文件系统是我们常见的存储形式,内部主要由数据和元数据两部分组成。其中数据是文件的具体内容,通常会直接展现给用户;而元数据是描述数据的数据,用来记录文件属性、目录结构、数据存储位置等。一般来说,元数据有非常鲜明的特点,即占用空间较小,但访问非常频繁。
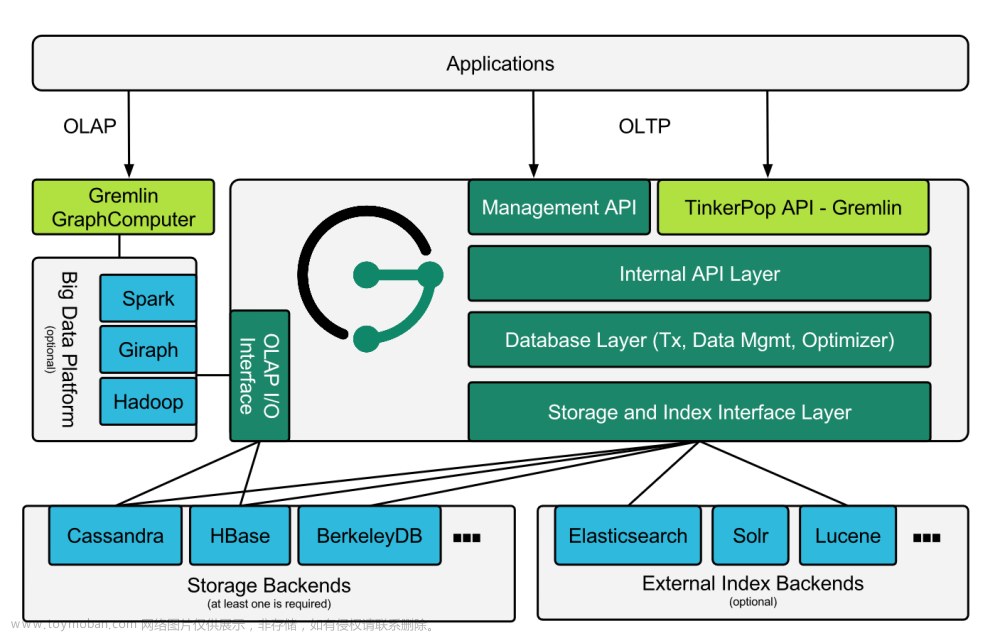
当今的分布式文件系统中,有的(如 S3FS)会将元数据和数据统一管理,以简化系统设计,不过这样的弊端是某些元数据操作会让用户感受到明显的卡顿,如 ls 大目录,重命名大文件等。更多的文件系统会选择将这两者分开管理,并根据元数据的特点进行针对性优化。JuiceFS 采用的就是这种设计,其架构图如下:

其中,元数据引擎需要是能够支持事务操作的数据库,而数据引擎一般是用对象存储。目前为止,JuiceFS 已经支持 10 种以上元数据引擎和 30 种以上数据引擎。
用户在使用 JuiceFS 时可以自由地选择成熟组件来充当这两个引擎,以应对丰富多变的企业环境和数据存储需求。然而对于新用户来说,当面对更多选择时,也带来了一个问题:在我的场景中究竟选择哪一款数据库作为元数据引擎比较合适?这篇文章将从产品设计角度,为大家介绍 JuiceFS 可使用的元数据引擎类型,以及他们的优劣势。
01-JuiceFS 元数据引擎类型
JuiceFS 现在支持的元数据引擎总共有有三大类。
第一个是 Redis。Redis 是 JuiceFS 开源后最早支持的元数据引擎。首先 Redis 速度够快,这是元数据引擎需要具备的重要能力之一;其次,Redis 受众面广,大部分用户对 Redis 都有实践经验。JuiceFS 对兼容 Redis 协议的数据库也都实现了支持,比如 KeyDB、Amazon MemoryDB 等。
然而,Redis 的可靠性和扩展性容易受限,在一些数据安全性要求较高或规模较大的场景中表现乏善可陈,因此我们又开发支持了另外两类引擎。
第二个是 SQL 类。如 MySQL、MariaDB、PostgreSQL 等,它们的特点是流行度较高,且通常具有不错的可靠性与扩展性。另外,还支持了嵌入式数据库 SQLite。
最后一个是 TKV(Transactional Key-Value Database)类。它们的原生接口比较简单,因此在 JuiceFS 中的定制性更好,相较于 SQL 类一般也能有更高的性能。目前这一类支持的有 TiKV、etcd 和嵌入式的 BadgerDB 等,对 FoundationDB 的支持也在紧锣密鼓地开发中。
以上是根据 JuiceFS 在对接数据库时的协议接口进行的分类。每个大类里面有各种不同的数据库,每种数据库又有其自身的特点,以下根据这些特点对用户常用的几个选项进行比较。
元数据引擎比较
| Redis | MySQL/PostgreSQL | TiKV | etcd | SQLite/BadgerDB | |
|---|---|---|---|---|---|
| 性能 | 高 | 低 | 中 | 低 | 中 |
| 扩展性 | 低 | 中 | 高 | 低 | 低 |
| 可靠性 | 低 | 高 | 高 | 高 | 中 |
| 可用性 | 中 | 高 | 高 | 高 | 低 |
| 流行度 | 高 | 高 | 中 | 高 | 中 |
如上文中提到的,Redis 的最大优势是性能高,因为它是全内存的数据库。其他几方面它就表现平平。
从扩展性上说,通常单机 Redis 可以支持 1 亿文件左右,超过 1 亿时,Redis 单进程的内存使用量会比较大,管理性能上也会有所下降。开源版 Redis 支持以集群模式来扩展其可管理的数据总量,但由于集群模式下 Redis 并不支持分布式事务,因此作为 JuiceFS 元数据引擎时,每个 JuiceFS volume 能用的 Redis 进程还是只有一个,单 volume 的扩展性相较于单机 Redis 并没有太大提升。
从可靠性来看,Redis 默认每秒将数据刷盘,在异常时可能导致小部分数据丢失。通过将配置 appendfsync 改为 always,可以让 Redis 在每个写请求后都刷盘,这样数据可靠性能提高,但是性能却会下降。
从可用性来说,部署 Redis 哨兵监控节点和备用节点,可以在主 Redis 节点挂掉后选择一个备份节点来重新提供服务,一定程度上提高可用性。然而,Redis 本身并不支持分布式的一致性协议,其备用节点采用的是异步备份,所以虽然新的节点起来了,但是中间可能会有数据差,导致新起来的数据并不是那么的完整。
MySQL 和 PostgreSQL 的整体表现比较类似。它们都是经过大量用户多年时间验证过的数据库产品,可靠性和可用性都不错,流行度也很高。只是相较于其余元数据引擎,它们的性能一般。
TiKV 原本是 PingCAP TiDB 的底层存储,现在已经分离出来,成为一个独立的 KV 数据库组件。从我们的测试结果来看,它用来作为 JuiceFS 的元数据引擎是一个非常出色的选择。其本身就有不弱于 MySQL 的数据可靠性和服务可用性,而且在性能与扩展性上表现更好。只是在流行度上,它和 MySQL 还有差距。从我们与用户交流来看,如果他们已经是 TiKV 或 TiDB 的用户,那最后通常都会偏向使用 TiKV 来做 JuiceFS 的元数据引擎。但如果他们之前对 TiKV 并不熟悉,那要再接受这样一个新的组件就会慎重许多。
etcd 是另一个 TKV 类的数据库。支持 etcd 的原因是因为它在容器化场景中流行度非常高,基本上 k8s 都是用 etcd 来管理它的配置。使用 etcd 作为 JuiceFS 的元数据引擎,并不是一个特别适配的场景。一方面是它的性能一般,另一方面是它有容量限制(默认 2G,最大 8G),之后就难以扩容。但是它的可靠性和可用性都非常高,而且容器化场景中也很容易部署,因此如果用户只需要一个规模在百万文件级别的文件系统,etcd 依然是一个不错的选择。
最后是 SQLite 和 BadgerDB,它们分别属于 SQL 类和 TKV 类,但使用起来体验却非常类似,因为它们都是单机版的嵌入式数据库。这类数据库的特点是性能中等,但扩展性和可用性都比较差,因为其数据其实就存放在本地系统中。它们的优势在于非常易用,只需要 JuiceFS 自己的二进制文件,不需要任何额外组件。用户在某些特定场景或者进行一些简单功能测试时,可以使用这两个数据库。
02- 典型引擎的性能测试结果
我们做过一些典型引擎的性能测试,并将其结果记录在这个文档中。其中一份从源码接口处测试的最直接结果大致为:Redis > TiKV(3 副本)> MySQL(本地)~= etcd(3 副本),具体如下:
| Redis-Always | Redis-Everysec | TiKV | MySQL | etcd | |
|---|---|---|---|---|---|
| mkdir | 600 | 471 (0.8) | 1614 (2.7) | 2121 (3.5) | 2203 (3.7) |
| mvdir | 878 | 756 (0.9) | 1854 (2.1) | 3372 (3.8) | 3000 (3.4) |
| rmdir | 785 | 673 (0.9) | 2097 (2.7) | 3065 (3.9) | 3634 (4.6) |
| readdir_10 | 302 | 303 (1.0) | 1232 (4.1) | 1011 (3.3) | 2171 (7.2) |
| readdir_1k | 1668 | 1838 (1.1) | 6682 (4.0) | 16824 (10.1) | 17470 (10.5) |
| mknod | 584 | 498 (0.9) | 1561 (2.7) | 2117 (3.6) | 2232 (3.8) |
| create | 591 | 468 (0.8) | 1565 (2.6) | 2120 (3.6) | 2206 (3.7) |
| rename | 860 | 736 (0.9) | 1799 (2.1) | 3391 (3.9) | 2941 (3.4) |
| unlink | 709 | 580 (0.8) | 1881 (2.7) | 3052 (4.3) | 3080 (4.3) |
| lookup | 99 | 97 (1.0) | 731 (7.4) | 423 (4.3) | 1286 (13.0) |
| getattr | 91 | 89 (1.0) | 371 (4.1) | 343 (3.8) | 661 (7.3) |
| setattr | 501 | 357 (0.7) | 1358 (2.7) | 1258 (2.5) | 1480 (3.0) |
| access | 90 | 89 (1.0) | 370 (4.1) | 348 (3.9) | 646 (7.2) |
| setxattr | 404 | 270 (0.7) | 1116 (2.8) | 1152 (2.9) | 757 (1.9) |
| getxattr | 91 | 89 (1.0) | 365 (4.0) | 298 (3.3) | 655 (7.2) |
| removexattr | 219 | 95 (0.4) | 1554 (7.1) | 882 (4.0) | 1461 (6.7) |
| listxattr_1 | 88 | 88 (1.0) | 374 (4.2) | 312 (3.5) | 658 (7.5) |
| listxattr_10 | 94 | 91 (1.0) | 390 (4.1) | 397 (4.2) | 694 (7.4) |
| link | 605 | 461 (0.8) | 1627 (2.7) | 2436 (4.0) | 2237 (3.7) |
| symlink | 602 | 465 (0.8) | 1633 (2.7) | 2394 (4.0) | 2244 (3.7) |
| write | 613 | 371 (0.6) | 1905 (3.1) | 2565 (4.2) | 2350 (3.8) |
| read_1 | 0 | 0 (0.0) | 0 (0.0) | 0 (0.0) | 0 (0.0) |
| read_10 | 0 | 0 (0.0) | 0 (0.0) | 0 (0.0) | 0 (0.0) |
- 上表中记录的是每一个操作的耗时,数值越小越好;括号内数字是该指标对比 Redis-always 的倍数,数值也是越小越好
- Always 和 Everysec 是 Redis 配置项 appendfsync 的可选值,分别表示每个请求都刷盘和每秒刷一次盘
- 可以看到,Redis 在使用 everysec 的时候,性能更好,但与 always 相差的并不大;这是因为测试用的 AWS 机器上的本地 SSD 盘本身 IOPS 性能就比较高
- TiKV 和 etcd 都使用了三副本,而 MySQL 是单机部署的。即使这样,TiKV 的性能表现还是高于 MySQL,而 etcd 与 MySQL 接近。
值得一提的是,上文中的测试使用的都是默认配置,并没有对各个元数据引擎去做特定的调优。用户在使用时可以根据自己的需求和实践经验进行配置调整,可能会有不一样的结果。
另一份测试是通过 JuiceFS 自带的 bench 工具跑的,其运行的是操作系统读写文件的接口,具体结果如下:
| Redis-Always | Redis-Everysec | TiKV | MySQL | etcd | |
|---|---|---|---|---|---|
| Write big file | 565.07 MiB/s | 556.92 MiB/s | 553.58 MiB/s | 557.93 MiB/s | 542.93 MiB/s |
| Read big file | 664.82 MiB/s | 652.18 MiB/s | 679.07 MiB/s | 673.55 MiB/s | 672.91 MiB/s |
| Write small file | 102.30 files/s | 105.80 files/s | 95.00 files/s | 87.20 files/s | 95.75 files/s |
| Read small file | 2200.30 files/s | 1894.45 files/s | 1394.90 files/s | 1360.85 files/s | 1017.30 files/s |
| Stat file | 11607.40 files/s | 15032.90 files/s | 3283.20 files/s | 5470.05 files/s | 2827.80 files/s |
| FUSE operation | 0.41 ms/op | 0.42 ms/op | 0.45 ms/op | 0.46 ms/op | 0.42 ms/op |
| Update meta | 3.63 ms/op | 3.19 ms/op | 7.04 ms/op | 8.91 ms/op | 4.46 ms/op |
从上表可以看到,读写大文件时使用不同的元数据引擎最后性能是差不多的。这是因为此时性能瓶颈主要在对象存储的数据读写上,元数据引擎之间虽然时延有点差异,但是放到整个业务读写的消耗上,这点差异几乎可以忽略不计。当然,如果对象存储变得非常快(比如都用本地全闪部署),那么元数据引擎的性能差异可能又会体现出来。另外,对于一些纯元数据操作(比如 ls,创建空文件等),不同元数据引擎的性能差别也会表现的比较明显。
03-引擎选型的考虑要素
根据上文介绍的各引擎特点,用户可以根据自己的情况去选择合适的引擎。以下简单分享下我们在做推荐时会建议用户考虑的几个要素。
评估需求:比如想使用 Redis,需要先评估能否接受少量的数据丢失,短期的服务中断等。如果是存储一些临时数据或者中间数据的场景,那么用 Redis 确实是不错的选择,因为它性能够好,即使有少量的数据丢失,也不会造成很大的影响。但如果是要存储一些关键数据, Redis 就不适用了。另外还得评估预期数据的规模,如果在 1 亿文件左右, Redis 可以承受;如果预期会有 10 亿文件,那么显然单机 Redis 是难以承载的。
评估硬件:比如能否连通外网,是使用托管的云服务,还是在自己机房内私有部署。如果是私有部署,需要评估是否有足够的硬件资源去部署一些相关的组件。无论是用哪一种元数据引擎,基本上都要求有高速的 SSD 盘去运行,不然会对其性能有比较大的影响。
评估运维能力,这是很多人会忽视的,但是在我们来看这应该是最关键的因素之一。对于存储系统来说,稳定性往往才是其上生产后的第一重点。用户在选择元数据引擎的时候,应该先想想自己对它是不是熟悉,在出现问题时,能否快速定位解决;团队内是否有足够的经验或精力去把控好这个组件。通常来说,我们会建议用户在开始时选择一个自己熟悉的数据库是比较合适的。如果运维人员不足,那么选择 JuiceFS 公有云服务也确实是个省心的选项。
最后,分享下社区在使用元数据引擎方面的一些统计数据。
- 目前为止, Redis 的使用者依然占了一半以上,其次是 TiKV 和 MySQL,这两类的使用者的数量占比在逐步增长。
- 在运行的 Redis 集群的最大文件数大概是在 1.5 亿,而且运行情况是比较稳定的,上文提到的推荐的 1 亿文件是建议值,并不是说无法超过 1 亿。
- 整体数量规模 Top3,都是使用的 TiKV 而且都超过了 10 亿文件数量。现在最大的文件系统的文件数量是超了 70 亿文件,总容量超过了 15 PiB,这也从侧面证明了 TiKV 在作为元数据引擎时的扩展能力。我们自己内部测过使用 TiKV 作为元数据引擎存储 100 亿文件,系统仍能稳定地运行。所以如果你的整个集群预期的规模会非常大,那么TiKV 确实是一个很好的选择。
04- 元数引擎迁移
文章的最后,为大家介绍元数据引擎迁移。 随着用户业务的发展,企业对元数据引擎的需求会发生变化,当用户发现现有的元数据引擎不合适了,可以考虑将元数据迁移到另一个引擎中。 我们为用户提供了完整的迁移方法,具体可以参考这个文档。
这个迁移方法有一定的限制,首先只能迁移到空数据库,暂时无法将两个文件系统直接合在一起;其次,需要停写,因为数据量会比较大的情况下,很难在线将元数据完整的迁移过来。要做到这点需要加许多限制,从实测来看速度会非常慢。因此,把整个文件系统停掉再去做迁移是最稳妥的。如果说实在需要有一定的服务提供,可以保留只读挂载,用户读数据并不会影响整个元数据引擎迁移的动作。
虽然社区提供了全套的迁移方法,但是还是需要提醒用户,尽量提前对数据量的增长做好规划,尽量不做迁移或尽早迁移。当要迁移的数据规模很大时,耗时也会变长,期间出问题的概率也会变大。文章来源:https://www.toymoban.com/news/detail-787846.html
如有帮助的话欢迎关注我们项目 Juicedata/JuiceFS 哟! (0ᴗ0✿)文章来源地址https://www.toymoban.com/news/detail-787846.html
到了这里,关于JuiceFS 元数据引擎选型指南的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!