptr,我们想要通过ptr来获取整个结构体的指针。我们可以使用container_of宏来计算整个结构体的地址:
struct my_struct *s = container_of(ptr, struct my_struct, b);
现在我们来逐步分析一下container_of宏的实现过程:
-
首先,我们将0强制转换为
struct my_struct *类型的指针,得到一个指向结构体的空指针。(struct my_struct *)0 -
然后,我们取出
b成员变量的地址,这可以通过&((struct my_struct *)0)->b来实现。由于我们已经将0强制转换为struct my_struct *类型的指针,因此这个表达式实际上是取出了结构体中b成员变量的地址相对于结构体起始地址的偏移量。&((struct my_struct *)0)->b -
接下来,我们将指向
b成员变量的指针ptr强制转换为char *类型的指针,然后减去上一步中计算出的偏移量。由于指针减法的结果是以指针类型的大小为单位的,因此我们需要将结果强制转换为struct my_struct *类型的指针。(struct my_struct *)((char *)ptr - (char *)&((struct my_struct *)0)->b)这个表达式相当于将
ptr指向的地址向前偏移了b成员变量相对于结构体起始地址的偏移量,从而得到整个结构体的起始地址。 -
最后,我们将上一步中计算出的地址强制转换为
struct my_struct *类型的指针,并返回该指针。(struct my_struct *)((char *)ptr - (char *)&((struct my_struct *)0)->b)这样,我们就得到了一个指向整个结构体的指针,从而可以通过该指针来访问结构体的其他成员变量。
3、list_for_each_entry_rcu

这是一个宏定义,用于在读取RCU(Read-Copy-Update)保护的链表中遍历每个元素。
具体来说,这个宏定义了一个循环,其中:
-
pos是当前元素的指针; -
head是链表头的指针; -
member是链表节点结构体中表示下一个元素的成员变量的名称; -
cond...是可选的条件语句,用于在遍历时进行过滤。
宏定义的实现中,首先调用了一个名为 __list_check_rcu 的函数,用于检查 cond 中是否有语法错误。这个函数的具体实现可以参考 Linux 内核源码中的 include/linux/list.h 文件。
然后,在循环中,首先将 pos 初始化为链表头的下一个元素,即第一个要遍历的元素。这里使用了 list_entry_rcu 宏,将链表节点结构体的指针转换为包含该节点的数据结构的指针,以便于访问该元素的数据。
接着,在循环条件中,检查当前元素的下一个元素是否为链表头,如果是,则说明已经遍历完了整个链表,循环结束。
最后,在循环体中,使用 list_entry_rcu 宏获取当前元素的下一个元素,并将其赋值给 pos,继续循环。这里同样使用了包含节点的数据结构的指针,以便于访问下一个元素的数据。
总之,这个宏定义非常方便地实现了在读取RCU保护的链表中遍历每个元素的功能,而且还支持条件过滤,非常实用。
4、list_last_entry

这是一个宏定义,用于获取链表中最后一个元素的数据结构指针。
具体来说,这个宏定义了三个参数:
-
ptr是链表的指针,表示要获取最后一个元素的链表; -
type是数据结构的类型,表示链表节点所包含的数据结构的类型; -
member是链表节点结构体中表示下一个元素的成员变量的名称。
宏定义的实现中,使用了 list_entry 宏,将链表最后一个节点的指针转换为包含该节点的数据结构的指针。具体来说,宏定义使用了链表最后一个节点的前一个节点的指针 ptr->prev,然后将其转换为包含该节点的数据结构的指针,即 list_entry((ptr)->prev, type, member)。
这个宏定义非常方便地实现了获取链表中最后一个元素的数据结构指针的功能,可以在需要遍历链表时,从最后一个元素开始往前遍历。需要注意的是,这个宏定义假设链表不为空,否则在空链表上调用它将会导致错误。
5、WARN相关
 这些都是 Linux 内核中的宏定义,在处理错误和警告时使用。
这些都是 Linux 内核中的宏定义,在处理错误和警告时使用。
- #define WARN_ON_ONCE(condition) WARN_ON(condition)
这个宏定义表示:如果条件 condition 为真,则打印警告信息。与 WARN_ON() 不同的是,这个宏只会打印一次警告信息,即便 condition 多次为真也只会打印一次。
- #define WARN_ONCE(condition, format…) WARN(condition, format)
这个宏定义表示:如果条件 condition 为真,则打印警告信息。与 WARN() 不同的是,这个宏只会打印一次警告信息,即便 condition 多次为真也只会打印一次。同时,这个宏还可以传入格式化字符串 format,用于打印更详细的警告信息。
- #define WARN_TAINT(condition, taint, format…) WARN(condition, format)
这个宏定义表示:如果条件 condition 为真,则打印警告信息,并将污点标记 taint 与之关联。污点标记是一种标记机制,用于标记内核中的某些数据或操作是不可信的或者有风险的。通过将污点标记与警告信息关联,可以更加精确地追踪和排查问题。
- #define WARN_TAINT_ONCE(condition, taint, format…) WARN(condition, format)
这个宏定义表示:如果条件 condition 为真,则打印警告信息,并将污点标记 taint 与之关联。与 WARN_TAINT() 不同的是,这个宏只会打印一次警告信息,即便 condition 多次为真也只会打印一次。同时,这个宏还可以传入格式化字符串 format,用于打印更详细的警告信息。
6、offset_in_page

这是一个宏定义,定义的作用是计算指针 p 所指向的地址在所在页面中的偏移量。
具体来说,PAGE_SIZE 是一个常量,表示页面的大小,通常为 4KB。而 offset_in_page(p) 宏定义中的 (unsigned long)p 表示将指针 p 转换为一个无符号长整型数,然后对 PAGE_SIZE 取模运算,得到的结果就是指针 p 所指向的地址在所在页面中的偏移量。文章来源:https://www.toymoban.com/news/detail-787626.html
例如,假设 PAGE_SIZE 为 4KB,指针 p 指向地址 0x12345678,那么 offset_in_page(p) 的值就是 0x678,即指针 p 所指向的地址在所在页面中的偏移量为 0x678。这个宏定义通常用于内核中对页面进行操作时,需要计算出页面中某个地址的偏移量,以便进行相应的处理。文章来源地址https://www.toymoban.com/news/detail-787626.html
到了这里,关于【Linux内核】内核常用链表宏解释的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!