- SqlAlchemy使用教程(一) 原理与环境搭建
- SqlAlchemy使用教程(二) 入门示例及编程步骤
- SqlAlchemy使用教程(三) CoreAPI访问与操作数据库详解
- SqlAlchemy使用教程(四) MetaData 与 SQL Express Language 的使用
- SqlAlchemy使用教程(五) ORM API 编程入门
三、使用Core API访问与操作数据库
Sqlalchemy 的Core部分集成了DB API, 事务管理,schema描述等功能,ORM构筑于其上。本章介绍创建 Engine对象,使用基本的 Sql Express Language 方法,以及如何实现对数据库的CRUD操作等内容。
1、创建DB engine 对象
1.1创建database engine 对象
Engine 是db连接管理类,
语法:
from sqlalchemy import create_engine
#创建引擎对象
engine = create_engine("sqlite:///:memory:", echo=True)
#连接数据库
conn = engine.connect()
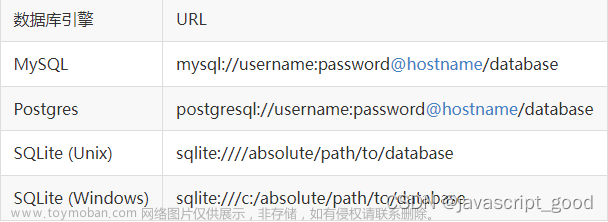
Sqlalchemy.create_engine( ) 方法第1个参数是db连接表达式,格式为:
dialect[+driver]://user:password@host/dbname
- dialect 通常为数据库类型,如sqlite, mysql, mongodb, etc.
- driver 是python 访问数据库的包。
如 sqlite+sqlite3, mysql+mysqlconnector
1.2 连接至各类数据库的配置
1.2.1 sqlite 连接
上面示例是sqlite的连接表达式。 Driver是python访问数据库的DBAPI库。
e = create_engine('sqlite:///path/to/database.db')
如果是绝对地址 sqlite:usr/local/myproject/database.db
:memory 表示使用内存数据库,不保存在硬盘。
对于windows 系统,
e = create_engine('sqlite:///C:\\myapp\\db\\main.db')
1.2.2 连接mysql
Mysql 的DBAPI,常用的有PyMysql 与 mysql-connector,其连接表达式分别为:
mysql+pymysql://root:123456@192.168.99.240:3306/testdb
mysql+mysqlconnector://roprot:123456@192.168.99.240:3306/testdb
1.2.3 连接PostgreSQL
通常使用的接口库为 psycopg2
postgresql+psycopg2://user:password@host:port/dbname[?key=value&key=value...]
engine = create_engine(
"postgresql+psycopg2://scott:tiger@localhost/test",
isolation_level="SERIALIZABLE",
)
Ssl连接
engine = sa.create_engine(
"postgresql+psycopg2://scott:tiger@192.168.0.199:5432/test?sslmode=require"
)
1.2.4 连接MongoDB
engine = create_engine("mongodb:///?Server=MyServer&Port=27017&Database=test&User=test&Password=Password")
定义1个mapping类
base = declarative_base()
class restaurants(base):
__tablename__ = "restaurants"
borough = Column(String,primary_key=True)
cuisine = Column(String)
查询:
engine=create_engine("mongodb:///?Server=MyServer&Port=27017&Database=test&User=test&Password=Password")
factory = sessionmaker(bind=engine)
session = factory()
for instance in session.query(restaurants).filter_by(Name="Morris Park Bake Shop"):
print("borough: ", instance.borough)
print("cuisine: ", instance.cuisine)
print("---------")
1.3创建connect 对象
语法:
conn = engine.connect()
如
e = create_engine('sqlite:///C:\\myapp\\db\\main.db')
conn = e.connect()
推荐使用context with 语法使用connect对象
from sqlalchemy import create_engine, text
engine = create_engine('sqlite:///C:\\myapp\\db\\main.db')
with engine.connect() as connection:
result = connection.execute(text("select username from users"))
for row in result:
print("username:", row["username"])
如果修改了数据,应调用 conn.commit() 提交transaction
2. SQL Express Language SQL表达式常用方法
Sqlalchemy SQL Express Language是对SQL的封装,在传参、获取返回值等方面更加方便。
2.1 使用 text() 生成SQL Express语句
text()方法是CoreAPI中最基础的方法之一,主要作用,用于封装 sql 语句
from sqlalchemy import text
t_sql = text("SELECT * FROM users")
result = connection.execute(t_sql)
传参:
t_sql = text("SELECT * FROM users WHERE id=:user_id")
result = connection.execute(t_sql, { ‘user_id’: 12 } )
如果使用r” “ ,则用 : 来表示:
2.2 用 bindparams() 方法传参
也可以通过 text(sql_statement).bindparams() 直接构建完整的SQL语句
from sqlalchemy import text, bindparams
stmt = text("SELECT id, name FROM user WHERE name=:name "
"AND timestamp=:timestamp")
stmt = stmt.bindparams(name='jack',
timestamp=datetime.datetime(2012, 10, 8, 15, 12, 5)
)
result = conn.execute(stmt)
print(result.all())
bindparams()中可添加参数Type检查:
from sqlalchemy import text
stmt = text("SELECT id, name FROM user WHERE name=:name "
"AND timestamp=:timestamp")
stmt = stmt.bindparams(
bindparam('name', type_=String),
bindparam('timestamp', type_=DateTime)
)
stmt = stmt.bindparams(name='jack',
timestamp=datetime.datetime(2012, 10, 8, 15, 12, 5))
result = conn.execute(stmt)
print(result.all())
3, 解析查询结果
查询结果类型为 sqlalchemy.engine.Result 类,是1个由 object 组成的列表。可以用多种方法访问:
- all() , return all rows in a list
- columns(‘col_1’, ‘col_2’) 指定返回每row 的字段, iterable
- fetchall(), fetchone(), fetchmany()
- first() 返回第1行。
- keys() 返回row的字段名, 是iterable 类型
- mappings(), 列表元素为dict类型,
- result.close() 关闭result对象
说明:
- 遍历查询结果, all()- , fetchall(), fetchmany(), columns(), 结果为: list[tuple,…], 或iterable,
- 对row 字段, 可以用key, index , row[0], row[‘id’], row[‘name’], 也可以用row.name , 如
result = conn.execute(text("select x, y from some_table"))
for row in result:
print(f"Row: {row.x} {row.y}")
- result.mapping() 返回结果的row 类型为dict,
result = conn.execute(text("select x, y from some_table"))
for dict_row in result.mappings():
x = dict_row["x"]
y = dict_row["y"]
4. 使用connect 对象执行CRUD操作
SqlAlchemy可以用connect对象与 session 对象来执行SQL express
connect对象是直接调用DBAPI执行SQL语句,这是使用SqlAlchemy 最简单的方式,同时支持部分Sqlalchemy 的SQL Express 封装语法,但执行的SQL语句依然还要符合各数据库的接口库要求。
Session对象则实现了同1套接口适用于所有数据库。但主要用于ORM API方式。
connect对象操作数据库的好处:可使用text()方法生成SQL语句,利用bindparams() 传值,以及做类型检查。同时支持多线程访问数据库。
创建表的方法,前面已讲过。 下面示例为 insert, update, delete 操作
# insert row
print("-"*50+"Insert operation")
stmt = text("INSERT INTO some_table VALUES(:x, :y)").bindparams(x=6,y=19)
with engine.connect() as conn:
conn.execute(stmt)
conn.commit()
result = conn.execute( text("select * from some_table") )
print(result.all())
# update row
print("-"*50+"update operation")
stmt = text("UPDATE some_table SET y=:y WHERE x=:x").bindparams(y=99,x=5)
with engine.connect() as conn:
conn.execute(stmt)
conn.commit()
result = conn.execute( text("select * from some_table") )
print(result.all())
# delete row
print("-"*50+"delete operation")
stmt = text("DELETE FROM some_table WHERE x=:x").bindparams(x=4)
with engine.connect() as conn:
conn.execute(stmt)
conn.commit()
result = conn.execute( text("select * from some_table") )
print(result.rowcount)
print(result.all())
output:
--------------------------------------------------Insert operation
2023-12-03 15:50:36,978 INFO sqlalchemy.engine.Engine BEGIN (implicit)
2023-12-03 15:50:36,978 INFO sqlalchemy.engine.Engine INSERT INTO some_table VALUES(?, ?)
2023-12-03 15:50:36,978 INFO sqlalchemy.engine.Engine [generated in 0.00085s] (6, 19)
2023-12-03 15:50:36,979 INFO sqlalchemy.engine.Engine COMMIT
2023-12-03 15:50:36,980 INFO sqlalchemy.engine.Engine BEGIN (implicit)
2023-12-03 15:50:36,980 INFO sqlalchemy.engine.Engine select * from some_table
2023-12-03 15:50:36,981 INFO sqlalchemy.engine.Engine [generated in 0.00132s] ()
[(1, 1), (2, 4), (3, 10), (4, 11), (5, 25), (6, 19)]
2023-12-03 15:50:36,982 INFO sqlalchemy.engine.Engine ROLLBACK
--------------------------------------------------update operation
[(1, 1), (2, 4), (3, 10), (4, 11), (5, 99), (6, 19)]
2023-12-03 15:50:36,985 INFO sqlalchemy.engine.Engine ROLLBACK
--------------------------------------------------delete operation
[(1, 1), (2, 4), (3, 10), (5, 99), (6, 19)]
2023-12-03 15:50:36,989 INFO sqlalchemy.engine.Engine ROLLBACK
5. 表间关系处理
Sqlalchemy 使用DBAPI处理表间关系语法是依据数据库规定, 但基本均支持标准SQL语法
5.1 创建外键字段的语法:
CREATE TABLE tracks(
……
trackartist INTEGER, -- 外键字段
FOREIGN KEY(trackartist) REFERENCES artist(artistid)
)
辅表artist.id字段须为主键或unique index。
5.2 各种表间关系的实现方式:
- One to one: 还是用 foreign key来实现。
- One to many: 就是外键
- Many to many: 需要中间表, 用2个foreign key 与两张表分别建立 one to many 关系。
示例 :
import sqlalchemy
from sqlalchemy import create_engine
from sqlalchemy import text
from sqlalchemy.orm import sessionmaker
engine = create_engine("sqlite:///order.db")
# create table people
with engine.connect() as conn:
conn.execute(text("drop table if exists people;"))
stmt = text("""
CREATE TABLE people(
id integer PRIMARY KEY,
name TEXT,
age INTEGER
)
""" )
conn.execute(stmt)
conn.execute(
text("INSERT INTO people (id,name, age) VALUES (:id,:name, :age)"),
[
{'id': 1, "name": 'Jack','age':30 },
{'id': 2, "name": 'Smith','age':28 },
{'id': 3, "name": 'Wang','age':35 },
]
)
conn.commit()
result = conn.execute( text("select * from people") )
print(result.rowcount)
print(result.all())
# create table order
# 创建会话(Session)
with engine.connect() as conn:
conn.execute(text("drop table if exists teams"))
stmt_1 = text("""
create table teams(
id integer PRIMARY KEY,
team_name TEXT,
pid integer,
foreign key (pid) REFERENCES people(id)
)
""")
conn.execute(stmt_1)
conn.commit()
conn.execute(
text("INSERT INTO teams (id, team_name, pid) VALUES (:id, :team_name, :pid)"),
[
{'id': 101, "team_name": 'TV product','pid':1 },
{'id': 102, "team_name": 'Software development','pid':2 },
{'id': 103, "team_name": 'Electric development','pid':2 },
]
)
conn.commit()
# 跨表查询
result = conn.execute( text("select a.id, a.team_name, b.name from teams as a left join people as b on a.pid=b.id") )
print(result.rowcount)
for row in result.mappings():
print(row['id'], row['team_name'], row['name'])
6. 通过多线程访问Database
sqlalchemy的engine可做为全局变量, 将connect对象,或 session对象传入线程,实现多线程访问:
示例:
def thread_db(conn,name):
try:
result = conn.execute( text("select * from people") )
print(result.rowcount)
print(f"thread {{ name }} result: ")
print(result.all())
except Exception as e:
print("can't open connection object")
finally:
conn.close()
from threading import Thread
t1 = Thread(target=thread_db, args=(engine.connect(),"thread_a"))
t2 = Thread(target=thread_db, args=(engine.connect(),"thread_b"))
t1.start()
t2.start()
t1.join()
t2.join()
print("main thread is ended")
output:
thread { name } result:
thread { name } result:
[(1, 'Jack', 30), (2, 'Smith', 28), (3, 'Wang', 35)]
[(1, 'Jack', 30), (2, 'Smith', 28), (3, 'Wang', 35)]
main thread is ended
7. 通过 select()方法查询数据
使用了 metadata的 Table对象后,字段放在 table_obj.c 数据结构中,引用方式:
table_obj.c.name, table_obj.c.email。
查询数据语句使用 select() 方法,以及 where(), order_by() 等子方法来实现。
在Core API中, select()语句的执行器是 engine.connect()方法。
select()方法也可以用于ORM, 但做了进一步封装,使用方式与Core层还是有所区别。
stmt = select(user_table).where(user_table.c.name == "Jack")
with engine.connect() as conn:
for row in conn.execute(stmt):
print(row)
选择数据库字段
默认select(user_table) 选择了所有字段,可以指定字段返回。
select(user_table.c.name, user_table.c.fullname)
多表联合查询,
conn.execute(
select(User, Address).where(User.c.id == Address.c.user_id).order_by(Address.c.id)
)
多条件where子句链式调用
select(address_table.c.email_address)
.where(user_table.c.name == "squidward")
.where(address_table.c.user_id == user_table.c.id)
多条件逻辑关系使用 and_(), or_() 方法
from sqlalchemy import and_, or_
print(
select(Address.email_address).where(
and_(
or_(User.name == "squidward", User.name == "sandy"),
Address.user_id == User.id,
)
)
)
使用 Select.filter_by() 方法查询
select(User).filter_by(name="Jack", fullname="Jack Smith")
使用 select.join_from()方法进行联合查询, 支持左联与右联, ON 字段是自动推断。
select(user_table.c.name, address_table.c.email_address).join_from(
user_table, address_table)
select.join() 只支持右联查询
select(user_table.c.name, address_table.c.email_address).join(address_table)
手工设置ON字段
select(address_table.c.email_address)
.select_from(user_table)
.join(address_table, user_table.c.id == address_table.c.user_id)
相当于
SELECT address.email_address
FROM user_account JOIN address ON user_account.id = address.user_id
ORDER BY, GROUP BY, HAVING
order_by()方法示例文章来源:https://www.toymoban.com/news/detail-787997.html
select(user_table).order_by(user_table.c.name)
group_by() + having() 示例文章来源地址https://www.toymoban.com/news/detail-787997.html
with engine.connect() as conn:
result = conn.execute(
select(User.name, func.count(Address.id).label("count"))
.join(Address)
.group_by(User.name)
.having(func.count(Address.id) > 1)
)
print(result.all())
到了这里,关于SqlAlchemy使用教程(三) CoreAPI访问与操作数据库详解的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!