作者信息:
唐聪、王超凡,腾讯云原生产品中心技术专家,负责腾讯云大规模 TKE 集群和 etcd 控制面稳定性、性能和成本优化工作。
王子勇,腾讯云专家级工程师, 腾讯云计算产品技术服务专家团队负责人。
概况
作为当前中国广泛使用的云视频会议产品,腾讯会议已服务超过 3 亿用户,能高并发支撑千万级用户同时开会。腾讯会议数百万核心服务都部署在腾讯云 TKE 上,通过全球多地域多集群部署实现高可用容灾。在去年用户使用最高峰期间,为了支撑更大规模的并发在线会议的人数,腾讯会议与 TKE 等各团队进行了一轮新的扩容。
然而,在这过程中,一个简单的 etcd 进程重启操作却触发了一个的诡异的 K8s 故障(不影响用户开会,影响新一轮后台扩容效率),本文介绍了我们是如何从问题现象、到问题分析、大胆猜测排除、再次复现、严谨验证、根治隐患的,从 Kubernetes 到 etcd 底层原理,从 TCP RFC 草案再到内核 TCP/IP 协议栈实现,一步步定位并解决问题的详细流程(最终定位到是特殊场景触发了内核 Bug)。
希望通过本文,让大家对 etcd、Kubernetes 和内核的复杂问题定位有一个较为深入的了解,掌握相关方法论,同时也能让大家更好的了解和使用好 TKE,通过分享我们的故障处理过程,提升我们的透明度。
背景知识
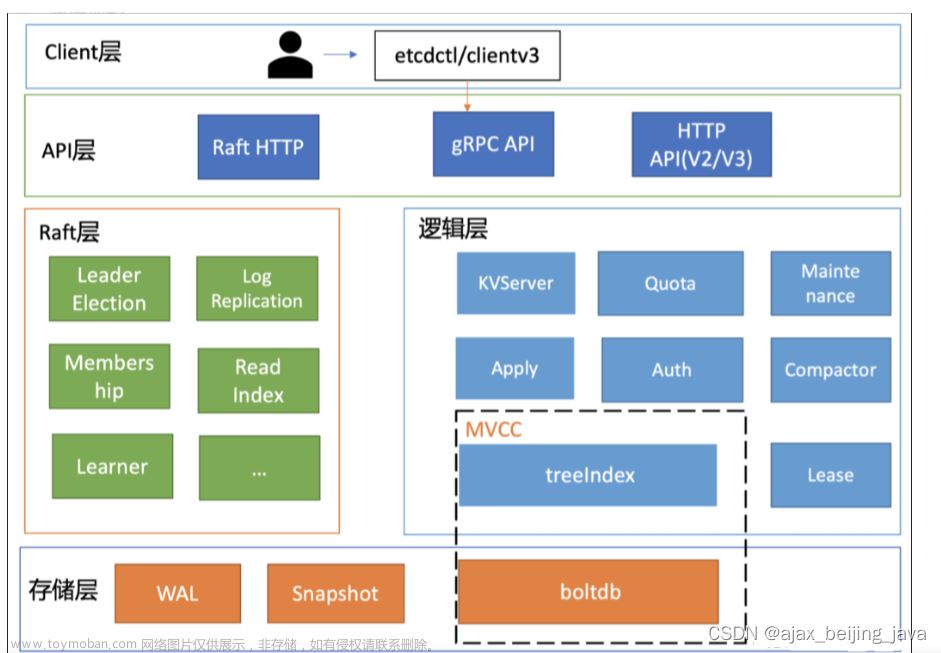
首先给大家简要介绍下腾讯会议的简要架构图和其使用的核心产品 TKE Serverless 架构图。
腾讯会议极简架构图如下:

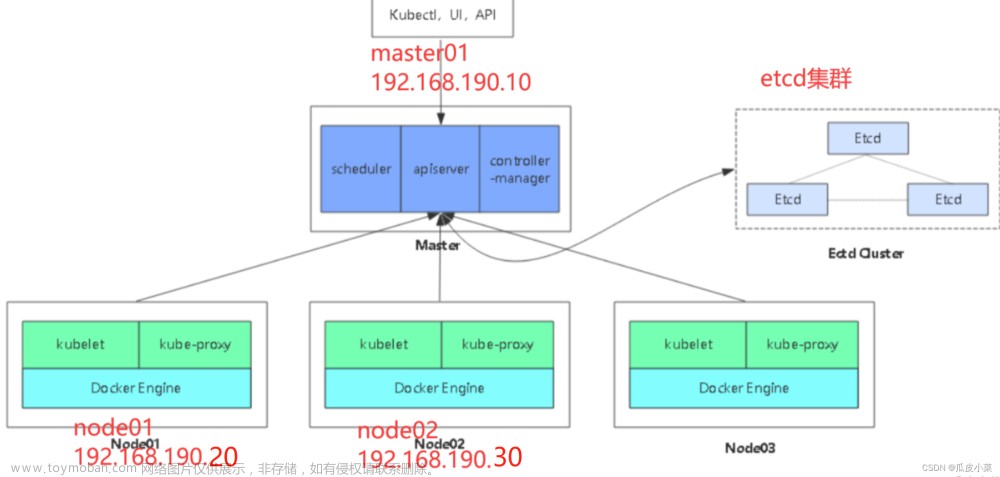
腾讯会议重度使用的 TKE Serverless 架构如下:

腾讯会议几乎全部业务都跑在 TKE Serverless 产品上,Master 组件部署在我们metacluster 中(K8s in K8s),超大集群可能有10多个 APIServer,etcd 由服务化的 etcd 平台提供,APIServer 访问 etcd 链路为 svc -> cluster-ip -> etcd endpoint。业务各个 Pod 独占一个轻量级的虚拟机,安全性、隔离性高,业务无需关心任何 Kubernetes Master、Node 问题,只需要专注业务领域的开发即可。
问题现象
在一次资源扩容的过程中,腾讯会议的研发同学晚上突然在群里反馈他们上海一个最大集群出现了业务扩容失败,收到反馈后研发同学,第一时间查看后,还看到了如下异常:
● 部分 Pod 无法创建、销毁
● 某类资源 Get、list 都是超时
● 个别组件出现了 Leader Election 错误
● 大部分组件正常,少部分控制器组件有如下 list pvc 资源超时日志
k8s.io/client-go/informers/factory.go:134: Failed to watch
*v1.PersistentVolumeClaim: failed to list
*v1.PersistentVolumeClaim: the server was unable to return a
response in the time allotted, but may still be processing the
request (get persistentvolumeclaims)然而 APIServer 负载并不高,当时一线研发同学快速给出了一个控制面出现未知异常的结论。随后 TKE 团队快速进入攻艰模式,开始深入分析故障原因。
问题分析
研发团队首先查看了此集群相关变更记录,发现此集群在几个小时之前,进行了重启 etcd 操作。变更原因是此集群规模很大,在之前的多次扩容后,db size 使用率已经接近 80%,为了避免 etcd db 在业务新一轮扩容过程中被写满,因此系统进行了一个经过审批流程后的,一个常规的调大 etcd db quota 操作,并且变更后系统自检 etcd 核心指标正常。
我们首先分析了 etcd 的接口延时、带宽、watch 监控等指标,如下图所示, etcd P99 延时毛刺也就 500ms,节点带宽最大的是平均 100MB/s 左右,初步看并未发现任何异常。

随后又回到 APIServer,一个在请求在 APIServer 内部经历的各个核心阶段(如下图所示):

● 鉴权 (校验用户 token、证书是否正确)
● 审计
● 授权 (检查是否用户是否有权限访问对应资源)
● 限速模块 (1.20 后是优先级及公平管理)
● mutating webhook
● validating webhook
● storage/cache
● storage/etcd文章来源:https://www.toymoban.com/news/detail-788202.html
请求在发往 APIServer 前,client 可能导致请求慢的原因: ● client-go 限速,client-go 默认 qps 文章来源地址https://www.toymoban.com/news/detail-788202.html
到了这里,关于深度复盘-重启 etcd 引发的异常的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!