本文以U-Net举例,演示如何解决张量(Tensor)维度尺寸对不齐的问题
U-Net的网络架构可以参考这篇文章:U-Net原理分析与代码解读
这是本文演示所用的U-Net代码:
class UNet(nn.Module):
def __init__(self):
super(UNet, self).__init__()
# 输入层
self.input_conv = nn.Conv2d(3, 64, kernel_size=3, padding=1)
# 下采样部分
self.down1 = nn.Sequential(
nn.Conv2d(64, 128, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2)
)
self.down2 = nn.Sequential(
nn.Conv2d(128, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2)
)
self.down3 = nn.Sequential(
nn.Conv2d(256, 512, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2)
)
self.down4 = nn.Sequential(
nn.Conv2d(512, 1024, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2)
)
# 桥接层 - 将输出通道数修改为1024,以便与down4_out拼接时通道数一致
self.bridge = nn.Sequential(
nn.Conv2d(1024, 1024, kernel_size=3, padding=1),
nn.ReLU(inplace=True)
)
# 上采样部分 - 调整每个上采样的第一个卷积层输入通道数
self.up1 = nn.Sequential(
nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True),
nn.Conv2d(2048, 1024, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(1024, 512, kernel_size=3, padding=1),
nn.ReLU(inplace=True)
)
self.up2 = nn.Sequential(
nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True),
nn.Conv2d(1024, 512, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(512, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True)
)
self.up3 = nn.Sequential(
nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True),
nn.Conv2d(512, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 128, kernel_size=3, padding=1),
nn.ReLU(inplace=True)
)
self.up4 = nn.Sequential(
nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True),
nn.Conv2d(256, 128, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(128, 64, kernel_size=3, padding=1),
nn.ReLU(inplace=True)
)
# 输出层
self.final_conv = nn.Conv2d(64, NUM_CLASSES, kernel_size=1)
def forward(self, x):
x = self.input_conv(x) # 对原始输入进行处理
down1_out = self.down1(x)
down2_out = self.down2(down1_out)
down3_out = self.down3(down2_out)
down4_out = self.down4(down3_out)
bridge_out = self.bridge(down4_out)
up1_out = self.up1(torch.cat([bridge_out, down4_out], dim=1))
up2_out = self.up2(torch.cat([up1_out, down3_out], dim=1))
up3_out = self.up3(torch.cat([up2_out, down2_out], dim=1))
up4_out = self.up4(torch.cat([up3_out, down1_out], dim=1))
final_out = self.final_conv(up4_out)
return torch.sigmoid(final_out) # 因为是二分类问题,所以输出通过sigmoid激活
假设本文输入的图像是600乘以400像素的尺寸,那么对于本文U-Net代码所需的512乘以512像素的输入是肯定不匹配的。
一、图像缩放
既然输入图像的尺寸与网络所需输入的尺寸不符合,那就将输入图像的尺寸缩放到符合网络所需输入的尺寸就可以了。
在预处理函数中直接对原始图像进行缩放。
本文举例U-Net的所需输入是512乘以512像素,所以直接缩放为512乘以512像素
# 定义预处理函数
def get_transforms():
# 对于图像的transforms
image_transforms_list = [
transforms.Resize((512, 512)), # 缩放至512x512
transforms.ToTensor(),
transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]) # 根据实际数据调整
]
image_transform = transforms.Compose(image_transforms_list)
# 对于mask的transforms(不需要归一化)
mask_transforms_list = [
transforms.Resize((512, 512)), # 缩放至512x512
transforms.ToTensor()
]
mask_transform = transforms.Compose(mask_transforms_list)
return image_transform, mask_transform
二、尺寸裁剪或尺寸填充
由于直接对原始图像进行缩放可能会对丢失一定的原始信息已经可能会扭曲一定的原始信息,所以更加建议使用尺寸裁剪或尺寸填充的方法。
尺寸裁剪或尺寸填充并不是在预处理函数中使用,而是在网络结构的前向传播中使用,因为这时往往只需要改动几个像素点,对原始图像的改动较小。
定义尺寸裁剪或尺寸填充函数:
可以通过修改pad_value来决定用什么数值来填充(建议修改成背景的数值)
import torch.nn.functional as F
def crop_or_pad_tensor(tensor, height_crop, width_crop, pad_value=0):
'''
裁剪或扩展Tensor在高度(仅底部)和宽度(仅右侧)维度上的最后一个像素。
正数表示扩展(用0填充),负数表示裁剪。
参数:
tensor (torch.Tensor): 输入的4维张量,形状为 (batch_size, channels, height, width)
height_crop (int): 高度方向上底部要裁剪或扩展的像素数量,默认为1
width_crop (int): 宽度方向上右侧要裁剪或扩展的像素数量,默认为1
pad_value (float or int): 填充时使用的值,默认为0
返回:
cropped_or_padded_tensor (torch.Tensor): 裁剪或扩展后的张量
'''
assert len(tensor.shape) == 4, '输入的tensor应为4维'
# 获取原始的高度和宽度
original_height, original_width = tensor.shape[2], tensor.shape[3]
# 计算需要裁剪的数量(正值代表不裁剪,负值时代表裁剪)
height_to_remove_from_bottom = min(original_height, -height_crop) if height_crop < 0 else 0
width_to_remove_from_right = min(original_width, -width_crop) if width_crop < 0 else 0
# 计算需要填充的数量(正值代表填充,负值代表不填充)
pad_bottom = abs(height_crop) if height_crop > 0 else 0
pad_right = abs(width_crop) if width_crop > 0 else 0
# 先填充,再裁剪
padded_tensor = F.pad(tensor, pad=(0, pad_right, 0, pad_bottom), mode='constant', value=pad_value)
# 在高度和宽度维度上进行裁剪(如果需要)
if height_to_remove_from_bottom > 0 and width_to_remove_from_right > 0:
# 同时裁剪高度和宽度
cropped_or_padded_tensor = padded_tensor[:, :, :-height_to_remove_from_bottom, :-width_to_remove_from_right]
elif height_to_remove_from_bottom > 0:
# 只裁剪高度
cropped_or_padded_tensor = padded_tensor[:, :, :-height_to_remove_from_bottom, :]
elif width_to_remove_from_right > 0:
# 只裁剪宽度
cropped_or_padded_tensor = padded_tensor[:, :, :, :-width_to_remove_from_right]
else:
# 不裁剪任何维度
cropped_or_padded_tensor = padded_tensor
return cropped_or_padded_tensor
在网络架构的forward方法中调用尺寸裁剪或尺寸填充函数:
# 对height裁剪一个像素,对width保持不变
crop_or_pad_tensor(up1_out, -1, 0)
# 对height保持不变,对width裁剪一个像素
crop_or_pad_tensor(up2_out, 0, -1)
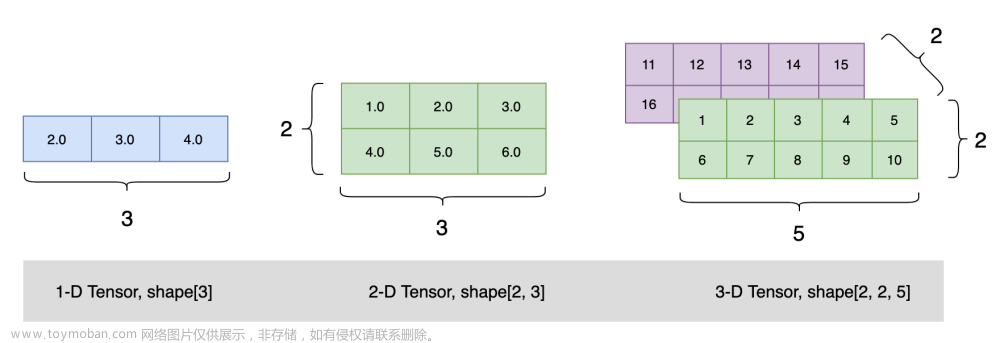
在深度学习中,一个四维张量(Tensor)通常代表的是批量图像数据,其维度排列通常是[batch_size, channels, height, width]
也就是Batch Size(批大小)、Channels(通道数)、Height(高度)、Width(宽度)
本文只讨论因Tensor中的height和width对不齐问题,batch_size和Channels比较基础,就不提及了。
同样的,五维张量相比四维张量多了一个深度(depth)
batch_size:同上,仍然是样本的数量。
channels:每个样本在同一时间点上的通道数。
depth 或 time_steps:对于视频数据,这是帧的数量;对于3D图像,则是深度层次。
height:每一帧或3D体素的高度。
width:每一帧或3D体素的宽度。文章来源:https://www.toymoban.com/news/detail-787741.html
定义五维张量的尺寸裁剪或尺寸填充函数:
可以通过修改pad_value来决定用什么数值来填充(建议修改成背景的数值)文章来源地址https://www.toymoban.com/news/detail-787741.html
import torch.nn.functional as F
def crop_or_pad_tensor_by_depth_height_width(tensor, depth_crop, height_crop, width_crop, pad_value=0):
'''
裁剪或扩展Tensor在深度(仅最后一个)、高度(仅底部)和宽度(仅右侧)维度上的最后一个像素。
正数表示扩展(用0填充),负数表示裁剪。
参数:
tensor (torch.Tensor): 输入的5维张量,形状为 (batch_size, channels, depth, height, width)
depth_crop (int): 深度方向上最后一个要裁剪或扩展的数量,默认为1
height_crop (int): 高度方向上底部要裁剪或扩展的像素数量,默认为1
width_crop (int): 宽度方向上右侧要裁剪或扩展的像素数量,默认为1
pad_value (float or int): 填充时使用的值,默认为0
返回:
cropped_or_padded_tensor (torch.Tensor): 裁剪或扩展后的张量
'''
assert len(tensor.shape) == 5, '输入的tensor应为5维'
# 获取原始的深度、高度和宽度
original_depth, original_height, original_width = tensor.shape[2], tensor.shape[3], tensor.shape[4]
# 计算需要裁剪的数量(正值代表不裁剪,负值时代表裁剪)
depth_to_remove_from_end = min(original_depth, -depth_crop) if depth_crop < 0 else 0
height_to_remove_from_bottom = min(original_height, -height_crop) if height_crop < 0 else 0
width_to_remove_from_right = min(original_width, -width_crop) if width_crop < 0 else 0
# 计算需要填充的数量(正值代表填充,负值代表不填充)
pad_depth = abs(depth_crop) if depth_crop > 0 else 0
pad_bottom = abs(height_crop) if height_crop > 0 else 0
pad_right = abs(width_crop) if width_crop > 0 else 0
# 先填充,再裁剪
padded_tensor = F.pad(tensor, pad=(0, pad_right, 0, pad_bottom, 0, pad_depth), mode='constant', value=pad_value)
# 在深度、高度和宽度维度上进行裁剪(如果需要)
if depth_to_remove_from_end > 0 and height_to_remove_from_bottom > 0 and width_to_remove_from_right > 0:
# 同时裁剪深度、高度和宽度
cropped_or_padded_tensor = padded_tensor[:, :, :-depth_to_remove_from_end, :-height_to_remove_from_bottom,
:-width_to_remove_from_right]
elif depth_to_remove_from_end > 0 and height_to_remove_from_bottom > 0:
# 只裁剪深度和高度
cropped_or_padded_tensor = padded_tensor[:, :, :-depth_to_remove_from_end, :-height_to_remove_from_bottom, :]
elif depth_to_remove_from_end > 0 and width_to_remove_from_right > 0:
# 只裁剪深度和宽度
cropped_or_padded_tensor = padded_tensor[:, :, :-depth_to_remove_from_end, :, :-width_to_remove_from_right]
elif height_to_remove_from_bottom > 0 and width_to_remove_from_right > 0:
# 只裁剪高度和宽度
cropped_or_padded_tensor = padded_tensor[:, :, :, :-height_to_remove_from_bottom, :-width_to_remove_from_right]
elif depth_to_remove_from_end > 0:
# 只裁剪深度
cropped_or_padded_tensor = padded_tensor[:, :, :-depth_to_remove_from_end, :, :]
elif height_to_remove_from_bottom > 0:
# 只裁剪高度
cropped_or_padded_tensor = padded_tensor[:, :, :, :-height_to_remove_from_bottom, :]
elif width_to_remove_from_right > 0:
# 只裁剪宽度
cropped_or_padded_tensor = padded_tensor[:, :, :, :, :-width_to_remove_from_right]
else:
# 不裁剪任何维度
cropped_or_padded_tensor = padded_tensor
return cropped_or_padded_tensor
到了这里,关于张量(Tensor)维度尺寸对不齐(Expected size xx but got size xx for tensor)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!