在生产环境中,不使用 Apache Kafka 等流平台进行数据迁移并不是一个好的做法。 在这篇文章中,我们将详细探讨 Apache Kafka 和 Logstash 的关系。
但首先让我们简单了解一下 Apache Kafka 的含义。 Apache Kafka 是分布式流平台,擅长实时数据集成和消息传递。
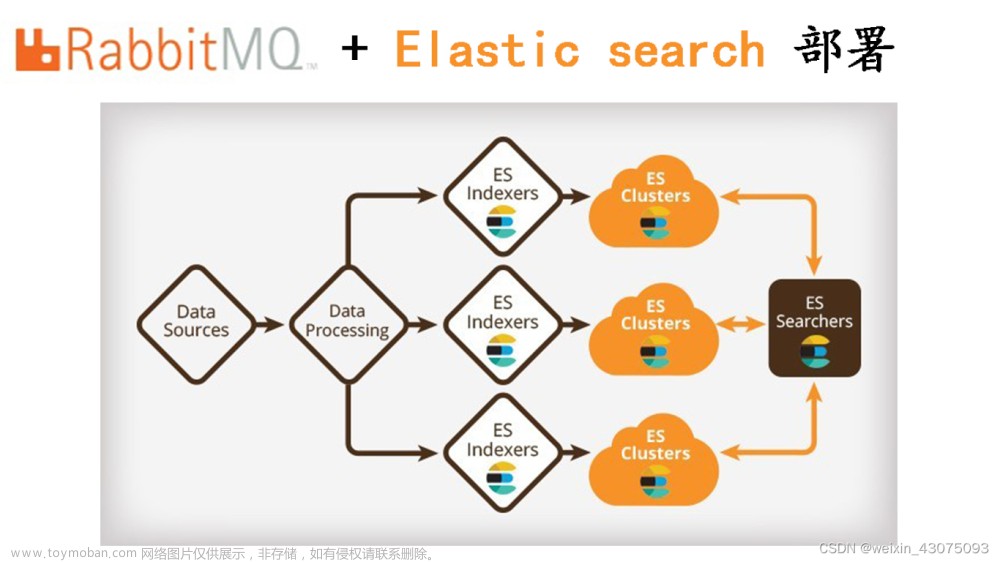
Kafka 架构不复杂且直接。 生产者将给定主题的数据发送到 Kafka Broker; Kafka 集群包含一个或多个 broker,用于存储从生产者接收到的消息,订阅 Kafka 主题的消费者将接收数据。 由于它是一个分布式平台,Zookeeper 有助于管理架构。
- Kafka Producer 是数据的生产者; 它是源头。 它将数据推送到 Kafka 服务器,即 broker。
- 单个 Kafka 服务器称为 Kafka Broker,而 Kafka Broker 的集合称为 Kafka 集群。 Kafka 代理将数据存储在它们运行的服务器磁盘上的目录中。
- Kafka topic 将充当数据流的唯一标识符。 由于多个生产者可以将数据发送到同一个代理,如果消费者想要使用数据,则很难识别。 多个生产者也可以将数据发送到同一 topic。
- Consumers 是消费群体的一部分。 单个 consumer 将读取多个 Kafka topic 的消息。
- Zookeeper 用于元数据管理。 它跟踪哪些代理是 Kafka 集群的一部分。 它还存储主题和权限的配置。

安装并运行 Kafka 实例是测试迁移的必要条件。如果你想了解更多关于 Kafka 的安装知识,请参考:
-
Elastic:Data pipeline:使用 Kafka => Logstash => Elasticsearch
-
Elasticsearch:使用 Logstash 构建从 Kafka 到 Elasticsearch 的管道 - Nodejs
启动 Kafka 的过程围绕以下命令进行。
# To create topic in Kafka.
kafka-topics.bat --create --bootstrap-server localhost:9092 --topic <topic_name>
# To produce data or to ingest data using producer module.
kafka-console-producer.bat --broker-list localhost:9092 --topic <topic_name>
# To see the data in the topic.
kafka-console-consumer.bat --topic <topic_name> --bootstrap-server localhost:9092 --from-beginning注意:在上面显示的命令是针对 Windows 系统的。针对 Linux 系统,这些命令变成了 kafka-console-consumer.sh。
使用下面的配置文件,我们可以使用 JDBC 驱动程序从任何数据库中提取数据,将数据迁移到 Kafka,然后使用 Logstash 从 Kafka 将数据迁移到 Elasticsearch。
我们在 “config” 文件夹中创建管道配置文件来定义 Logstash 的处理阶段。 Logstash 仅加载 “config” 目录中的 “.conf” 文件,而忽略其他文件。 基本配置包括输入、过滤器和输出插件。 输入插件读取源事件,过滤器插件处理事件,输出插件将数据发送到特定目的地
在下面的配置模板中,我们在输入部分使用了 JDBC 插件,在输出部分使用了 Elasticsearch 插件。
Database to Kafka Server : Logstash .conf file.
input
{
id => "jdbc_input"
# path to third party driver library
# replace it with where you placed the driver.
jdbc_driver_library => "/path/to/mysql-connector-java.jar"
# class to load
jdbc_driver_class => "com.microsoft.sqlserver.jdbc.SQLServerDriver"
# Replace the JDBC connection string with your actual database details
jdbc_connection_string => "jdbc:<sqlserverip>://:<port>;databaseName=<DbName>;encrypt=true;trustServerCertificate=true;user=<username>;password=<password>;"
# database Credentials
# replace it with your own credentials.
jdbc_user => "<username>"
jdbc_password => "<password>"
statement => "<SQL STATEMENT>"
}
filter{}
output
{
kafka {
codec => json
# topic created within the Kafka.
topic_id => "mytopic"
bootstrap_servers => "localhost:9092"
}
}Kafka to Elasticsearch : Logstash .conf file
input
{
kafka
{
## decoding the input data
codec => json
## URL of kafka instance to establish initial connection
bootstrap_servers => "<IP_Address>:<Kafka_Port>"
## topics to subscribe to
topics => ["<topic_name>"]
}
}
filter{}
output
{
elasticsearch
{
# index to write the data
index => "index_name"
# Set the host's of the remote instance
hosts => ["<IP_Address>:<Port>"]
}
}迁移程序:
- 首先安装相应的数据库 JDBC 驱动程序并将其保存在你首选位置的 Logstash 文件夹中。
- 接下来,创建一个配置 (.conf) 文件并将其保存在 Logstash 目录中的 “config” 文件夹中。
- 将数据库 JDBC 驱动程序放置在 Logstash 文件夹中,并将配置文件保存在 “config” 文件夹中后,你就可以启动 Logstash。
- 对于 Windows 操作系统,从 “bin” 文件夹中打开命令提示符 (cmd) 并执行以下命令:
# replace the conf_file_name
logstash.bat -f .\config\<conf_file_name>.conf- 同样,对于其他操作系统,执行相同的命令,但确保从 “bin” 文件夹运行它。
# replace the conf_file_name
bin/logstash -f ./config/<conf_file_name>.conf更多关于如何在 Logstash 中配置 JDBC 驱动的文章,请阅读 “Logstash:如何使用 Logstash 和 JDBC 确保 Elasticsearch 与关系型数据库保持同步”。文章来源:https://www.toymoban.com/news/detail-787697.html
结论
在数据迁移领域,Logstash 遇到了它的完美伴侣 --- Apache Kafka。 显然,他们的协同合作提供了强大的解决方案,确保将数据从不同来源无缝高效地传输到 Elasticsearch,从而为组织提供实时洞察力和敏捷性。文章来源地址https://www.toymoban.com/news/detail-787697.html
到了这里,关于Logstash:迁移数据到 Elasticsearch的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!